Hierarchical Sparse Plus Low Rank Compression of LLM
作者: Pawan Kumar, Aditi Gupta
分类: cs.LG, cs.AI
发布日期: 2025-12-19
备注: 9 pages, 3 figures, Accepted in ACM International Conference on Data Science, CODS-2026
💡 一句话要点
提出分层稀疏加低秩压缩(HSS)方法,用于压缩LLM并保持性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型压缩 稀疏化 低秩分解 分层压缩 模型优化 递归降秩 RCM置换
📋 核心要点
- 大型语言模型(LLM)的部署和训练面临巨大的内存和计算压力,需要有效的压缩方法。
- 论文提出HSS压缩方法,通过两阶段策略:稀疏化和递归分层低秩分解,实现对LLM的压缩。
- 实验表明,HSS在压缩LLaMA-7B模型时,能够在保持或超越现有方法困惑度的同时,显著节省内存。
📝 摘要(中文)
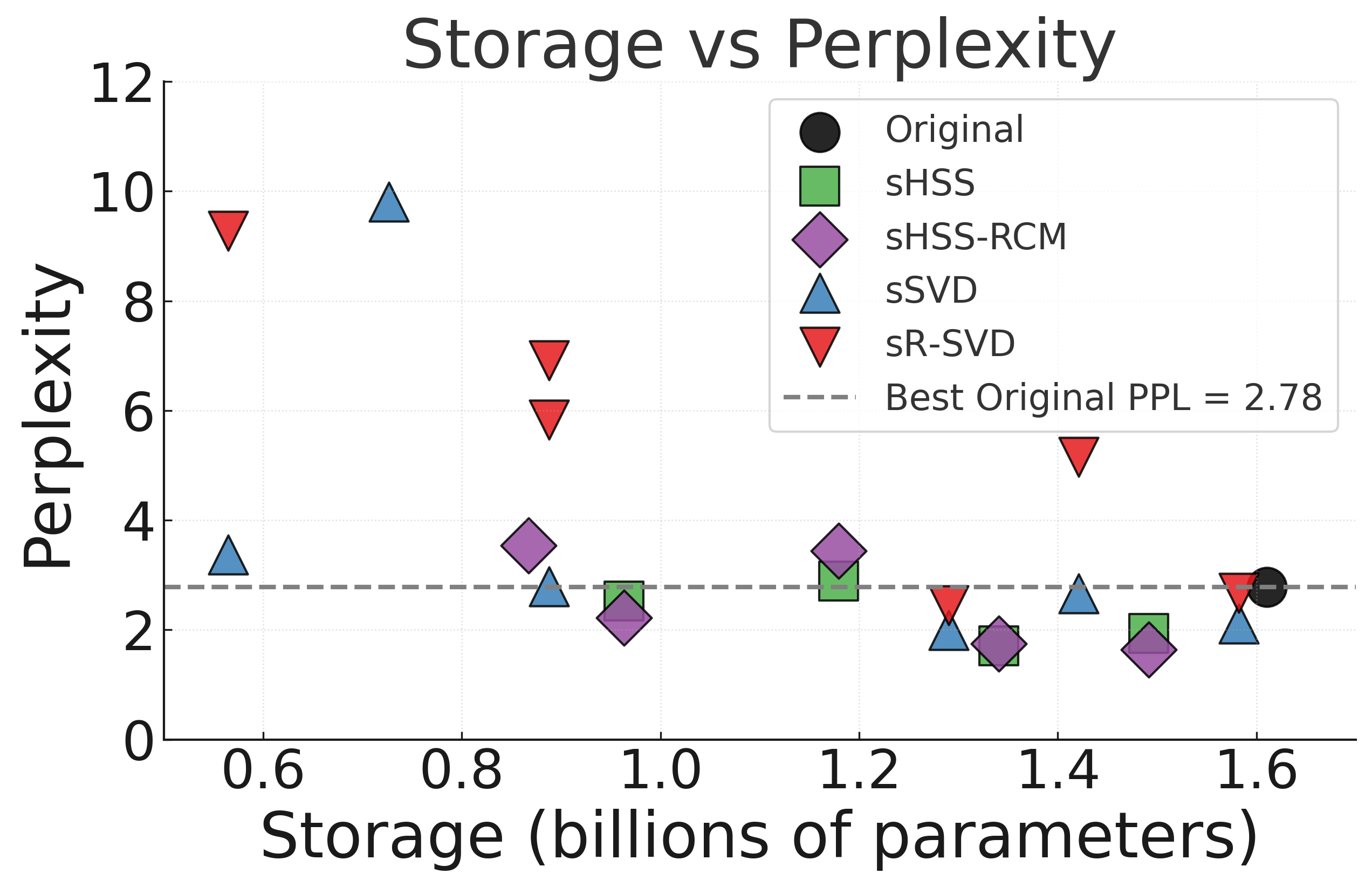
现代大型语言模型(LLM)对内存和计算资源提出了极高的要求,因此,有原则的压缩对于部署和持续训练至关重要。我们提出了一种分层稀疏加低秩(HSS)压缩方法,该方法分为两个阶段:(i)将最大幅度的权重移除到一个稀疏矩阵S中;(ii)对稠密残差矩阵应用递归的分层稀疏可分离(HSS)低秩分解。引入了一种递归的降秩策略和反向Cuthill-Mckee(RCM)置换,以将高权重对齐到具有块对角层次结构的对角线附近,从而最大化非对角线可压缩性(因为它们只被触及一次)。HSS对硬件友好:它的矩阵向量乘法简化为一个稀疏矩阵乘法和一系列细矩阵乘法,并且可以使用标准优化器进行端到端训练。在LLaMA-7B上的实验表明,仅针对自注意力投影(Q、K和V矩阵的16亿个参数,总共70亿个参数)就足以在保持与最先进的WikiText数据集测试样本困惑度分数相当的同时,节省大量内存。例如,在30%的稀疏度预算和512的外部秩下,sHSS-RCM实现了1.64的困惑度,优于稠密基线和经典的稀疏加SVD变体,同时也实现了显著的内存节省。
🔬 方法详解
问题定义:大型语言模型(LLM)参数众多,对内存和计算资源需求巨大,这限制了其在资源受限环境中的部署和持续训练。现有压缩方法,如传统的稀疏化和低秩分解,在压缩率和性能保持方面存在局限性。
核心思路:论文的核心思路是结合稀疏化和分层低秩分解的优势。首先,通过稀疏化去除冗余权重,然后利用分层低秩分解进一步压缩剩余的稠密残差矩阵。这种方法旨在最大化压缩率,同时尽可能减少对模型性能的影响。通过递归降秩和RCM置换,优化了低秩分解的效率。
技术框架:HSS压缩方法包含两个主要阶段:1. 稀疏化:移除模型中幅度最大的权重,形成稀疏矩阵S。2. 分层低秩分解:对剩余的稠密残差矩阵进行递归的分层稀疏可分离(HSS)低秩分解。在低秩分解过程中,采用了递归降秩策略和反向Cuthill-Mckee(RCM)置换,以优化分解效果。整个过程可以进行端到端训练。
关键创新:HSS的关键创新在于结合了稀疏化和分层低秩分解,并引入了递归降秩策略和RCM置换。与传统的稀疏化或低秩分解方法相比,HSS能够更有效地压缩LLM,并在保持模型性能方面表现更好。RCM置换的引入使得高权重集中在对角线附近,从而提升了低秩分解的效率。
关键设计:HSS的关键设计包括:1. 稀疏度预算:控制稀疏化的程度,决定移除多少权重。2. 外部秩:控制低秩分解的秩,影响压缩率和性能。3. 递归降秩策略:逐步降低低秩分解的秩,以优化压缩效果。4. 反向Cuthill-Mckee(RCM)置换:重新排列矩阵的行和列,使高权重集中在对角线附近,从而提高低秩分解的效率。损失函数采用标准的交叉熵损失,优化器可以使用Adam等常用优化器。
🖼️ 关键图片

📊 实验亮点
在LLaMA-7B模型上的实验结果表明,HSS在压缩自注意力投影层(Q、K、V矩阵)时,能够在保持与最先进方法相当的困惑度(1.64)的同时,显著节省内存。例如,在30%的稀疏度预算和512的外部秩下,sHSS-RCM优于稠密基线和经典的稀疏加SVD变体。
🎯 应用场景
HSS压缩方法可以应用于各种大型语言模型的压缩,使其能够在资源受限的设备上部署,例如移动设备、边缘计算设备等。该方法还可以用于加速LLM的训练过程,降低训练成本。此外,HSS还可以应用于其他类型的深度学习模型,例如计算机视觉模型和语音识别模型。
📄 摘要(原文)
Modern large language models (LLMs) place extraordinary pressure on memory and compute budgets, making principled compression indispensable for both deployment and continued training. We present Hierarchical Sparse Plus Low-Rank (HSS) compression, a two-stage scheme that (i) removes the largest-magnitude weights into a sparse matrix S and (ii) applies a recursive Hierarchically Sparse Separable (HSS) low-rank factorisation to the dense residual matrix. A recursive rank-reducing strategy and a reverse Cuthill-Mckee (RCM) permutation are introduced to align high weights towards the diagonal with the block-diagonal hierarchy, maximising off-diagonal compressibility (because they are touched only once). HSS is hardware-friendly: its matrix-vector multiply reduces to one sparse and a sequence of thin-matrix multiplications and can be trained end-to-end with standard optimisers. Experiments on LLaMA-7B show that targeting only the self-attention projections (1.6 B parameters of Q, K, and V matrices out of a total 7B parameters) suffices to yield large memory savings while retaining comparable state-of-the-art perplexity scores on test samples of the WikiText dataset. For example, with a 30\% sparsity budget and an outer rank of 512, sHSS-RCM achieves a perplexity of 1.64, outperforming dense baselines and classical sparse-plus-SVD variants, while also achieving significant memory savings.