Group-Theoretic Reinforcement Learning of Dynamical Decoupling Sequences
作者: Charles Marrder, Shuo Sun, Murray J. Holland
分类: quant-ph, cs.LG, eess.SY
发布日期: 2025-12-15
💡 一句话要点
提出基于群论强化学习的动态解耦序列设计方法,无需噪声先验知识。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 动态解耦 强化学习 量子计算 Thompson群 退相干 脉冲序列 无模型学习
📋 核心要点
- 现有动态解耦方法在真实噪声环境下难以找到最优脉冲时序,需要对噪声谱有先验知识。
- 提出基于Thompson群F的强化学习动作集,使智能体能高效探索非凸优化空间,设计脉冲序列。
- 实验表明,该方法无需噪声谱知识即可学习到最小化退相的脉冲序列,适用于实时学习。
📝 摘要(中文)
动态解耦旨在通过应用精心设计的瞬时电磁脉冲序列来减轻量子比特中的相位退相干。虽然对于特定噪声状态下的最优脉冲时序存在解析解,但识别真实噪声谱下的最优时序仍然具有挑战性。我们提出了一种基于强化学习(RL)的方法来设计量子比特上的脉冲序列。我们新颖的动作集使RL智能体能够有效地探索这种固有的非凸优化空间。该动作集源自Thompson群$F$,适用于状态可以表示为有界序列的广泛的序列决策问题。我们证明了我们的RL智能体可以学习最小化退相的脉冲序列,而无需明确了解底层噪声谱。这项工作为量子比特上实时学习最优动态解耦序列开辟了可能性,这些量子比特受限于退相。我们算法的无模型性质表明,即使存在未建模的物理效应(例如脉冲误差或非高斯噪声),智能体最终也可能学习到最优脉冲序列。
🔬 方法详解
问题定义:论文旨在解决量子计算中由于环境噪声引起的量子比特退相干问题。现有的动态解耦方法通常依赖于对噪声谱的精确建模,但在实际应用中,噪声环境往往复杂且难以精确描述。因此,如何在未知或不完全了解噪声谱的情况下,设计出有效的动态解耦脉冲序列,是本研究要解决的核心问题。现有方法对噪声模型的依赖性限制了其在实际量子设备上的应用。
核心思路:论文的核心思路是利用强化学习(RL)算法,通过与量子系统环境的交互,自主学习最优的动态解耦脉冲序列。关键在于设计一个合适的动作空间,使得RL智能体能够高效地探索可能的脉冲序列,并找到能够有效抑制退相干的序列。论文选择Thompson群$F$作为动作空间的基础,因为它能够生成具有良好性质的脉冲序列,并允许智能体在序列空间中进行有效的探索。
技术框架:整体框架包括一个量子系统环境(模拟或真实量子比特),一个RL智能体,以及一个奖励函数。智能体根据当前量子比特的状态选择一个动作(即一个Thompson群$F$的元素),该动作对应于一个脉冲序列。该脉冲序列被施加到量子比特上,导致量子比特状态发生变化。然后,根据量子比特的退相干程度计算奖励值,并反馈给智能体。智能体根据奖励值更新其策略,从而学习到更优的脉冲序列。整个过程是一个迭代的强化学习过程。
关键创新:最重要的技术创新点在于使用Thompson群$F$作为RL智能体的动作空间。与传统的直接参数化脉冲序列的方法相比,基于Thompson群$F$的动作空间具有以下优势:1) 能够生成具有良好性质的脉冲序列,例如具有一定的对称性和鲁棒性;2) 能够有效地探索脉冲序列空间,避免陷入局部最优;3) 能够适应不同的噪声环境,无需对噪声谱进行精确建模。这种方法本质上是一种无模型的强化学习方法,能够学习到适应未知噪声环境的动态解耦序列。
关键设计:论文中,奖励函数的设计至关重要,它直接影响智能体的学习效果。奖励函数通常与量子比特的保真度或退相干程度相关。例如,可以使用量子比特在施加脉冲序列后的保真度作为奖励值。此外,为了加速学习过程,可以使用一些技巧,例如奖励塑造(reward shaping)或课程学习(curriculum learning)。具体的参数设置,例如学习率、折扣因子等,需要根据具体的量子系统和噪声环境进行调整。网络结构的选择也需要根据问题的复杂程度进行调整,可以使用简单的线性模型或复杂的深度神经网络。
🖼️ 关键图片
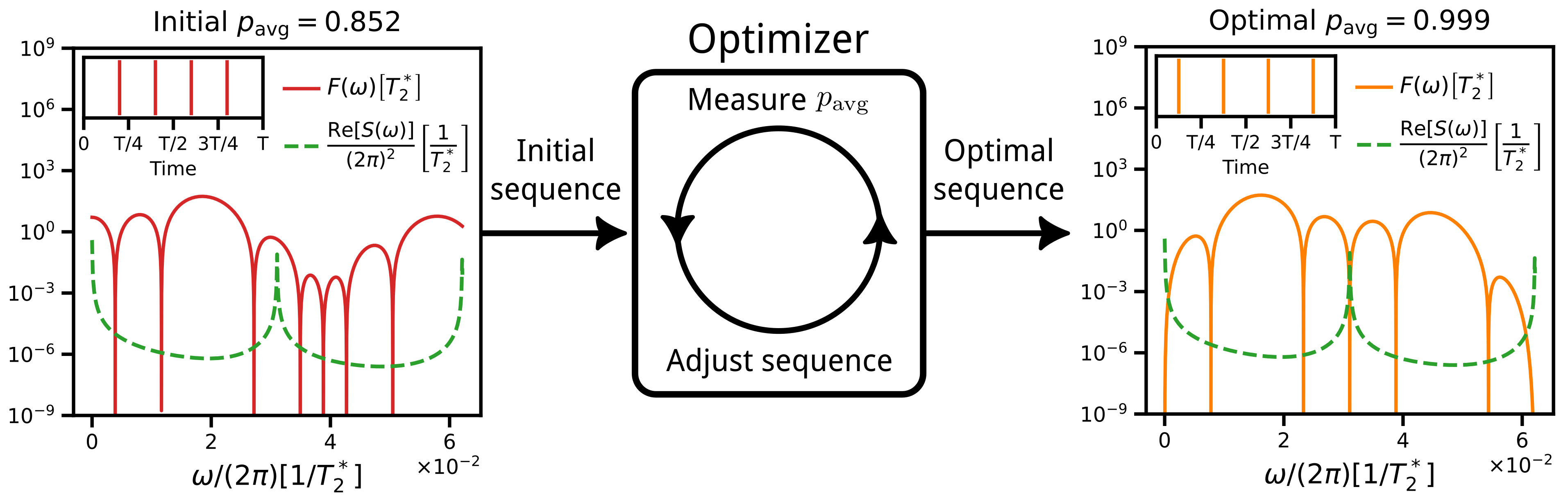

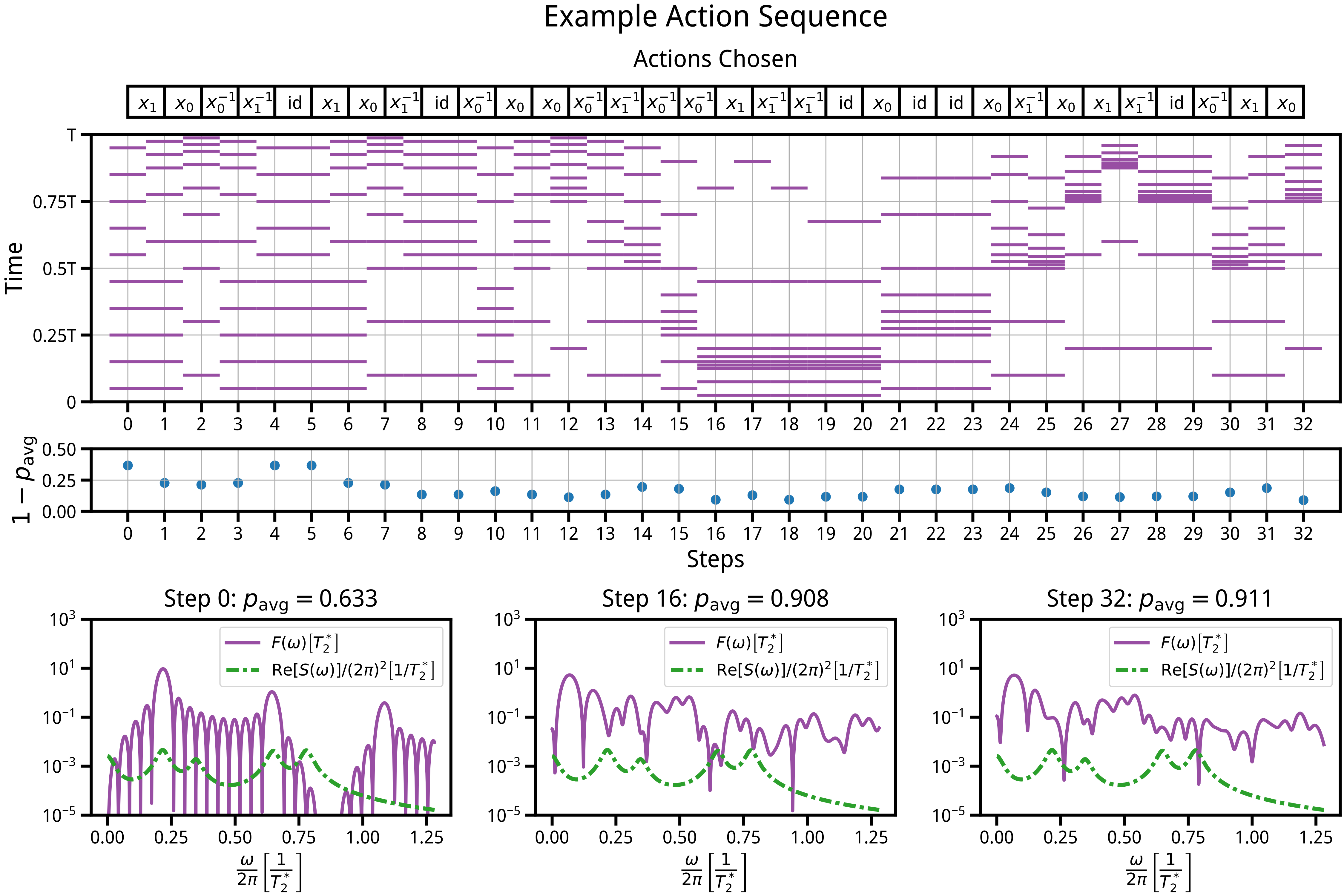
📊 实验亮点
该论文提出的方法能够在无需噪声谱先验知识的情况下,学习到有效的动态解耦脉冲序列。实验结果表明,该方法能够显著提高量子比特的相干时间,并优于传统的基于噪声模型的方法。具体的性能数据和对比基线在论文中进行了详细的展示,证明了该方法的有效性和优越性。虽然具体数值未知,但强调了优于传统方法。
🎯 应用场景
该研究成果可应用于量子计算、量子通信和量子传感等领域。通过实时学习最优的动态解耦序列,可以提高量子比特的相干时间,从而提升量子算法的性能和量子设备的稳定性。该方法尤其适用于噪声环境复杂且难以精确建模的场景,例如实际的量子计算机。未来,该方法有望应用于各种类型的量子比特,并与其他量子控制技术相结合,进一步提升量子系统的性能。
📄 摘要(原文)
Dynamical decoupling seeks to mitigate phase decoherence in qubits by applying a carefully designed sequence of effectively instantaneous electromagnetic pulses. Although analytic solutions exist for pulse timings that are optimal under specific noise regimes, identifying the optimal timings for a realistic noise spectrum remains challenging. We propose a reinforcement learning (RL)-based method for designing pulse sequences on qubits. Our novel action set enables the RL agent to efficiently navigate this inherently non-convex optimization landscape. The action set, derived from Thompson's group $F$, is applicable to a broad class of sequential decision problems whose states can be represented as bounded sequences. We demonstrate that our RL agent can learn pulse sequences that minimize dephasing without requiring explicit knowledge of the underlying noise spectrum. This work opens the possibility for real-time learning of optimal dynamical decoupling sequences on qubits which are dephasing-limited. The model-free nature of our algorithm suggests that the agent may ultimately learn optimal pulse sequences even in the presence of unmodeled physical effects, such as pulse errors or non-Gaussian noise.