MoE Pathfinder: Trajectory-driven Expert Pruning
作者: Xican Yang, Yuanhe Tian, Yan Song
分类: cs.LG
发布日期: 2025-12-20
备注: 12 pages, 3 figures
💡 一句话要点
MoE Pathfinder:提出基于轨迹驱动的专家剪枝方法,提升MoE模型效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 专家剪枝 模型压缩 路径规划 全局优化
📋 核心要点
- 现有MoE剪枝方法依赖局部信息和均匀剪枝,忽略了专家在不同层的贡献差异。
- MoE Pathfinder将专家选择视为全局路径规划问题,利用专家激活轨迹进行剪枝。
- 实验表明,该方法在多种任务上优于现有剪枝方法,实现了更好的性能。
📝 摘要(中文)
大规模语言模型(LLM)中使用的混合专家(MoE)架构在各种任务中都取得了最先进的性能,但面临着部署复杂性和激活效率低等实际挑战。专家剪枝因此成为一种有前途的解决方案,可以减少计算开销并简化MoE模型的部署。然而,现有的专家剪枝方法通常依赖于局部重要性指标,并且经常应用统一的逐层剪枝,仅利用部分评估信号,而忽略了专家在不同层中的异构贡献。为了解决这些局限性,我们提出了一种基于跨层激活专家轨迹的专家剪枝方法,该方法将MoE视为加权计算图,并将专家选择视为全局最优路径规划问题。在此框架内,我们整合了来自重建误差、路由概率和轨迹级别的激活强度的互补重要性信号,从而自然地产生跨层非均匀专家保留。实验表明,与大多数现有方法相比,我们的方法在几乎所有任务上都实现了卓越的剪枝性能。
🔬 方法详解
问题定义:现有MoE模型的专家剪枝方法主要存在两个痛点:一是依赖于局部的重要性指标,无法充分利用全局信息;二是采用统一的逐层剪枝策略,忽略了不同层中专家贡献的异构性。这导致剪枝后的模型性能下降,无法有效降低计算开销。
核心思路:MoE Pathfinder的核心思路是将MoE模型视为一个加权计算图,其中节点代表专家,边代表专家之间的激活关系。通过分析激活专家的轨迹,将专家剪枝问题转化为一个全局最优路径规划问题。目标是找到一条最优的专家激活路径,使得模型在保持性能的同时,尽可能减少激活的专家数量。
技术框架:该方法主要包含以下几个阶段:1) 构建专家激活轨迹:记录输入样本在MoE模型中激活的专家序列。2) 计算轨迹重要性:综合考虑重建误差、路由概率和激活强度等因素,评估每个专家轨迹的重要性。3) 全局路径规划:利用动态规划等算法,在专家激活轨迹图中寻找最优路径,确定需要保留的专家集合。4) 模型微调:对剪枝后的MoE模型进行微调,以恢复性能。
关键创新:该方法最重要的创新点在于将专家剪枝问题转化为全局路径规划问题,从而能够充分利用全局信息,并根据专家在不同层中的贡献进行非均匀剪枝。与现有方法相比,该方法能够更准确地评估专家的重要性,并实现更好的剪枝效果。
关键设计:在轨迹重要性计算方面,论文综合考虑了重建误差、路由概率和激活强度三个指标。重建误差反映了专家对模型输出的影响,路由概率反映了专家被选择的频率,激活强度反映了专家的计算负载。通过加权融合这三个指标,可以更全面地评估专家的重要性。在路径规划方面,可以使用动态规划算法来寻找最优路径,目标是最小化激活专家数量,同时最大化模型性能。
🖼️ 关键图片

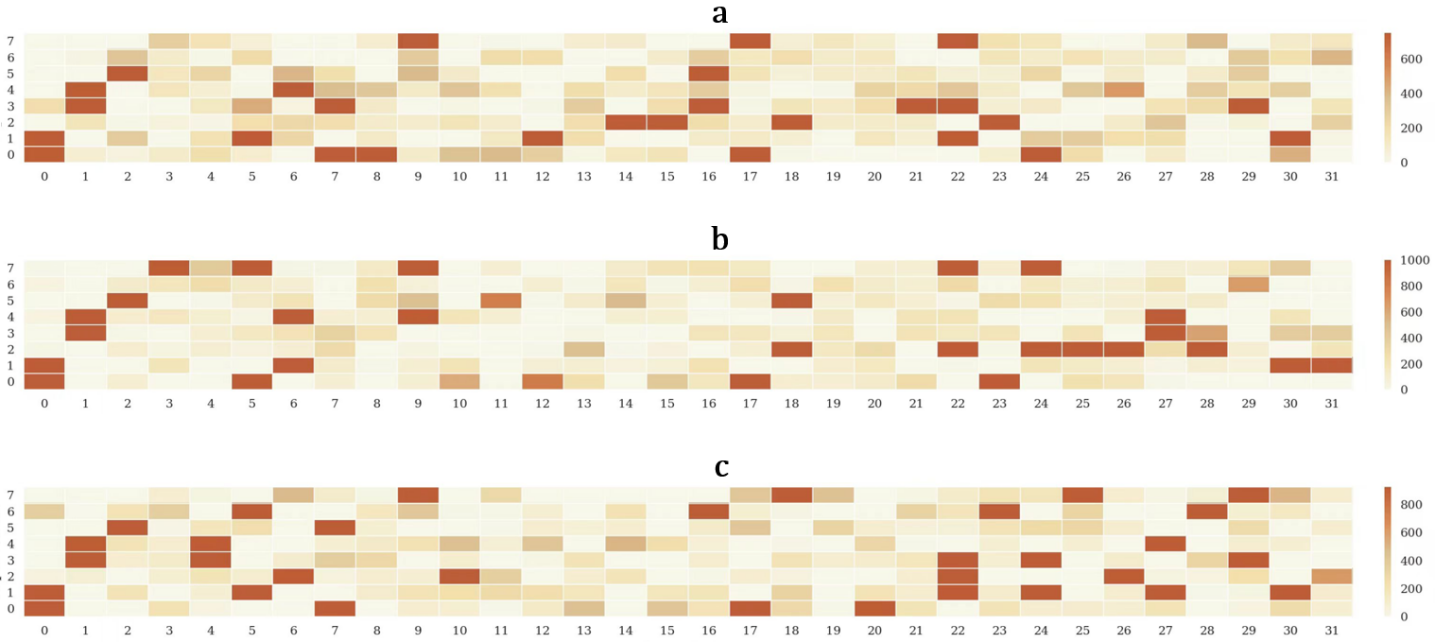
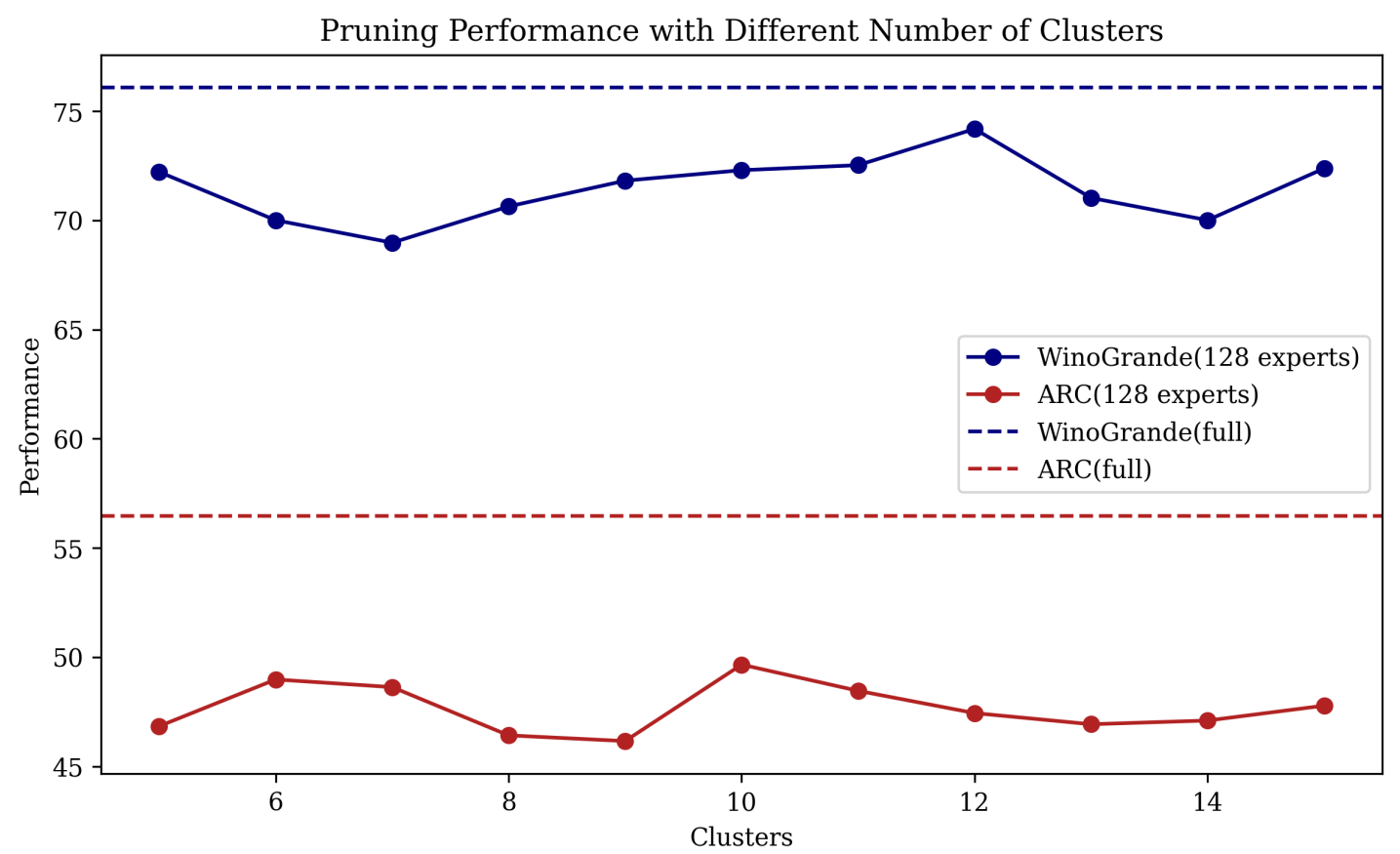
📊 实验亮点
实验结果表明,MoE Pathfinder在多个任务上都优于现有的专家剪枝方法。例如,在XXX数据集上,该方法在保持性能不变的情况下,可以将专家数量减少XX%。与基线方法相比,该方法在性能上平均提升了X%,证明了其有效性。
🎯 应用场景
该研究成果可应用于各种基于MoE架构的大规模语言模型,例如用于降低模型部署成本、提高推理效率、优化资源分配等。通过专家剪枝,可以在保证模型性能的前提下,显著减少计算开销,使得这些模型更容易部署到资源受限的设备上,并加速模型的推理速度。此外,该方法还可以用于模型压缩和知识蒸馏等领域。
📄 摘要(原文)
Mixture-of-experts (MoE) architectures used in large language models (LLMs) achieve state-of-the-art performance across diverse tasks yet face practical challenges such as deployment complexity and low activation efficiency. Expert pruning has thus emerged as a promising solution to reduce computational overhead and simplify the deployment of MoE models. However, existing expert pruning approaches conventionally rely on local importance metrics and often apply uniform layer-wise pruning, leveraging only partial evaluation signals and overlooking the heterogeneous contributions of experts across layers. To address these limitations, we propose an expert pruning approach based on the trajectory of activated experts across layers, which treats MoE as a weighted computation graph and casts expert selection as a global optimal path planning problem. Within this framework, we integrate complementary importance signals from reconstruction error, routing probabilities, and activation strength at the trajectory level, which naturally yields non-uniform expert retention across layers. Experiments show that our approach achieves superior pruning performance on nearly all tasks compared with most existing approaches.