SD2AIL: Adversarial Imitation Learning from Synthetic Demonstrations via Diffusion Models
作者: Pengcheng Li, Qiang Fang, Tong Zhao, Yixing Lan, Xin Xu
分类: cs.LG, cs.RO
发布日期: 2025-12-21
🔗 代码/项目: GITHUB
💡 一句话要点
SD2AIL:利用扩散模型从合成演示中进行对抗模仿学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对抗模仿学习 扩散模型 合成数据 优先重放 强化学习
📋 核心要点
- 对抗模仿学习依赖大量专家演示,但实际场景中获取成本高昂或难以实现。
- SD2AIL利用扩散模型生成高质量的合成演示数据,扩充专家数据集,提升学习效果。
- 提出优先专家演示重放策略,从混合数据集中选择最有价值的样本,提高训练效率。
📝 摘要(中文)
对抗模仿学习(AIL)是模仿学习中的主流框架,它从专家演示中推断奖励,以指导策略优化。虽然提供更多的专家演示通常可以提高性能和稳定性,但在某些情况下,收集这些演示可能具有挑战性。受到扩散模型在数据生成方面的成功的启发,我们提出了SD2AIL,它利用扩散模型生成合成演示。我们首先在判别器中使用扩散模型来生成合成演示,作为增强专家演示的伪专家数据。为了有选择地重放来自大量(伪)专家演示中最有价值的演示,我们进一步引入了一种优先专家演示重放策略(PEDR)。在模拟任务上的实验结果证明了我们方法的有效性和鲁棒性。特别是在Hopper任务中,我们的方法实现了3441的平均回报,超过了最先进的方法89。
🔬 方法详解
问题定义:对抗模仿学习(AIL)依赖于大量的专家演示数据来学习策略。然而,在许多实际场景中,获取足够的专家演示数据是困难的,例如,机器人操作任务需要耗费大量时间和资源进行人工示教,或者某些高风险场景无法进行真实演示。现有方法难以在有限的专家数据下获得理想的策略性能。
核心思路:SD2AIL的核心思路是利用扩散模型生成高质量的合成演示数据,作为伪专家数据来扩充原始的专家数据集。通过增加训练数据的多样性和数量,可以提高模仿学习算法的泛化能力和鲁棒性。此外,通过优先重放策略,可以更有效地利用这些合成数据。
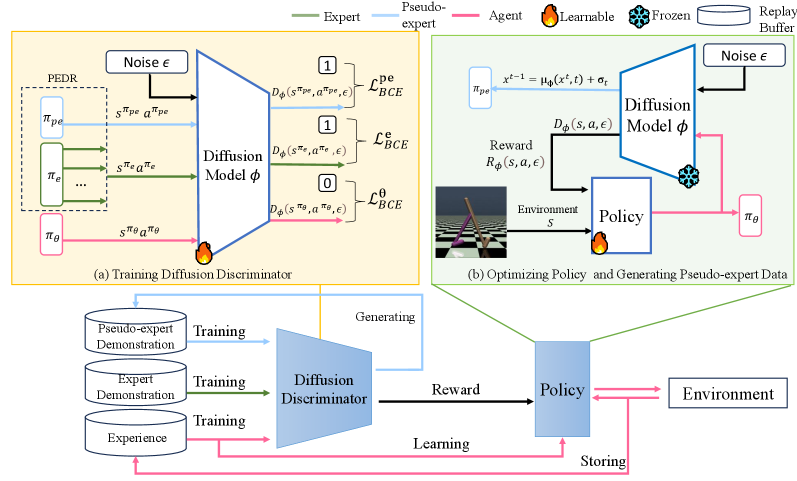
技术框架:SD2AIL的整体框架包含以下几个主要模块:1) 专家演示数据集;2) 扩散模型:用于生成合成演示数据;3) 判别器:区分专家演示和生成策略的行为;4) 策略网络:学习模仿专家行为;5) 优先专家演示重放缓冲区:存储专家演示和合成演示,并根据优先级进行采样。训练过程包括:首先训练扩散模型生成合成数据,然后将合成数据与专家数据混合,训练判别器和策略网络,并使用优先重放策略选择有价值的样本进行训练。
关键创新:SD2AIL的关键创新在于:1) 利用扩散模型生成高质量的合成演示数据,有效解决了专家数据不足的问题;2) 提出了优先专家演示重放策略(PEDR),能够从混合数据集中选择最有价值的样本进行训练,提高了训练效率和性能。与传统的AIL方法相比,SD2AIL不需要大量的真实专家数据,降低了数据收集成本。
关键设计:扩散模型采用DDPM架构,训练目标是最小化噪声预测误差。优先重放策略基于TD-error计算样本的优先级,TD-error越大,优先级越高,被采样的概率也越大。判别器采用神经网络结构,输入是状态-动作对,输出是该状态-动作对来自专家数据的概率。策略网络也采用神经网络结构,输入是状态,输出是动作。
🖼️ 关键图片


📊 实验亮点
SD2AIL在多个模拟任务上进行了评估,实验结果表明,SD2AIL能够显著提高模仿学习的性能。特别是在Hopper任务中,SD2AIL取得了3441的平均回报,超过了当前最先进的方法89。这表明SD2AIL能够有效地利用合成数据来增强模仿学习的效果,并且具有良好的鲁棒性。
🎯 应用场景
SD2AIL具有广泛的应用前景,例如,可以应用于机器人操作、自动驾驶、游戏AI等领域。在机器人操作中,可以利用合成数据来增强机器人的学习能力,使其能够完成复杂的任务。在自动驾驶中,可以利用合成数据来模拟各种交通场景,提高自动驾驶系统的安全性和可靠性。在游戏AI中,可以利用合成数据来训练更智能的AI角色,提升游戏体验。
📄 摘要(原文)
Adversarial Imitation Learning (AIL) is a dominant framework in imitation learning that infers rewards from expert demonstrations to guide policy optimization. Although providing more expert demonstrations typically leads to improved performance and greater stability, collecting such demonstrations can be challenging in certain scenarios. Inspired by the success of diffusion models in data generation, we propose SD2AIL, which utilizes synthetic demonstrations via diffusion models. We first employ a diffusion model in the discriminator to generate synthetic demonstrations as pseudo-expert data that augment the expert demonstrations. To selectively replay the most valuable demonstrations from the large pool of (pseudo-) expert demonstrations, we further introduce a prioritized expert demonstration replay strategy (PEDR). The experimental results on simulation tasks demonstrate the effectiveness and robustness of our method. In particular, in the Hopper task, our method achieves an average return of 3441, surpassing the state-of-the-art method by 89. Our code will be available at https://github.com/positron-lpc/SD2AIL.