Embedded Safety-Aligned Intelligence via Differentiable Internal Alignment Embeddings
作者: Harsh Rathva, Ojas Srivastava, Pruthwik Mishra
分类: cs.LG, cs.AI
发布日期: 2025-12-20
备注: 32 pages, 1 figure. Theoretical framework; no empirical results
💡 一句话要点
提出嵌入式安全对齐智能框架,通过可微内部对齐嵌入解决多智能体强化学习中的安全对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 安全对齐 内部对齐嵌入 反事实推理 注意力机制 图神经网络 可微编程
📋 核心要点
- 现有MARL方法依赖外部奖励塑造或事后安全约束,缺乏内在的安全对齐机制,导致智能体行为难以预测和控制。
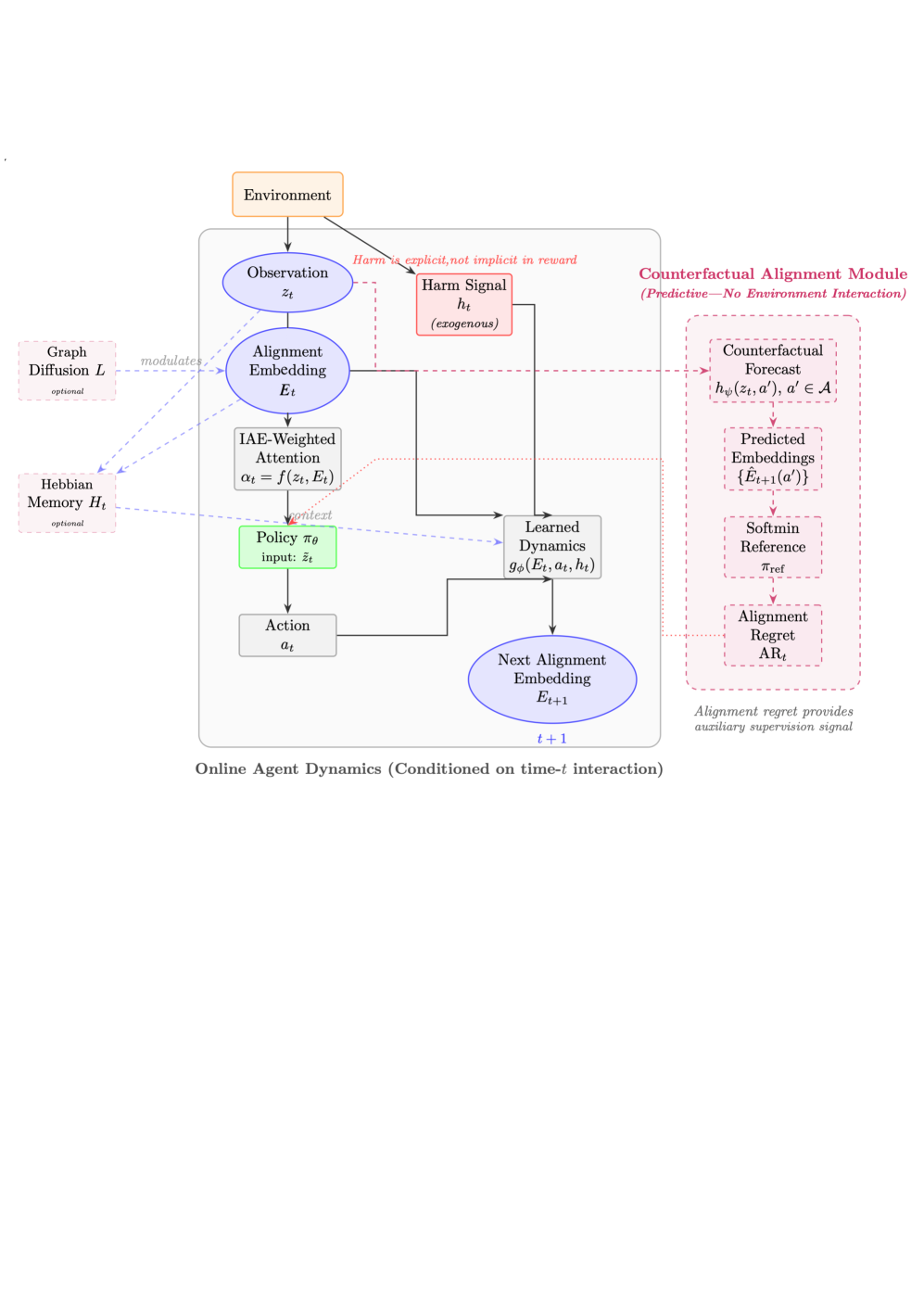
- ESAI框架通过学习内部对齐嵌入,利用反事实推理预测危害,并使用注意力机制和图传播来引导策略更新,从而实现内在的安全对齐。
- 论文分析了ESAI框架的稳定性条件、计算复杂度和理论性质,但缺乏实验验证,未来的工作将集中在实证评估上。
📝 摘要(中文)
本文提出嵌入式安全对齐智能(ESAI)框架,这是一个多智能体强化学习的理论框架,它使用可微内部对齐嵌入将对齐约束直接嵌入到智能体的内部表示中。与外部奖励塑造或事后安全约束不同,内部对齐嵌入是学习到的潜在变量,通过反事实推理预测外部危害,并通过注意力和基于图的传播来调节策略更新,从而减少危害。ESAI框架集成了四种机制:从软参考分布计算的可微反事实对齐惩罚、对齐加权感知注意力、支持时间信用分配的赫布关联记忆以及具有偏差缓解控制的相似性加权图扩散。我们分析了在Lipschitz连续性和谱约束下有界内部嵌入的稳定性条件,讨论了计算复杂度,并研究了包括收缩行为和公平性-性能权衡在内的理论性质。这项工作将ESAI定位为多智能体系统中可微对齐机制的概念性贡献。我们确定了关于收敛保证、嵌入维度以及扩展到高维环境的开放理论问题。实证评估留待未来的工作。
🔬 方法详解
问题定义:多智能体强化学习(MARL)中的安全对齐问题,即如何确保智能体在学习和执行任务的过程中,不会对环境或其他智能体造成无法接受的危害。现有方法,如外部奖励塑造和事后安全约束,通常难以有效地将安全约束融入智能体的决策过程,并且可能导致智能体学习到次优或不安全的策略。
核心思路:核心思路是将安全对齐约束直接嵌入到智能体的内部表示中,通过学习可微的内部对齐嵌入(Internal Alignment Embeddings)来实现。这些嵌入能够预测外部危害,并指导策略更新,从而使智能体能够内在化安全意识。这种方法避免了对外部奖励或约束的依赖,从而提高了智能体的安全性和鲁棒性。
技术框架:ESAI框架包含四个主要模块:1) 可微反事实对齐惩罚:通过软参考分布计算反事实场景下的危害,并施加惩罚。2) 对齐加权感知注意力:根据对齐嵌入调整智能体的注意力,使其更加关注与安全相关的特征。3) 赫布关联记忆:利用赫布学习机制进行时间信用分配,将长期行为与安全后果联系起来。4) 相似性加权图扩散:通过图神经网络在智能体之间传播安全信息,并缓解偏差。
关键创新:最重要的创新在于提出了可微内部对齐嵌入的概念,并将其应用于多智能体系统的安全对齐。与传统的外部约束方法不同,ESAI框架通过学习内部表示来实现安全对齐,从而提高了智能体的自主性和适应性。此外,框架集成了反事实推理、注意力机制、赫布学习和图神经网络等多种技术,共同促进安全对齐。
关键设计:1) 反事实对齐惩罚:使用软参考分布生成反事实场景,并计算每个场景下的危害。惩罚函数的设计需要平衡安全性和任务完成度。2) 对齐加权感知注意力:注意力权重的计算基于对齐嵌入与感知输入的相似度。3) 赫布关联记忆:使用赫布学习规则更新记忆,将行为与长期后果联系起来。4) 相似性加权图扩散:图神经网络的结构和参数需要根据具体的多智能体环境进行设计。
🖼️ 关键图片
📊 实验亮点
论文主要贡献在于理论框架的提出,并未进行实验验证。论文分析了ESAI框架的稳定性条件,并讨论了计算复杂度和公平性-性能权衡等理论性质。未来的工作将集中在实证评估上,包括在各种多智能体环境中测试ESAI框架的性能,并与其他安全对齐方法进行比较。具体的性能数据和提升幅度未知。
🎯 应用场景
ESAI框架具有广泛的应用前景,例如自动驾驶、机器人协作、金融交易等领域。在自动驾驶中,ESAI可以帮助车辆避免碰撞和违反交通规则。在机器人协作中,ESAI可以确保机器人之间的安全协作,避免对人类或环境造成危害。在金融交易中,ESAI可以用于风险管理,防止恶意交易和市场操纵。该研究的未来影响在于,它为构建安全可靠的人工智能系统提供了一种新的理论框架和技术手段。
📄 摘要(原文)
We introduce Embedded Safety-Aligned Intelligence (ESAI), a theoretical framework for multi-agent reinforcement learning that embeds alignment constraints directly into agents internal representations using differentiable internal alignment embeddings. Unlike external reward shaping or post-hoc safety constraints, internal alignment embeddings are learned latent variables that predict externalized harm through counterfactual reasoning and modulate policy updates toward harm reduction through attention and graph-based propagation. The ESAI framework integrates four mechanisms: differentiable counterfactual alignment penalties computed from soft reference distributions, alignment-weighted perceptual attention, Hebbian associative memory supporting temporal credit assignment, and similarity-weighted graph diffusion with bias mitigation controls. We analyze stability conditions for bounded internal embeddings under Lipschitz continuity and spectral constraints, discuss computational complexity, and examine theoretical properties including contraction behavior and fairness-performance tradeoffs. This work positions ESAI as a conceptual contribution to differentiable alignment mechanisms in multi-agent systems. We identify open theoretical questions regarding convergence guarantees, embedding dimensionality, and extension to high-dimensional environments. Empirical evaluation is left to future work.