Conscious Data Contribution via Community-Driven Chain-of-Thought Distillation
作者: Lena Libon, Meghana Bhange, Rushabh Solanki, Elliot Creager, Ulrich Aïvodji
分类: cs.LG, cs.CR, cs.CY
发布日期: 2025-12-20
💡 一句话要点
提出基于社区驱动的思维链蒸馏方法,提升用户数据自主性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 知识蒸馏 社区驱动 数据自主性 用户参与 个性化模型 联邦学习 LLM
📋 核心要点
- 大型语言模型训练依赖海量数据,引发数据隐私和用户自主权问题,用户贡献的数据价值未得到充分体现。
- 论文提出基于社区驱动的思维链蒸馏方法,允许用户群体共同提炼知识,构建更符合自身需求的模型。
- 实验验证了该方法的可行性,并分析了社区多样性、推理粒度和社区规模对模型蒸馏效果的影响。
📝 摘要(中文)
当前人工智能发展时代,非常重视在不断扩展的数据集上训练大型模型。这种范式催生了全新的产品类别,例如LLM聊天机器人,同时也引发了对数据隐私和消费者选择的担忧。本文考虑了在使用思维链(CoT)进行“推理”的LLM背景下的数据可移植性和用户自主性问题,这些LLM在生成最终输出之前,会从用户输入中计算中间文本信息。我们首先解释了最近的数据隐私和可移植性法律,认为这些中间计算结果属于用户的个人数据。然后,在现有的“有意识的数据贡献”框架的基础上,我们展示了从现有模型中获得低效用的社区如何聚合和提炼他们的共享知识,从而形成一个更符合其目标的替代模型。我们通过实验验证了这种方法,并研究了社区多样性、推理粒度和社区规模对蒸馏性能的影响。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的训练依赖于大规模数据集,但用户对自身数据的使用和模型的影响力有限。用户贡献的数据可能被用于训练不符合其价值观或需求的模型,存在数据隐私和自主性问题。此外,某些社区可能从现有模型中获得的效用较低,缺乏定制化模型的手段。
核心思路:论文的核心思路是利用“有意识的数据贡献”框架,允许用户社区将其共享知识提炼成一个更符合自身目标的替代模型。通过思维链(Chain-of-Thought, CoT)蒸馏,将社区的推理过程融入到新模型的训练中,从而实现知识的迁移和模型的个性化。
技术框架:该方法主要包含以下几个阶段:1) 数据收集:社区成员贡献其数据和对应的思维链推理过程。2) 数据聚合:将社区成员贡献的数据和推理过程进行整合。3) 模型蒸馏:使用聚合后的数据和推理过程,通过蒸馏训练得到新的模型。该模型的目标是模仿社区的推理过程和输出结果。4) 模型评估:评估新模型在社区关注的任务上的性能,并与原始模型进行比较。
关键创新:该方法的关键创新在于将社区驱动的知识贡献与思维链蒸馏相结合,实现了用户自主的模型定制。与传统的模型训练方法相比,该方法更加注重用户参与和数据所有权,允许用户群体共同塑造模型的能力和行为。此外,利用思维链蒸馏可以有效地将社区的推理过程迁移到新模型中,提高模型的性能和可解释性。
关键设计:论文中涉及的关键设计包括:1) 思维链的生成方式:如何引导社区成员生成高质量的思维链推理过程?2) 蒸馏损失函数:如何设计损失函数,使得新模型能够有效地模仿社区的推理过程和输出结果?3) 社区多样性的影响:如何量化社区多样性,并分析其对蒸馏性能的影响?4) 推理粒度的选择:选择合适的推理粒度,平衡模型的性能和可解释性。
🖼️ 关键图片

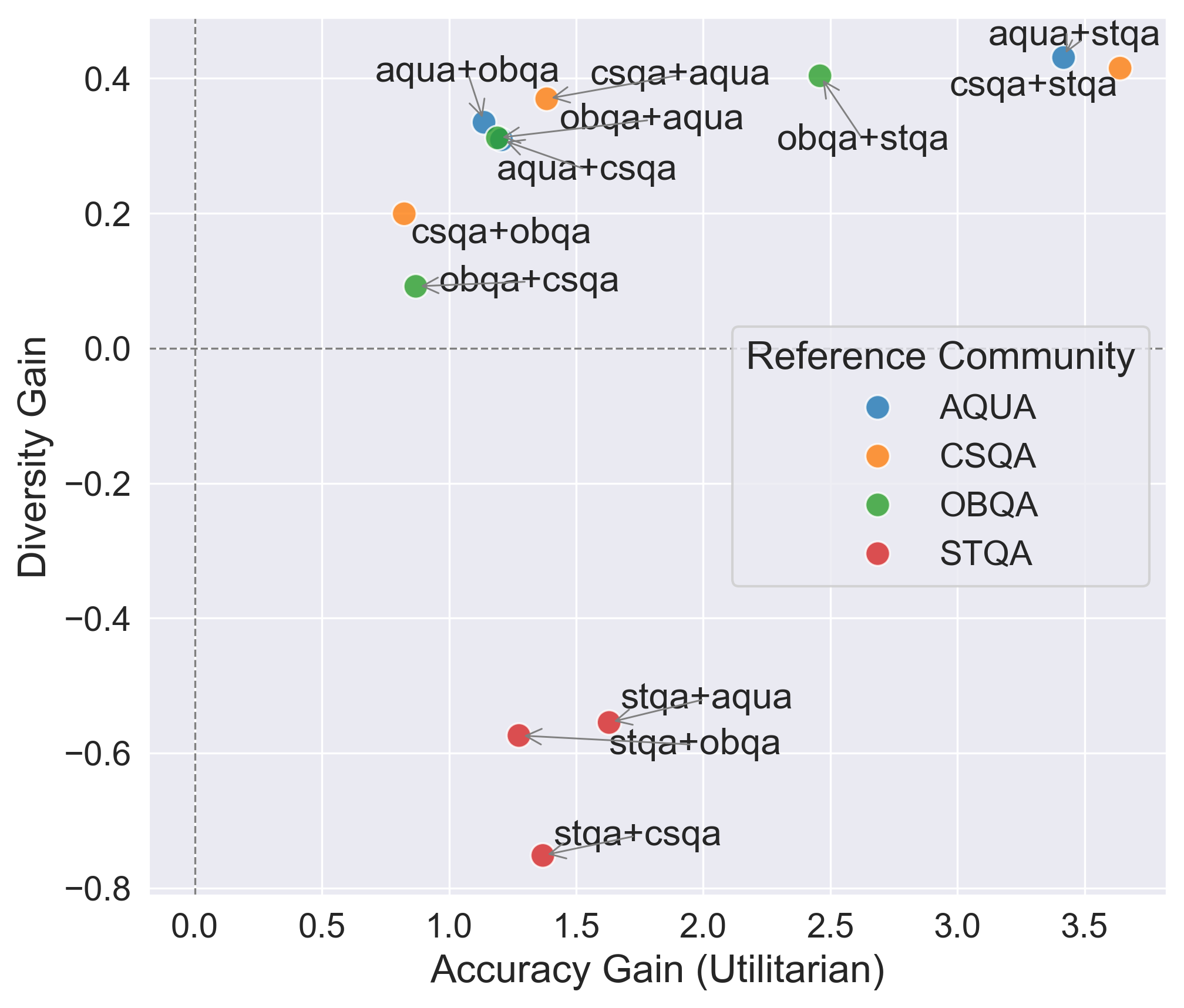

📊 实验亮点
论文通过实验验证了社区驱动的思维链蒸馏方法的可行性。实验结果表明,通过该方法训练得到的模型在社区关注的任务上取得了显著的性能提升。此外,研究还发现社区多样性、推理粒度和社区规模对蒸馏性能具有重要影响。例如,适当的社区多样性可以提高模型的泛化能力,而合适的推理粒度可以平衡模型的性能和可解释性。具体的性能数据和对比基线在论文中有详细描述。
🎯 应用场景
该研究成果可应用于个性化教育、社区知识库构建、以及特定领域专家系统的开发。通过社区驱动的思维链蒸馏,可以构建更符合用户需求、更具领域知识的定制化模型,提升用户体验和数据自主性。未来,该方法有望应用于更广泛的场景,例如医疗诊断、金融风控等,促进人工智能技术的普惠化发展。
📄 摘要(原文)
The current era of AI development places a heavy emphasis on training large models on increasingly scaled-up datasets. This paradigm has catalyzed entirely new product categories, such as LLM chatbots, while also raising concerns about data privacy and consumer choice. In this paper, we consider questions of data portability and user autonomy in the context of LLMs that "reason" using chain-of-thought (CoT) traces, computing intermediate text artifacts from user input before producing a final output. We first interpret recent data privacy and portability law to argue that these intermediate computations qualify as users' personal data. Then, building on the existing framework of Conscious Data Contribution, we show how communities who receive low utility from an available model can aggregate and distill their shared knowledge into an alternate model better aligned with their goals. We verify this approach empirically and investigate the effects of community diversity, reasoning granularity, and community size on distillation performance.