On Harnessing Idle Compute at the Edge for Foundation Model Training
作者: Leyang Xue, Meghana Madhyastha, Myungjin Lee, Amos Storkey, Randal Burns, Mahesh K. Marina
分类: cs.DC, cs.LG
发布日期: 2025-12-13
备注: Extended abstract version of this paper appeared in ACM MobiCom 2025
💡 一句话要点
Cleave:利用边缘空闲算力高效训练大模型,媲美云端性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 联邦学习 分布式训练 大模型训练 张量并行 参数服务器 设备异构性
📋 核心要点
- 现有边缘训练方法在性能、扩展性、内存限制、通信开销和设备异构性等方面存在诸多挑战,难以满足大模型训练需求。
- Cleave通过选择性混合张量并行划分训练操作,并结合参数服务器框架,有效应对内存限制和通信瓶颈,实现高效训练。
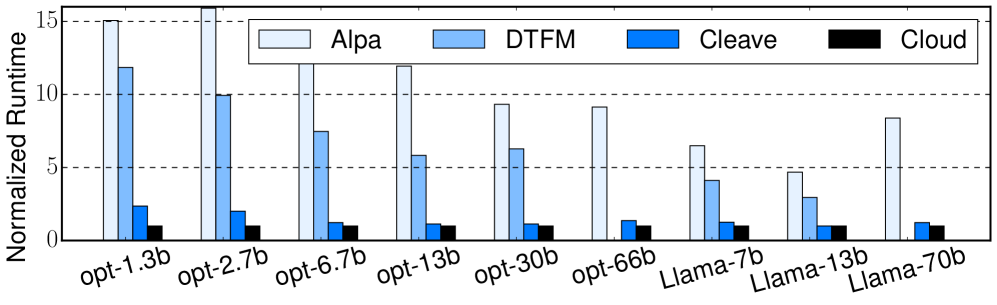
- 实验表明,Cleave在模型扩展性、设备支持数量、训练速度和故障恢复速度等方面均优于现有边缘训练方法,媲美云端性能。
📝 摘要(中文)
当前,大模型训练生态高度中心化,受限于拥有大规模云计算数据中心的运营商。利用边缘设备的空闲算力进行去中心化的大模型训练,提供了一种更民主的选择。然而,现有的边缘训练方法存在不足:难以达到云端训练的性能,模型扩展性受限,超出设备内存容量,通信开销过大,并且无法令人满意地处理设备异构性和动态性。我们提出了一种新的范式Cleave,通过一种新颖的选择性混合张量并行方法,精细地划分训练操作。结合以参数服务器为中心的训练框架,Cleave解决了设备内存限制,避免了通信瓶颈,从而实现了与云端相媲美的大模型高效训练。此外,通过成本优化模型来指导设备选择和训练工作负载分配,Cleave有效地考虑了设备异构性和动态变化。评估表明,Cleave通过高效扩展到更大的模型和数千个设备,与基于云的GPU训练相匹配,支持的设备数量比基线边缘训练方法多达8倍。在每批次训练时间方面,Cleave优于最先进的边缘训练方法高达10倍,并能有效处理设备故障,恢复速度比以前的方法快至少100倍。
🔬 方法详解
问题定义:论文旨在解决边缘设备上训练大型模型时面临的资源限制和效率问题。现有边缘训练方法在处理大规模模型时,面临着设备内存不足、通信开销过大、设备异构性以及设备动态加入/退出等挑战,导致训练效率低下,难以与云端训练相媲美。
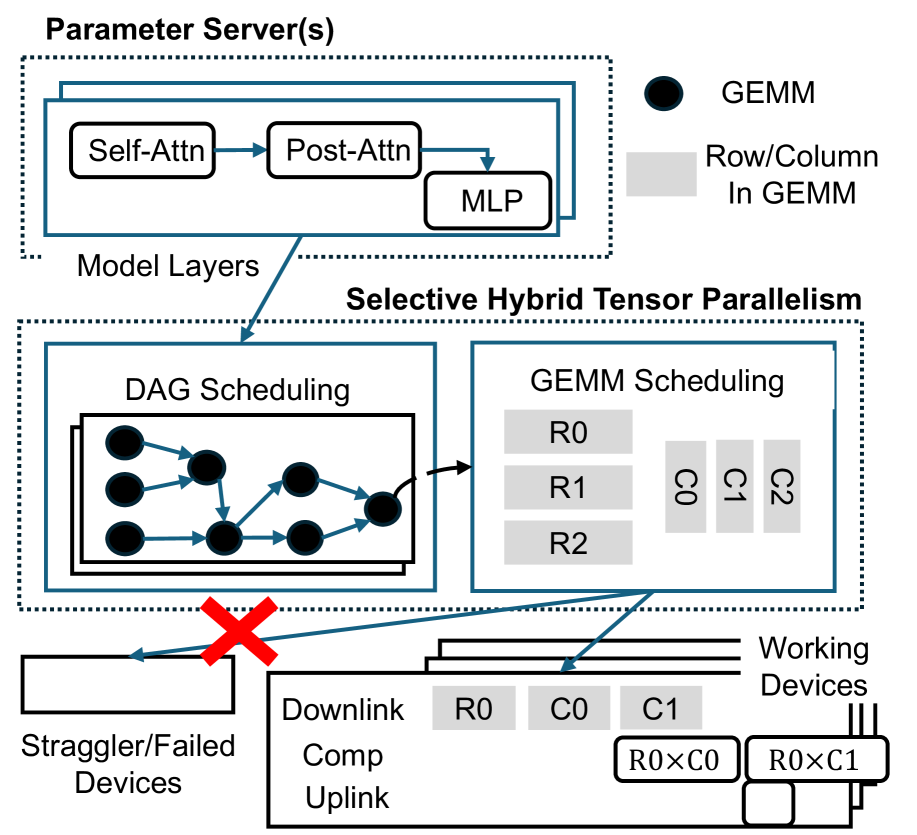
核心思路:Cleave的核心思路是通过精细地划分训练任务,并优化通信策略,充分利用边缘设备的空闲算力。具体来说,它采用了一种选择性混合张量并行方法,将训练操作分解成更小的块,并智能地分配到不同的设备上。同时,利用参数服务器架构,集中管理模型参数,减少设备间的直接通信,从而降低通信开销。
技术框架:Cleave的整体框架包含以下几个主要模块:1) 任务划分模块:负责将训练任务分解成细粒度的操作块,并根据设备资源情况进行分配。2) 参数服务器模块:维护全局模型参数,并负责参数的同步和更新。3) 设备管理模块:监控设备状态,处理设备加入/退出事件,并动态调整任务分配。4) 成本优化模块:根据设备性能和网络状况,优化设备选择和任务分配策略,以最小化训练时间和成本。
关键创新:Cleave的关键创新在于其选择性混合张量并行方法。与传统的张量并行方法不同,Cleave能够根据不同层的计算特性,选择最合适的并行策略,从而最大限度地利用设备资源。此外,Cleave的成本优化模型能够有效地处理设备异构性和动态性,保证训练的稳定性和效率。
关键设计:Cleave的关键设计包括:1) 选择性张量并行策略:根据不同层的计算复杂度选择不同的并行方式(例如,数据并行、模型并行、流水线并行)。2) 参数服务器架构:采用分层参数服务器结构,减少通信延迟。3) 成本模型:综合考虑设备计算能力、网络带宽和设备可用性,动态调整任务分配。
🖼️ 关键图片

📊 实验亮点
Cleave的实验结果表明,其性能显著优于现有的边缘训练方法。在相同的硬件条件下,Cleave能够支持比基线方法多8倍的设备数量,并且在每批次训练时间上,Cleave比最先进的边缘训练方法快10倍。此外,Cleave的故障恢复速度也比以前的方法快100倍以上,保证了训练的稳定性和可靠性。Cleave的性能可以与云端GPU训练相媲美。
🎯 应用场景
Cleave技术可应用于联邦学习、分布式训练等场景,尤其适用于对数据隐私有较高要求的应用。例如,在医疗健康领域,可以利用Cleave在边缘设备上训练医疗影像分析模型,保护患者隐私的同时,提升模型训练效率。此外,在自动驾驶、智能家居等领域,Cleave也有望发挥重要作用,实现更智能、更高效的边缘计算。
📄 摘要(原文)
The ecosystem behind foundation model development today is highly centralized and limited to large-scale cloud data center operators: training foundation models is costly, needing immense compute resources. Decentralized foundation model training across edge devices, leveraging their spare compute, promises a democratized alternative. However, existing edge-training approaches fall short: they struggle to match cloud-based training performance, exhibit limited scalability with model size, exceed device memory capacity, and have prohibitive communication overhead. They also fail to satisfactorily handle device heterogeneity and dynamism. We introduce a new paradigm, Cleave, which finely partitions training operations through a novel selective hybrid tensor parallelism method. Together with a parameter server centric training framework, Cleave copes with device memory limits and avoids communication bottlenecks, thereby enabling efficient training of large models on par with the cloud. Further, with a cost optimization model to guide device selection and training workload distribution, Cleave effectively accounts for device heterogeneity and churn. Our evaluations show that Cleave matches cloud-based GPU training by scaling efficiently to larger models and thousands of devices, supporting up to 8x more devices than baseline edge-training approaches. It outperforms state-of-the-art edge training methods by up to a factor of 10 in per-batch training time and efficiently handles device failures, achieving at least 100x faster recovery than prior methods.