The Laminar Flow Hypothesis: Detecting Jailbreaks via Semantic Turbulence in Large Language Models
作者: Md. Hasib Ur Rahman
分类: cs.LG, cs.AI
发布日期: 2025-12-14
💡 一句话要点
提出层流假设,通过语义湍流检测大语言模型的越狱攻击
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 对抗性攻击 语义湍流 层流假设
📋 核心要点
- 现有防御LLM越狱攻击的方法依赖高成本的外部分类器或脆弱的词汇过滤器,忽略了模型推理过程的内在动态。
- 论文提出层流假设,认为良性输入引起LLM潜在空间的平滑转换,而恶意输入则触发混乱的“语义湍流”。
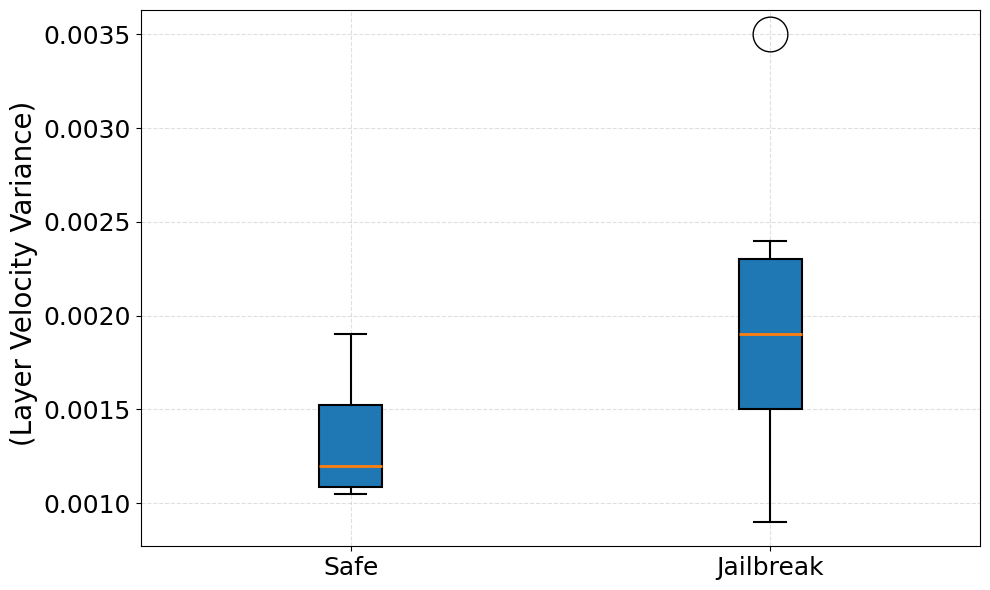
- 实验表明,语义湍流可作为轻量级实时越狱检测器,并能诊断黑盒模型的安全架构,例如区分基于内部冲突和基于反射的防御机制。
📝 摘要(中文)
随着大型语言模型(LLMs)的普及,保护它们免受对抗性“越狱”攻击的挑战日益严峻。现有的防御策略通常依赖于计算成本高昂的外部分类器或脆弱的词汇过滤器,忽略了模型推理过程的内在动态。本文提出了层流假设,该假设认为良性输入会在LLM的高维潜在空间中引起平滑、渐进的转换,而对抗性提示会触发混乱、高方差的轨迹——称为语义湍流,这是由于安全对齐和指令遵循目标之间的内部冲突造成的。通过一种新颖的零样本指标:层间余弦速度的方差,将这种现象形式化。对各种小型语言模型的实验评估揭示了惊人的诊断能力。经过RLHF对齐的Qwen2-1.5B在受到攻击时,湍流显著增加了75.4%(p小于0.001),验证了内部冲突的假设。相反,Gemma-2B的湍流减少了22.0%,体现了一种独特的、低熵的“基于反射”的拒绝机制。这些发现表明,语义湍流不仅可以作为一种轻量级的实时越狱检测器,还可以作为一种非侵入性的诊断工具,用于对黑盒模型的底层安全架构进行分类。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的越狱攻击检测问题。现有方法,如外部分类器和词汇过滤器,计算成本高或易被绕过,未能充分利用模型内部的推理过程信息。因此,需要一种更高效、更具诊断性的方法来检测和理解越狱攻击。
核心思路:论文的核心思路是观察LLM在处理不同类型的输入时,其内部状态的变化模式。作者假设,良性输入会引起模型内部状态的平滑过渡(层流),而恶意输入(越狱攻击)会引发混乱、高方差的内部状态变化(语义湍流)。这种湍流反映了模型在安全对齐和指令遵循之间的内部冲突。
技术框架:该方法主要包含以下几个阶段:1) 获取LLM在处理输入时的层间激活值;2) 计算相邻层之间激活值的余弦相似度,得到层间余弦速度;3) 计算层间余弦速度的方差,作为语义湍流的度量;4) 使用语义湍流值来区分良性输入和恶意输入,并诊断模型的安全架构。
关键创新:该方法的主要创新在于提出了“层流假设”和“语义湍流”的概念,将越狱攻击与模型内部状态的混乱程度联系起来。此外,该方法使用层间余弦速度的方差作为语义湍流的度量,提供了一种轻量级、零样本的越狱检测方法,无需训练额外的分类器。
关键设计:关键设计包括:1) 使用层间余弦速度来捕捉模型内部状态的变化;2) 使用方差来量化语义湍流的程度;3) 通过实验验证了语义湍流与越狱攻击之间的相关性;4) 分析了不同安全架构的模型在受到攻击时的语义湍流变化,揭示了其不同的防御机制。
🖼️ 关键图片


📊 实验亮点
实验结果表明,对于经过RLHF对齐的Qwen2-1.5B模型,在受到攻击时,语义湍流显著增加了75.4%(p < 0.001),验证了层流假设。而对于Gemma-2B模型,语义湍流减少了22.0%,表明其采用了一种基于反射的防御机制。这些结果表明,语义湍流可以有效地区分良性输入和恶意输入,并揭示不同模型的安全架构。
🎯 应用场景
该研究成果可应用于实时监控和防御大型语言模型的越狱攻击。通过检测语义湍流,可以及时发现并阻止恶意输入,提高LLM的安全性。此外,该方法还可以作为一种诊断工具,帮助开发者理解和改进LLM的安全架构,例如评估不同安全对齐策略的效果,并识别潜在的安全漏洞。未来,该方法可以扩展到其他类型的对抗性攻击检测,并与其他防御机制相结合,构建更强大的LLM安全体系。
📄 摘要(原文)
As Large Language Models (LLMs) become ubiquitous, the challenge of securing them against adversarial "jailbreaking" attacks has intensified. Current defense strategies often rely on computationally expensive external classifiers or brittle lexical filters, overlooking the intrinsic dynamics of the model's reasoning process. In this work, the Laminar Flow Hypothesis is introduced, which posits that benign inputs induce smooth, gradual transitions in an LLM's high-dimensional latent space, whereas adversarial prompts trigger chaotic, high-variance trajectories - termed Semantic Turbulence - resulting from the internal conflict between safety alignment and instruction-following objectives. This phenomenon is formalized through a novel, zero-shot metric: the variance of layer-wise cosine velocity. Experimental evaluation across diverse small language models reveals a striking diagnostic capability. The RLHF-aligned Qwen2-1.5B exhibits a statistically significant 75.4% increase in turbulence under attack (p less than 0.001), validating the hypothesis of internal conflict. Conversely, Gemma-2B displays a 22.0% decrease in turbulence, characterizing a distinct, low-entropy "reflex-based" refusal mechanism. These findings demonstrate that Semantic Turbulence serves not only as a lightweight, real-time jailbreak detector but also as a non-invasive diagnostic tool for categorizing the underlying safety architecture of black-box models.