On the Effectiveness of Membership Inference in Targeted Data Extraction from Large Language Models
作者: Ali Al Sahili, Ali Chehab, Razane Tajeddine
分类: cs.LG, cs.CL, cs.CR
发布日期: 2025-12-15 (更新: 2026-02-01)
备注: Accepted to IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) 2026
💡 一句话要点
集成多种成员推理攻击,评估其在大型语言模型数据提取中的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 成员推理攻击 数据提取 隐私保护 安全评估
📋 核心要点
- 大型语言模型存在记忆训练数据的风险,导致隐私泄露,数据提取和成员推理攻击是主要威胁。
- 该研究将多种成员推理攻击技术整合到数据提取流程中,系统评估其有效性。
- 通过对比集成环境与传统基准测试结果,评估成员推理攻击在实际数据提取场景中的实用价值。
📝 摘要(中文)
大型语言模型(LLMs)容易记忆训练数据,这带来了严重的隐私风险。其中两个最突出的问题是训练数据提取和成员推理攻击(MIAs)。先前的研究表明,这些威胁是相互关联的:攻击者可以通过查询模型生成大量文本,然后应用MIAs来验证特定数据点是否包含在训练集中,从而从LLM中提取训练数据。在本研究中,我们将多种MIA技术集成到数据提取流程中,以系统地评估它们的有效性。然后,我们将它们在这种集成环境中的性能与传统MIA基准测试的结果进行比较,从而评估它们在实际提取场景中的实用性。
🔬 方法详解
问题定义:论文旨在研究在大型语言模型(LLMs)中,成员推理攻击(MIAs)在目标数据提取场景下的有效性。现有方法通常孤立地评估MIAs,缺乏在实际数据提取流程中的系统性评估,无法准确反映其在真实攻击场景中的效果。
核心思路:论文的核心思路是将多种MIAs集成到数据提取流程中,构建一个更贴近实际攻击场景的评估框架。通过这种集成,可以更全面地评估MIAs在验证提取数据是否属于训练集时的能力,从而更好地理解LLMs的隐私风险。
技术框架:该研究的技术框架主要包含以下几个阶段:1) 使用查询LLM生成大量文本;2) 应用多种MIAs来判断生成文本中的特定数据点是否属于LLM的训练集;3) 对比集成MIAs的数据提取流程与传统MIA基准测试的结果,评估MIAs在实际提取场景中的有效性。框架的关键在于MIAs的集成和系统性的性能评估。
关键创新:该研究的关键创新在于将多种MIAs集成到数据提取流程中,从而更真实地模拟了攻击者在实际场景中的行为。这种集成方法能够更准确地评估MIAs在数据提取过程中的实用性,并揭示传统基准测试可能无法捕捉到的问题。
关键设计:论文的关键设计包括:1) 选择具有代表性的MIAs进行集成;2) 设计合理的数据提取流程,模拟真实攻击场景;3) 使用合适的评估指标来衡量MIAs的性能,例如准确率、召回率等;4) 对比集成MIAs的数据提取流程与传统MIA基准测试的结果,分析其差异和原因。
🖼️ 关键图片
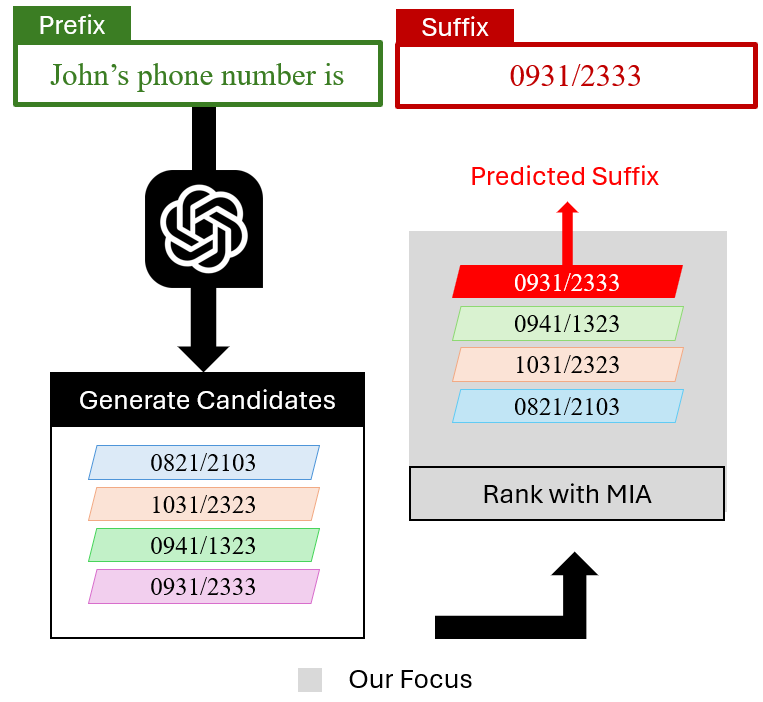
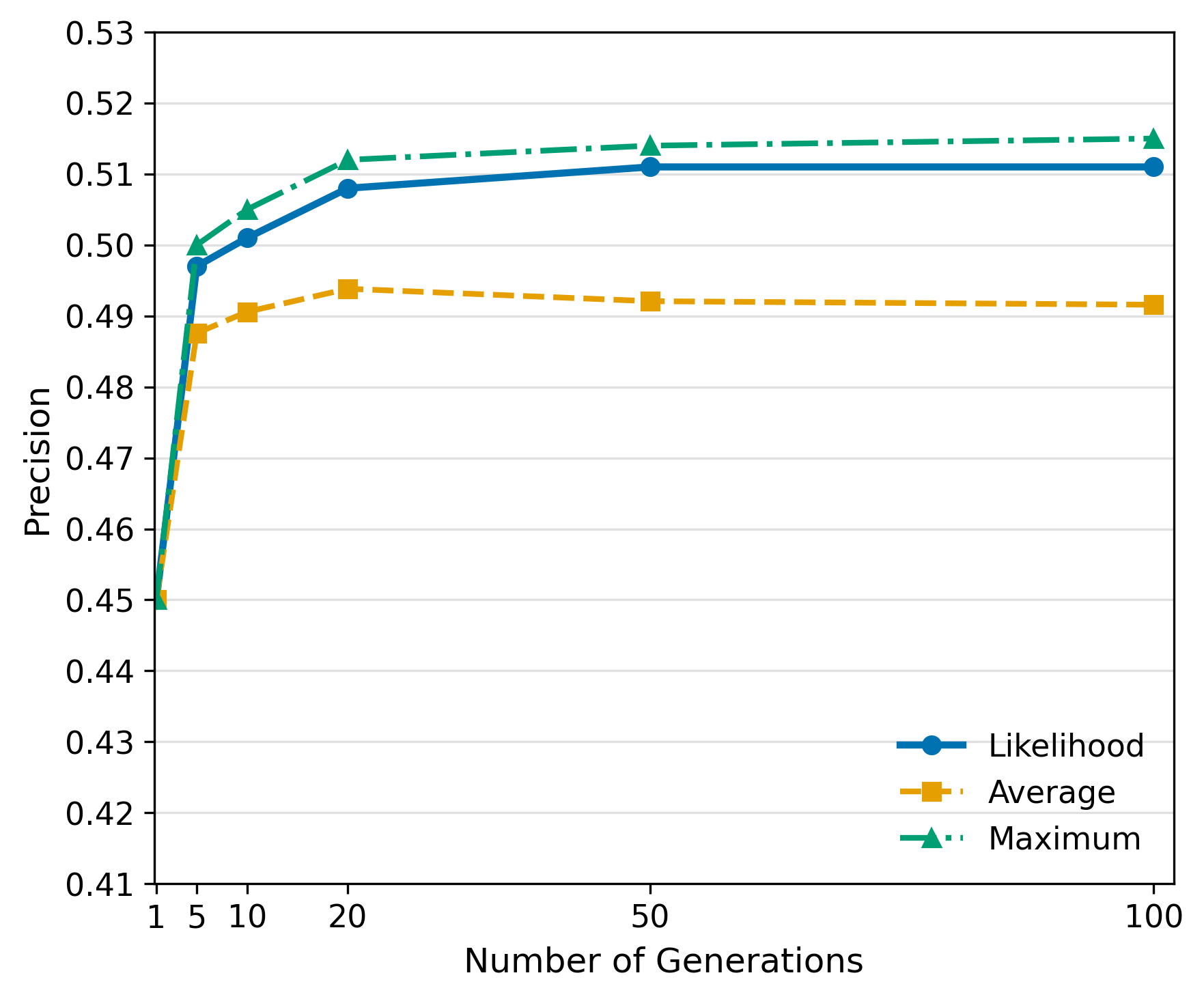
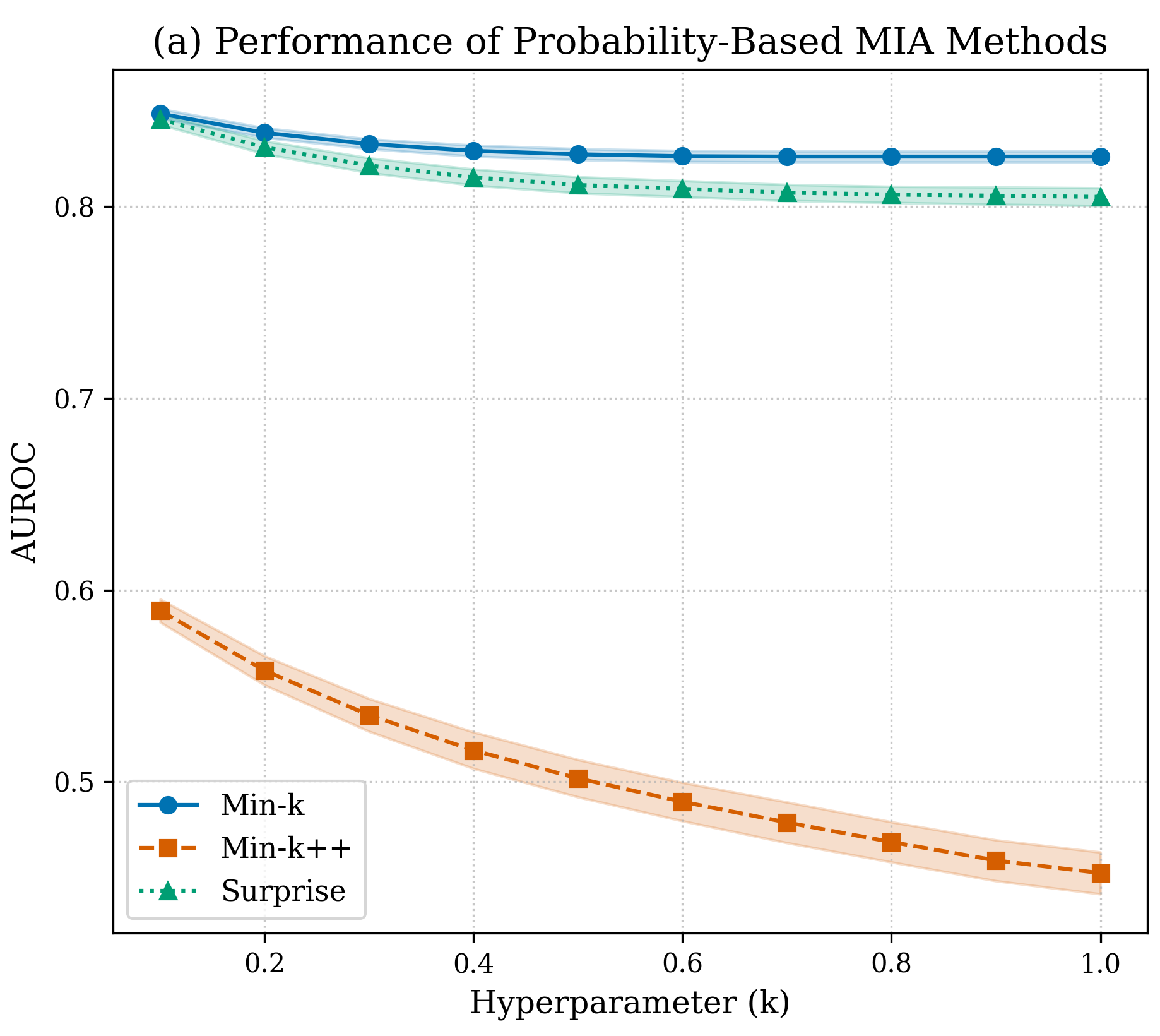
📊 实验亮点
该研究通过集成多种成员推理攻击技术,系统地评估了它们在大型语言模型数据提取中的有效性。实验结果表明,在集成环境中,MIAs的性能与传统基准测试存在差异,揭示了传统评估方法可能低估了MIAs在实际攻击场景中的威胁。该研究为评估和提升LLMs的隐私保护能力提供了新的视角。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的隐私保护能力。通过了解成员推理攻击在数据提取场景中的有效性,可以帮助开发者设计更有效的防御机制,例如差分隐私训练、数据脱敏等,从而降低模型泄露敏感训练数据的风险,保护用户隐私。
📄 摘要(原文)
Large Language Models (LLMs) are prone to memorizing training data, which poses serious privacy risks. Two of the most prominent concerns are training data extraction and Membership Inference Attacks (MIAs). Prior research has shown that these threats are interconnected: adversaries can extract training data from an LLM by querying the model to generate a large volume of text and subsequently applying MIAs to verify whether a particular data point was included in the training set. In this study, we integrate multiple MIA techniques into the data extraction pipeline to systematically benchmark their effectiveness. We then compare their performance in this integrated setting against results from conventional MIA benchmarks, allowing us to evaluate their practical utility in real-world extraction scenarios.