Exploration vs Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
作者: Peter Chen, Xiaopeng Li, Ziniu Li, Wotao Yin, Xi Chen, Tianyi Lin
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-18 (更新: 2026-01-26)
备注: Accepted by ICLR 2026
💡 一句话要点
通过裁剪、熵和虚假奖励重新思考RLVR,提升LLM数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 大型语言模型 探索-利用权衡 策略熵 裁剪偏差 虚假奖励 数学推理
📋 核心要点
- 现有RLVR方法在探索-利用平衡上存在挑战,抑制探索和利用都能提升LLM推理能力,但内在机制不明。
- 论文提出通过裁剪偏差降低策略熵,使模型输出更自信,并构建奖励-错位模型解释虚假奖励的有效性。
- 实验表明,虚假奖励下的裁剪偏差能有效降低策略熵,提升模型性能,优于单纯的熵最小化方法。
📝 摘要(中文)
本文研究了可验证奖励强化学习(RLVR)中的探索-利用权衡,RLVR是一种旨在提升大型语言模型(LLM)推理能力的框架。最近的研究表明,RLVR可以通过两种看似矛盾的机制来激发LLM强大的数学推理能力:虚假奖励,通过奖励与真实结果无关的输出来抑制利用;以及熵最小化,通过将模型推向更自信和确定性的输出来抑制探索。这突显了一种令人困惑的动态:抑制利用和抑制探索都能提高推理性能,但协调这些影响的潜在原则仍然知之甚少。我们关注两个基本问题:(i)策略熵如何与性能相关,以及(ii)虚假奖励是否能带来收益,可能是通过裁剪偏差和模型污染的相互作用。我们的结果表明,虚假奖励下的裁剪偏差会降低策略熵,从而产生更自信和确定性的输出,而仅靠熵最小化不足以改进。我们进一步提出了一个奖励-错位模型,解释了为什么虚假奖励可以提高超出受污染设置的性能。我们的发现阐明了虚假奖励益处背后的机制,并为更有效的RLVR训练提供了原则。
🔬 方法详解
问题定义:现有RLVR方法在提升LLM数学推理能力时,依赖于虚假奖励和熵最小化两种看似矛盾的机制。虚假奖励通过奖励与真实结果无关的输出来抑制利用,而熵最小化则通过使模型输出更确定来抑制探索。这两种机制都能提高性能,但其内在原理和相互作用尚不明确。因此,需要深入理解策略熵与性能的关系,以及虚假奖励是否真的有效,并探究其潜在机制(如裁剪偏差和模型污染)。
核心思路:论文的核心思路是,虚假奖励的有效性并非仅仅源于模型污染,而是与裁剪偏差密切相关。裁剪偏差能够降低策略熵,使模型输出更加自信和确定,从而提高性能。此外,论文提出了一个奖励-错位模型,用于解释虚假奖励在非污染环境下的有效性。通过分析裁剪、熵和虚假奖励之间的关系,揭示了RLVR中探索-利用权衡的内在机制。
技术框架:论文主要通过实验分析和理论建模来研究RLVR的机制。实验部分,作者设计了一系列实验,考察了不同奖励策略(包括虚假奖励和真实奖励)下,裁剪偏差和熵最小化对模型性能的影响。理论部分,作者构建了一个奖励-错位模型,用于解释虚假奖励在非污染环境下的有效性。整体流程包括:设计实验环境 -> 训练RLVR模型 -> 分析实验结果 -> 构建理论模型 -> 验证理论模型。
关键创新:论文的关键创新在于:(1) 揭示了裁剪偏差在虚假奖励中的关键作用,证明其能够降低策略熵,提高模型性能。(2) 提出了奖励-错位模型,解释了虚假奖励在非污染环境下的有效性,突破了以往认为虚假奖励仅在模型污染下有效的认知。(3) 通过实验和理论分析,深入理解了RLVR中探索-利用权衡的内在机制,为更有效的RLVR训练提供了理论指导。
关键设计:论文的关键设计包括:(1) 奖励函数的设计,包括真实奖励和虚假奖励,以及它们之间的权重。(2) 裁剪策略的设计,用于限制奖励的范围,从而引入裁剪偏差。(3) 熵正则化项的设计,用于控制策略的熵值。(4) 奖励-错位模型的构建,用于模拟虚假奖励的有效性。具体参数设置和网络结构在论文中未详细描述,可能使用了标准的强化学习算法和网络结构。
🖼️ 关键图片
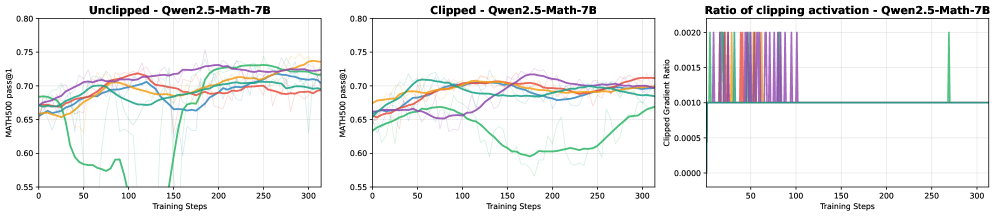
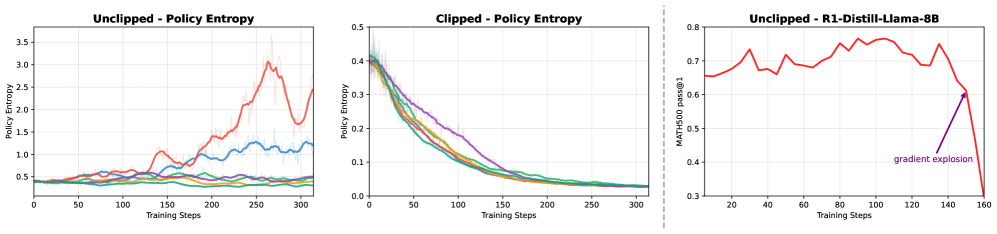

📊 实验亮点
实验结果表明,在虚假奖励下,裁剪偏差能够显著降低策略熵,从而提高LLM的数学推理性能。与单纯的熵最小化方法相比,结合虚假奖励和裁剪偏差的方法能够取得更好的效果。奖励-错位模型的分析结果也支持了虚假奖励在非污染环境下的有效性。
🎯 应用场景
该研究成果可应用于提升大型语言模型在数学推理、代码生成等领域的性能。通过更有效地利用虚假奖励和裁剪偏差,可以训练出更强大、更可靠的LLM,从而在教育、科研、金融等领域发挥更大的作用。未来的研究可以探索更复杂的奖励机制和更精细的裁剪策略,进一步提升LLM的推理能力。
📄 摘要(原文)
This paper examines the exploration-exploitation trade-off in reinforcement learning with verifiable rewards (RLVR), a framework for improving the reasoning of Large Language Models (LLMs). Recent studies suggest that RLVR can elicit strong mathematical reasoning in LLMs through two seemingly paradoxical mechanisms: spurious rewards, which suppress exploitation by rewarding outcomes unrelated to the ground truth, and entropy minimization, which suppresses exploration by pushing the model toward more confident and deterministic outputs, highlighting a puzzling dynamic: both discouraging exploitation and discouraging exploration improve reasoning performance, yet the underlying principles that reconcile these effects remain poorly understood. We focus on two fundamental questions: (i) how policy entropy relates to performance, and (ii) whether spurious rewards yield gains, potentially through the interplay of clipping bias and model contamination. Our results show that clipping bias under spurious rewards reduces policy entropy, leading to more confident and deterministic outputs, while entropy minimization alone is insufficient for improvement. We further propose a reward-misalignment model explaining why spurious rewards can enhance performance beyond contaminated settings. Our findings clarify the mechanisms behind spurious-reward benefits and provide principles for more effective RLVR training.