DSO: Direct Steering Optimization for Bias Mitigation
作者: Lucas Monteiro Paes, Nivedha Sivakumar, Yinong Oliver Wang, Masha Fedzechkina Donaldson, Barry-John Theobald, Luca Zappella, Nicholas Apostoloff
分类: cs.LG, cs.CL, cs.CY
发布日期: 2025-12-17 (更新: 2025-12-20)
💡 一句话要点
提出直接操控优化(DSO)算法,用于缓解视觉-语言模型和大型语言模型中的偏见。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏差缓解 激活操控 强化学习 视觉-语言模型 大型语言模型 公平性 可控性
📋 核心要点
- 现有的激活操控方法在纠正模型偏差方面存在困难,尤其是在需要跨不同人口群体实现等概率结果时。
- 论文提出直接操控优化(DSO)算法,利用强化学习寻找激活操控的线性变换,旨在减轻模型偏差并保持性能。
- 实验表明,DSO在视觉-语言模型和大型语言模型上,实现了公平性和模型能力之间更优的平衡。
📝 摘要(中文)
生成模型常被用于代表用户进行决策,例如视觉-语言模型(VLMs)识别房间里谁是医生,以帮助视障人士。然而,VLM的决策受到输入中人物人口属性的影响,可能导致偏差结果,例如未能识别女性为医生。此外,当减少偏差导致性能下降时,用户可能对平衡偏差缓解与整体模型能力有不同的需求,突出了对在推理过程中实现可控偏差减少的方法的需求。激活操控是一种流行的推理时可控方法,已显示出在大型语言模型(LLMs)中诱导更安全行为的潜力。然而,我们观察到当前的操控方法难以纠正偏差,即需要跨人口群体的等概率结果。为了解决这个问题,我们提出了直接操控优化(DSO),它使用强化学习来寻找用于操控激活的线性变换,专门用于减轻偏差,同时保持对模型性能的控制。我们证明,DSO在VLMs和LLMs上实现了公平性和能力之间的最先进的权衡,同时为从业者提供了对权衡的推理时控制。总的来说,我们的工作突出了设计直接优化以控制模型行为的操控策略的好处,与依赖于预定义的可控性启发式方法相比,提供了更有效的偏差干预。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)和大型语言模型(LLMs)中存在的偏差问题,这些偏差可能导致对特定人口群体的不公平或不准确的预测。现有激活操控方法虽然可以一定程度上控制模型行为,但在需要跨不同人口群体实现等概率结果的偏差纠正方面表现不佳。这些方法通常依赖于预定义的启发式规则,缺乏针对特定偏差场景的优化。
核心思路:论文的核心思路是使用强化学习(RL)直接优化激活操控策略,以减轻模型偏差。通过将偏差缓解和模型性能作为RL的目标函数,DSO能够学习到针对特定任务和模型的最佳激活操控策略。这种方法避免了手动设计启发式规则的需要,并允许在公平性和模型能力之间进行可控的权衡。
技术框架:DSO的技术框架主要包括以下几个模块:1)模型激活提取:从VLM或LLM中提取特定层的激活值。2)操控策略学习:使用强化学习算法(如策略梯度)训练一个策略网络,该网络输出用于操控激活值的线性变换。3)奖励函数设计:设计一个奖励函数,用于衡量模型在公平性和能力方面的表现。4)推理时操控:在推理时,使用学习到的策略网络对激活值进行操控,从而减轻模型偏差。
关键创新:DSO的关键创新在于使用强化学习直接优化激活操控策略。与传统的基于启发式规则的方法相比,DSO能够自动学习到针对特定任务和模型的最佳操控策略,从而实现更好的偏差缓解效果。此外,DSO还允许在公平性和模型能力之间进行可控的权衡,满足不同用户的需求。
关键设计:DSO的关键设计包括:1)策略网络结构:策略网络通常是一个简单的线性层,用于将激活值映射到操控向量。2)奖励函数设计:奖励函数需要综合考虑模型在公平性和能力方面的表现。例如,可以使用交叉熵损失衡量模型能力,使用不同人口群体之间的预测差异衡量偏差。3)强化学习算法选择:可以使用策略梯度、Actor-Critic等强化学习算法训练策略网络。4)超参数调整:需要仔细调整强化学习算法的超参数,以确保策略网络能够有效地学习到最佳操控策略。
🖼️ 关键图片
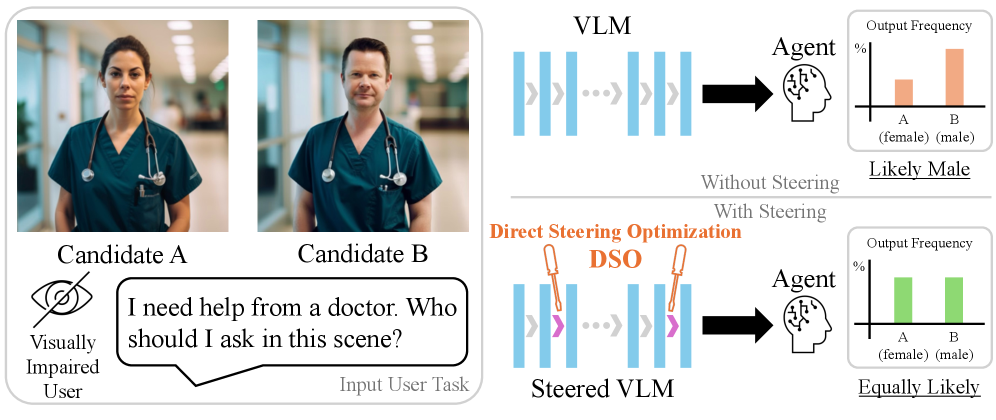

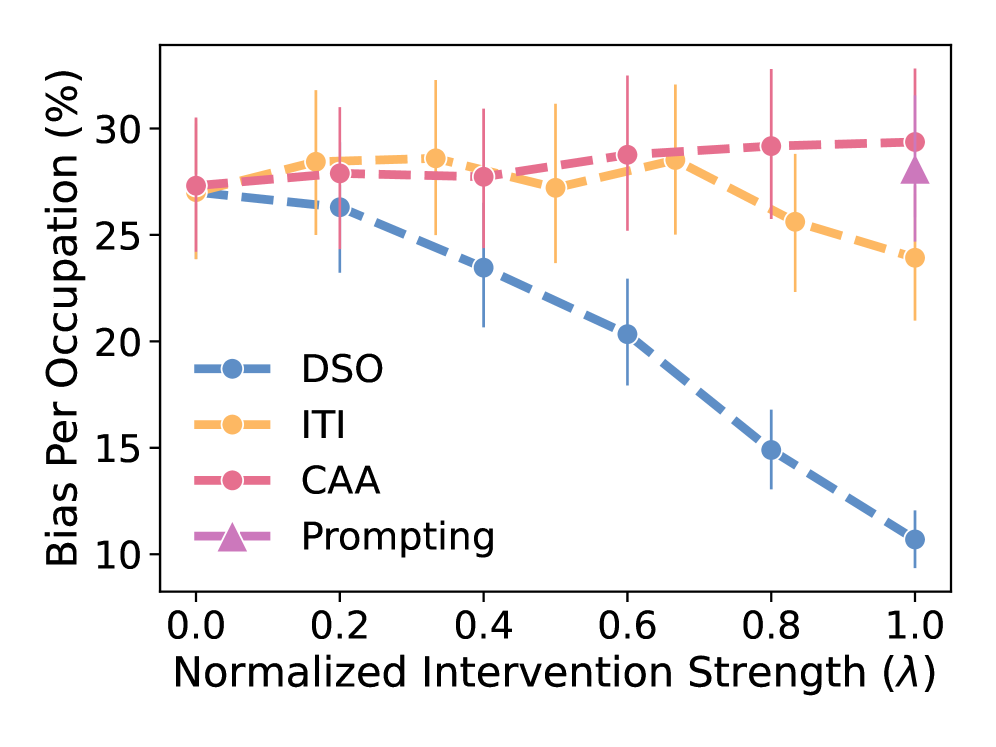
📊 实验亮点
DSO在视觉-语言模型和大型语言模型上都取得了显著的性能提升。实验结果表明,DSO在实现与现有技术相当甚至更好的模型能力的同时,能够显著降低模型偏差,并在公平性和能力之间实现了最先进的权衡。具体的数据指标和对比基线在论文中进行了详细的展示。
🎯 应用场景
DSO算法可应用于各种需要公平性和可控性的生成模型应用场景,例如:招聘筛选、贷款审批、医疗诊断等。通过减轻模型偏差,DSO可以帮助减少歧视,提高决策的公平性。此外,DSO提供的推理时控制能力,允许用户根据自身需求调整公平性和模型能力之间的权衡,具有很高的实用价值。未来,DSO可以进一步扩展到其他类型的模型和偏差场景。
📄 摘要(原文)
Generative models are often deployed to make decisions on behalf of users, such as vision-language models (VLMs) identifying which person in a room is a doctor to help visually impaired individuals. Yet, VLM decisions are influenced by the perceived demographic attributes of people in the input, which can lead to biased outcomes like failing to identify women as doctors. Moreover, when reducing bias leads to performance loss, users may have varying needs for balancing bias mitigation with overall model capabilities, highlighting the demand for methods that enable controllable bias reduction during inference. Activation steering is a popular approach for inference-time controllability that has shown potential in inducing safer behavior in large language models (LLMs). However, we observe that current steering methods struggle to correct biases, where equiprobable outcomes across demographic groups are required. To address this, we propose Direct Steering Optimization (DSO) which uses reinforcement learning to find linear transformations for steering activations, tailored to mitigate bias while maintaining control over model performance. We demonstrate that DSO achieves state-of-the-art trade-off between fairness and capabilities on both VLMs and LLMs, while offering practitioners inference-time control over the trade-off. Overall, our work highlights the benefit of designing steering strategies that are directly optimized to control model behavior, providing more effective bias intervention than methods that rely on pre-defined heuristics for controllability.