Demonstration-Guided Continual Reinforcement Learning in Dynamic Environments
作者: Xue Yang, Michael Schukat, Junlin Lu, Patrick Mannion, Karl Mason, Enda Howley
分类: cs.LG
发布日期: 2025-12-21
💡 一句话要点
提出DGCRL,利用自进化演示库指导动态环境下的持续强化学习,提升知识迁移和训练效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 持续强化学习 动态环境 演示学习 知识迁移 课程学习
📋 核心要点
- 现有持续强化学习方法在动态环境中难以平衡稳定性和可塑性,限制了知识的有效重用和高效学习。
- DGCRL通过维护一个自进化演示库,直接指导智能体的探索和适应,从而实现更有效的知识迁移。
- 实验表明,DGCRL在导航和运动控制任务中,显著提升了平均性能、知识迁移能力,并减轻了遗忘现象。
📝 摘要(中文)
强化学习在各种应用中表现出色,但在底层马尔可夫决策过程演变的动态环境中表现不佳。持续强化学习(CRL)使强化学习智能体能够持续学习并适应新任务,但平衡稳定性(保持先验知识)和可塑性(获取新知识)仍然具有挑战性。现有方法主要通过过去知识影响优化的机制来解决稳定性-可塑性困境,但很少直接影响智能体的行为,这可能会阻碍有效的知识重用和高效学习。相反,我们提出了演示引导的持续强化学习(DGCRL),它将先验知识存储在外部的、自我演化的演示库中,该库直接指导强化学习的探索和适应。对于每个任务,智能体动态地选择最相关的演示,并遵循基于课程的策略来加速学习,逐渐从演示引导的探索转变为完全的自我探索。在2D导航和MuJoCo运动任务上的大量实验表明,DGCRL具有优越的平均性能、增强的知识转移、减轻的遗忘和训练效率。额外的敏感性分析和消融研究进一步验证了其有效性。
🔬 方法详解
问题定义:论文旨在解决动态环境下持续强化学习中的稳定性-可塑性困境。现有方法主要通过优化算法层面的改进来保留先验知识,但很少直接影响智能体的行为策略,导致知识重用效率低下,学习速度慢。智能体难以在新任务上快速适应,并且容易遗忘先前学习的知识。
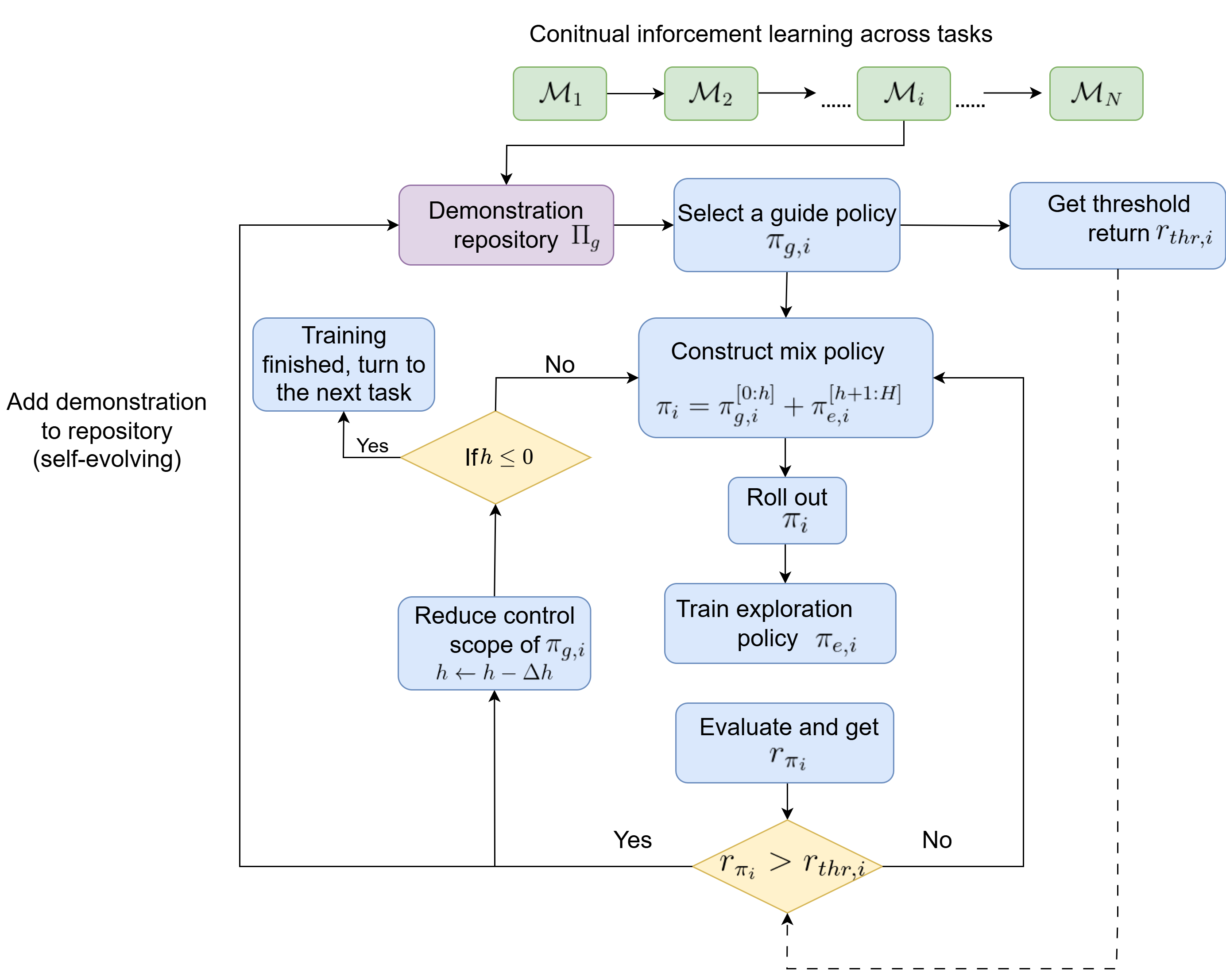
核心思路:论文的核心思路是利用外部的、自我演化的演示库来存储和重用先验知识。该演示库包含过去任务的成功经验,可以指导智能体在新的任务中进行探索和学习。通过动态选择最相关的演示,并结合课程学习策略,智能体可以逐步从模仿演示过渡到自主探索,从而加速学习过程并提高知识迁移能力。
技术框架:DGCRL的整体框架包含以下几个主要模块:1) 演示库:存储过去任务的成功经验,并随着新任务的到来不断更新和演化。2) 演示选择模块:根据当前任务的状态,从演示库中选择最相关的演示。3) 课程学习模块:根据学习进度,动态调整演示引导的比例,逐步从模仿演示过渡到自主探索。4) 强化学习智能体:基于选择的演示和课程学习策略,与环境进行交互,并更新自身的策略。
关键创新:DGCRL的关键创新在于使用外部演示库直接指导强化学习智能体的探索和适应。与现有方法相比,DGCRL不是仅仅在优化算法层面保留知识,而是通过演示库将知识显式地传递给智能体,从而更有效地重用知识,加速学习过程。此外,自进化演示库的设计使得DGCRL能够适应不断变化的环境,并持续学习新的知识。
关键设计:演示库的更新策略至关重要,需要平衡新知识的加入和旧知识的保留。课程学习策略的设计也需要仔细考虑,以确保智能体能够逐步从模仿演示过渡到自主探索,避免过度依赖演示。具体的参数设置,如演示选择的相似度度量、课程学习的比例调整等,都需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DGCRL在2D导航和MuJoCo运动任务中,相比于现有的持续强化学习方法,取得了显著的性能提升。例如,在平均奖励方面,DGCRL优于其他基线方法,并且能够更有效地减轻遗忘现象。消融研究进一步验证了演示库和课程学习策略的有效性。敏感性分析表明,DGCRL对参数变化具有一定的鲁棒性。
🎯 应用场景
DGCRL适用于需要在动态环境中持续学习和适应的机器人应用,例如自动驾驶、机器人导航、智能制造等。通过利用先验知识和演示指导,DGCRL可以帮助机器人在新的环境中快速学习和适应,提高其自主性和鲁棒性,降低开发和维护成本。此外,该方法还可以应用于游戏AI、推荐系统等领域。
📄 摘要(原文)
Reinforcement learning (RL) excels in various applications but struggles in dynamic environments where the underlying Markov decision process evolves. Continual reinforcement learning (CRL) enables RL agents to continually learn and adapt to new tasks, but balancing stability (preserving prior knowledge) and plasticity (acquiring new knowledge) remains challenging. Existing methods primarily address the stability-plasticity dilemma through mechanisms where past knowledge influences optimization but rarely affects the agent's behavior directly, which may hinder effective knowledge reuse and efficient learning. In contrast, we propose demonstration-guided continual reinforcement learning (DGCRL), which stores prior knowledge in an external, self-evolving demonstration repository that directly guides RL exploration and adaptation. For each task, the agent dynamically selects the most relevant demonstration and follows a curriculum-based strategy to accelerate learning, gradually shifting from demonstration-guided exploration to fully self-exploration. Extensive experiments on 2D navigation and MuJoCo locomotion tasks demonstrate its superior average performance, enhanced knowledge transfer, mitigation of forgetting, and training efficiency. The additional sensitivity analysis and ablation study further validate its effectiveness.