Learning to Plan, Planning to Learn: Adaptive Hierarchical RL-MPC for Sample-Efficient Decision Making
作者: Toshiaki Hori, Jonathan DeCastro, Deepak Gopinath, Avinash Balachandran, Guy Rosman
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-12-18
备注: 23 pages, 8 figures. Under review
💡 一句话要点
提出自适应分层RL-MPC方法,解决复杂规划问题中的样本效率低下问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型预测控制 分层规划 自适应采样 样本效率
📋 核心要点
- 现有规划方法在复杂环境中样本效率低,难以平衡探索与利用。
- 提出自适应分层RL-MPC框架,利用强化学习指导MPC采样,并用MPC结果优化价值估计。
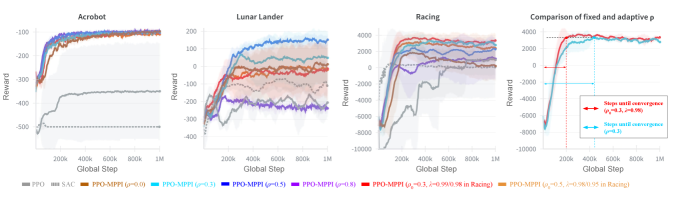
- 实验表明,该方法在赛车、Acrobot和Lunar Lander等任务中,显著提升了数据效率和任务成功率。
📝 摘要(中文)
本文提出了一种新的方法,用于解决具有分层结构的规划问题,融合了强化学习和MPC规划。该方法紧密且优雅地结合了这两种规划范式。它利用强化学习的动作来指导MPPI采样器,并自适应地聚合MPPI样本来指导价值估计。由此产生的自适应过程在价值估计不确定时,进一步利用MPPI探索,并提高训练的鲁棒性和整体策略。结果表明,该方法是一种鲁棒的规划方法,可以处理复杂的规划问题,并易于适应不同的应用,如赛车、改进的Acrobot和带有障碍物的Lunar Lander。在这些领域的结果表明,与现有方法相比,在奖励和任务成功率方面都具有更好的数据效率和整体性能,成功率提高了高达72%,并且与非自适应采样相比,收敛速度加快了2.1倍。
🔬 方法详解
问题定义:现有的规划方法,尤其是在复杂和动态的环境中,往往面临样本效率低下的问题。传统的基于模型预测控制(MPC)的方法可能需要大量的样本来学习准确的模型,而强化学习(RL)方法在探索高维状态空间时也面临挑战。此外,如何在探索(exploration)和利用(exploitation)之间取得平衡也是一个关键问题。
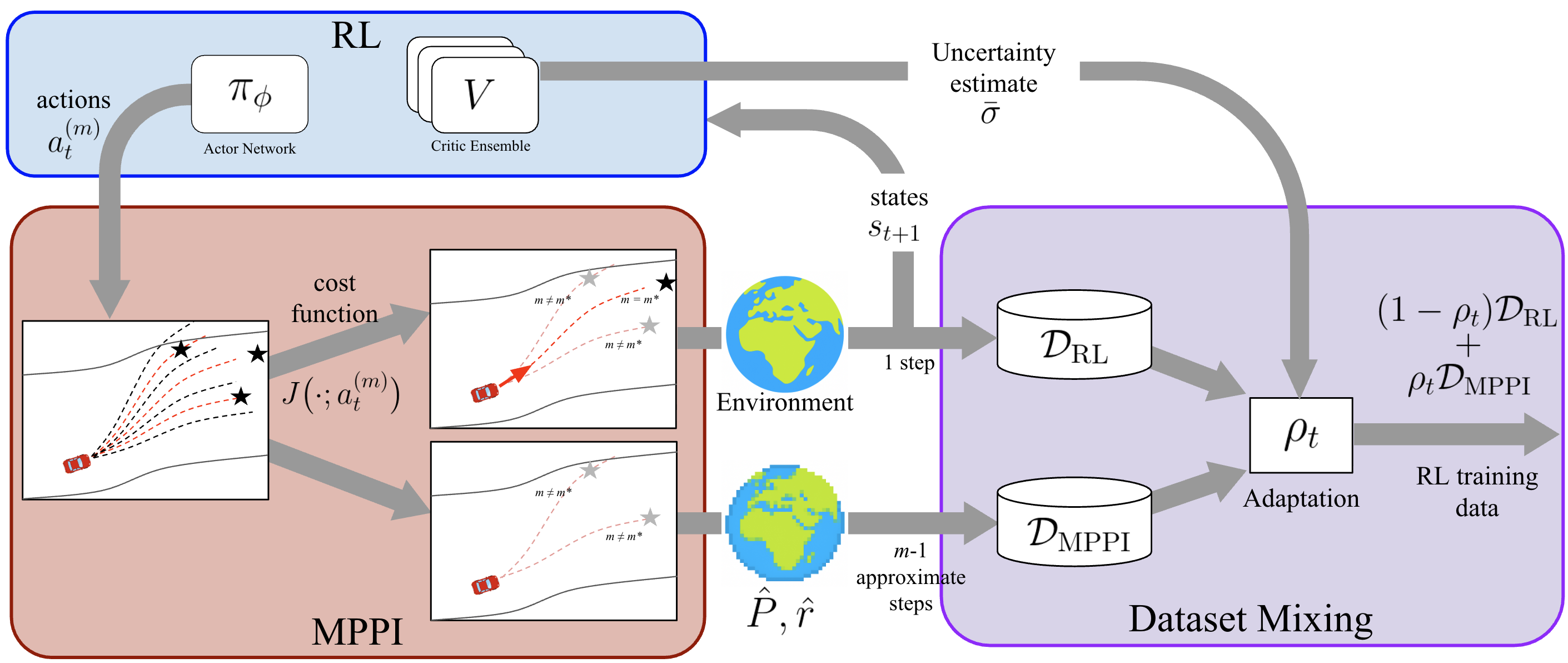
核心思路:本文的核心思路是将强化学习(RL)和模型预测控制(MPC)相结合,形成一个自适应的分层规划框架。通过利用RL来指导MPC的采样过程,并利用MPC的规划结果来改进RL的价值估计,从而实现更高效的样本利用和更鲁棒的策略学习。这种结合允许算法在不确定性较高时进行更多的探索,而在已知区域进行更有效的利用。
技术框架:该框架包含两个主要组成部分:一个基于强化学习的策略网络和一个基于模型预测控制(MPC)的规划器。RL策略网络输出动作,这些动作被用作MPPI(Model Predictive Path Integral)采样器的先验分布。MPPI采样器生成一系列候选轨迹,这些轨迹被用于更新RL策略网络的价值估计。整个过程是迭代进行的,RL策略网络和MPPI采样器相互促进,共同优化策略。
关键创新:该方法最关键的创新在于其自适应采样机制。传统的MPPI方法通常使用固定的采样策略,而本文提出的方法根据价值估计的不确定性动态调整采样策略。具体来说,当价值估计不确定时,算法会进行更多的探索性采样,以更好地了解环境;当价值估计比较确定时,算法会进行更多的利用性采样,以优化当前策略。这种自适应采样机制显著提高了样本效率和策略的鲁棒性。
关键设计:在具体实现上,该方法使用了MPPI作为MPC的实现方式,因为它能够有效地处理高维状态空间和非线性动力学。RL策略网络可以使用各种常见的RL算法,例如PPO或SAC。损失函数的设计需要平衡RL的奖励和MPC的规划目标。此外,如何有效地聚合MPPI采样结果以更新价值估计也是一个关键的设计选择。论文中具体使用的网络结构和参数设置可能需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在赛车、改进的Acrobot和带有障碍物的Lunar Lander等任务中,与现有方法相比,数据效率更高,整体性能更好。具体而言,任务成功率提高了高达72%,并且与非自适应采样相比,收敛速度加快了2.1倍。这些结果表明,该方法在解决复杂规划问题方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于机器人、自动驾驶、游戏AI等领域。例如,在自动驾驶中,可以利用该方法提高车辆在复杂交通环境下的决策能力和安全性;在机器人领域,可以帮助机器人更好地完成各种任务,如物体抓取、导航等;在游戏AI中,可以创建更智能、更具挑战性的游戏角色。
📄 摘要(原文)
We propose a new approach for solving planning problems with a hierarchical structure, fusing reinforcement learning and MPC planning. Our formulation tightly and elegantly couples the two planning paradigms. It leverages reinforcement learning actions to inform the MPPI sampler, and adaptively aggregates MPPI samples to inform the value estimation. The resulting adaptive process leverages further MPPI exploration where value estimates are uncertain, and improves training robustness and the overall resulting policies. This results in a robust planning approach that can handle complex planning problems and easily adapts to different applications, as demonstrated over several domains, including race driving, modified Acrobot, and Lunar Lander with added obstacles. Our results in these domains show better data efficiency and overall performance in terms of both rewards and task success, with up to a 72% increase in success rate compared to existing approaches, as well as accelerated convergence (x2.1) compared to non-adaptive sampling.