Towards Benchmarking Privacy Vulnerabilities in Selective Forgetting with Large Language Models
作者: Wei Qian, Chenxu Zhao, Yangyi Li, Mengdi Huai
分类: cs.LG, cs.CR
发布日期: 2025-12-19
💡 一句话要点
构建选择性遗忘隐私漏洞基准,评估大语言模型的隐私泄露风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 选择性遗忘 机器卸载学习 隐私漏洞 基准测试 隐私攻击 大语言模型 数据隐私 人工智能安全
📋 核心要点
- 现有选择性遗忘隐私攻击评估缺乏统一标准,导致评估结果片面且不公平。
- 构建全面的基准测试框架,系统评估不同选择性遗忘方法在各种场景下的隐私泄露风险。
- 通过实验分析,识别影响选择性遗忘隐私泄露的关键因素,为实际应用提供指导。
📝 摘要(中文)
人工智能的快速发展主要集中在从数据中学习以获得知识丰富的学习系统。由于这些系统越来越多地部署在关键领域,因此确保其隐私和与人类价值观的一致性至关重要。最近,选择性遗忘(也称为机器卸载学习)已显示出在隐私和数据删除任务中的前景,并已成为人工智能领域中一种变革性的范式转变。它指的是模型选择性地消除先前看到的数据的影响的能力,这对于遵守现代数据保护法规和使模型与人类价值观保持一致尤其重要。尽管前景广阔,但选择性遗忘引发了重大的隐私问题,尤其是在所涉及的数据来自敏感领域时。虽然不断提出新的卸载学习引起的隐私攻击,但每种攻击都显示出在使用不同实验设置时优于其前身,这可能导致过于乐观和可能不公平的评估,这些评估可能会不成比例地偏爱一种特定的攻击。在这项工作中,我们提出了第一个全面的基准,用于评估选择性遗忘中的隐私漏洞。我们广泛研究了机器卸载学习技术的隐私漏洞,并对各种受害者数据、最先进的卸载学习隐私攻击、卸载学习方法和模型架构中的隐私泄露进行了基准测试。我们系统地评估和识别与卸载学习引起的隐私泄露相关的关键因素。凭借我们的新颖见解,我们旨在为寻求部署具有忠实隐私评估的定制卸载学习应用程序的从业者提供标准化工具。
🔬 方法详解
问题定义:论文旨在解决选择性遗忘(或称机器卸载学习)技术中隐私漏洞评估缺乏统一标准的问题。现有研究通常使用不同的实验设置来评估新的隐私攻击方法,导致评估结果缺乏可比性,并且可能对某些攻击方法产生不公平的偏袒。这使得从业者难以准确评估选择性遗忘技术的隐私风险,并选择合适的卸载学习方法。
核心思路:论文的核心思路是构建一个全面的基准测试框架,该框架涵盖了各种受害者数据、最先进的卸载学习隐私攻击、卸载学习方法和模型架构。通过在这个统一的框架下进行系统评估,可以更公平地比较不同卸载学习方法的隐私泄露风险,并识别影响隐私泄露的关键因素。
技术框架:该基准测试框架包含以下主要组成部分:1) 受害者数据:涵盖各种敏感领域的数据集,用于模拟不同的隐私泄露场景。2) 卸载学习方法:包括各种最先进的卸载学习算法,例如精确卸载、近似卸载等。3) 隐私攻击方法:包括各种用于评估隐私泄露风险的攻击方法,例如成员推断攻击、属性推断攻击等。4) 模型架构:涵盖各种常见的模型架构,例如线性模型、神经网络等。通过在这些组件的不同组合下进行实验,可以全面评估选择性遗忘技术的隐私漏洞。
关键创新:该论文的主要创新在于构建了第一个全面的选择性遗忘隐私漏洞基准测试框架。该框架提供了一个统一的平台,用于评估不同卸载学习方法在各种场景下的隐私泄露风险。此外,该论文还通过实验分析识别了影响隐私泄露的关键因素,为实际应用提供了指导。
关键设计:论文的关键设计包括:1) 选择具有代表性的受害者数据集,涵盖不同的敏感领域。2) 收集最先进的卸载学习方法和隐私攻击方法。3) 设计合理的实验流程,确保评估结果的可靠性和可比性。4) 使用合适的评估指标来量化隐私泄露风险,例如攻击成功率、信息泄露量等。
🖼️ 关键图片

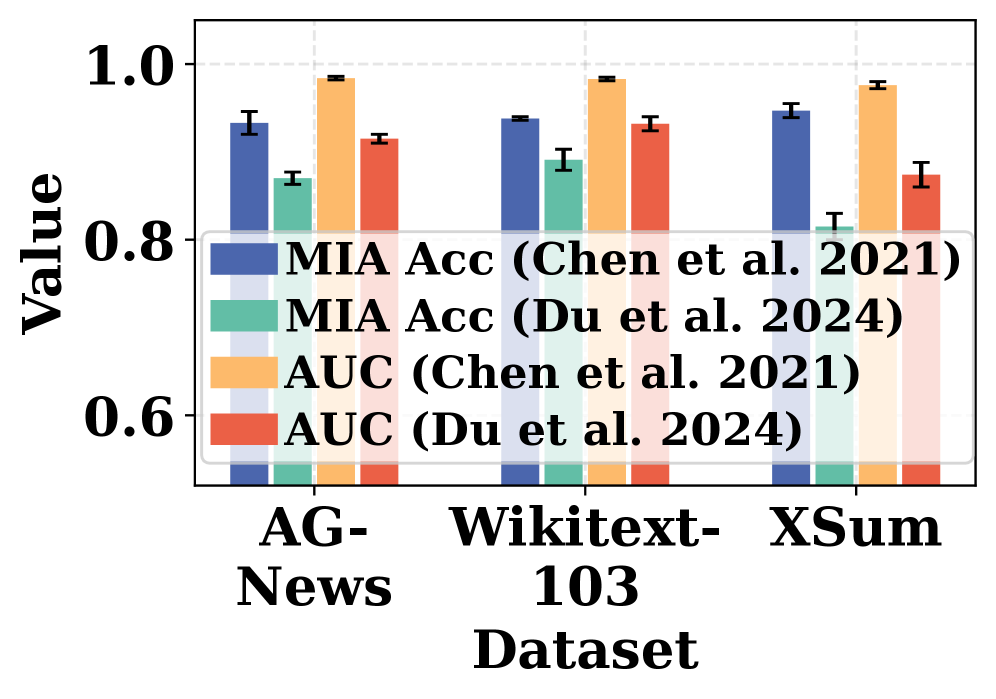

📊 实验亮点
该研究构建了首个全面的选择性遗忘隐私漏洞基准,并对多种卸载学习方法、隐私攻击和模型架构进行了系统评估。实验结果揭示了不同因素对隐私泄露的影响,例如:某些卸载学习方法在特定数据集上更容易受到攻击,某些模型架构对隐私攻击更敏感。这些发现为选择合适的卸载学习方法和模型架构提供了重要参考。
🎯 应用场景
该研究成果可应用于各种需要选择性遗忘的场景,例如:数据合规性(GDPR等)、模型个性化、联邦学习等。通过使用该基准测试框架,从业者可以更好地评估和降低选择性遗忘带来的隐私风险,从而更安全地部署相关技术。该研究还有助于推动选择性遗忘技术的发展,使其更加安全可靠。
📄 摘要(原文)
The rapid advancements in artificial intelligence (AI) have primarily focused on the process of learning from data to acquire knowledgeable learning systems. As these systems are increasingly deployed in critical areas, ensuring their privacy and alignment with human values is paramount. Recently, selective forgetting (also known as machine unlearning) has shown promise for privacy and data removal tasks, and has emerged as a transformative paradigm shift in the field of AI. It refers to the ability of a model to selectively erase the influence of previously seen data, which is especially important for compliance with modern data protection regulations and for aligning models with human values. Despite its promise, selective forgetting raises significant privacy concerns, especially when the data involved come from sensitive domains. While new unlearning-induced privacy attacks are continuously proposed, each is shown to outperform its predecessors using different experimental settings, which can lead to overly optimistic and potentially unfair assessments that may disproportionately favor one particular attack over the others. In this work, we present the first comprehensive benchmark for evaluating privacy vulnerabilities in selective forgetting. We extensively investigate privacy vulnerabilities of machine unlearning techniques and benchmark privacy leakage across a wide range of victim data, state-of-the-art unlearning privacy attacks, unlearning methods, and model architectures. We systematically evaluate and identify critical factors related to unlearning-induced privacy leakage. With our novel insights, we aim to provide a standardized tool for practitioners seeking to deploy customized unlearning applications with faithful privacy assessments.