TS-DP: Reinforcement Speculative Decoding For Temporal Adaptive Diffusion Policy Acceleration
作者: Ye Li, Jiahe Feng, Yuan Meng, Kangye Ji, Chen Tang, Xinwan Wen, Shutao Xia, Zhi Wang, Wenwu Zhu
分类: cs.LG, cs.AI
发布日期: 2025-12-13
💡 一句话要点
提出TS-DP,通过强化学习推测解码加速时序自适应扩散策略,实现实时具身控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散策略 推测解码 强化学习 时序自适应 具身控制
📋 核心要点
- 扩散策略在具身控制中计算成本高昂,现有加速方法难以适应动态环境下的任务难度变化。
- TS-DP通过蒸馏Transformer drafter模仿基础模型,并使用强化学习调度器动态调整推测参数,实现时序自适应。
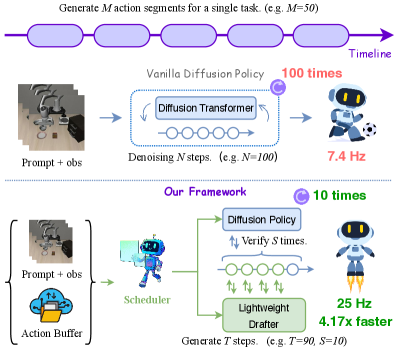
- 实验表明,TS-DP在多种具身环境中实现了高达4.17倍的推理加速,并达到25Hz的实时控制频率。
📝 摘要(中文)
扩散策略(DP)在具身控制中表现出色,但由于多次迭代去噪步骤,导致推理延迟高和计算成本高。具身任务的时序复杂性需要一种动态和自适应的计算模式。量化等静态和有损的加速方法无法处理这种动态的具身任务,而推测解码为DP提供了一种无损和自适应的替代方案,但尚未被充分探索。本文提出了时序感知强化学习推测扩散策略(TS-DP),这是第一个为DP启用具有时序自适应性的推测解码的框架。首先,为了处理任务难度随时间变化的动态环境,我们提炼了一个基于Transformer的drafter来模仿基础模型,并替换其昂贵的去噪调用。其次,基于强化学习的调度器通过调整推测参数来进一步适应随时间变化的任务难度,以保持准确性,同时提高效率。在各种具身环境中的大量实验表明,TS-DP实现了高达4.17倍的更快推理,超过94%的草稿被接受,达到25 Hz的推理频率,并实现了实时的基于扩散的控制,而不会降低性能。
🔬 方法详解
问题定义:扩散策略(DP)在具身控制任务中表现优异,但其迭代去噪过程导致推理速度慢,计算成本高。现有的加速方法,如量化,是静态的且可能引入信息损失,无法有效应对具身控制任务中动态变化的任务难度。推测解码是一种潜在的加速方法,但如何将其应用于DP并使其适应时序变化的具身环境是一个挑战。
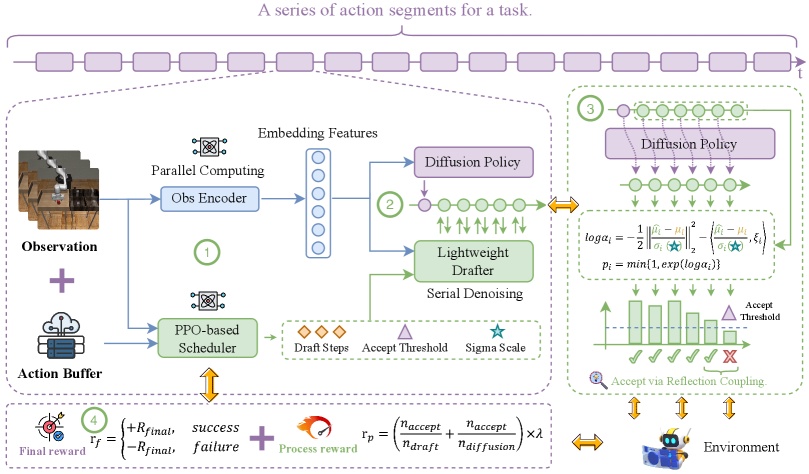
核心思路:TS-DP的核心思路是利用推测解码的思想,通过一个轻量级的“drafter”模型来预测扩散过程的中间步骤,并由一个更强大的“base model”进行验证。为了适应时序变化的任务难度,TS-DP引入了基于强化学习的调度器,动态调整推测解码的参数,从而在保证精度的前提下最大化加速效果。这种设计允许系统根据当前任务的复杂程度自适应地分配计算资源。
技术框架:TS-DP框架主要包含三个模块:1) Base Model: 原始的扩散策略模型,负责提供高质量的去噪结果。2) Drafter Model: 一个轻量级的Transformer模型,通过蒸馏学习模仿Base Model的去噪过程,用于快速生成候选的去噪结果。3) RL-based Scheduler: 基于强化学习的调度器,根据当前环境状态和任务难度,动态调整推测解码的参数,例如推测步数。整体流程是,Drafter Model首先生成一系列推测的去噪结果,然后Base Model验证这些结果,如果验证通过,则加速推理过程;否则,使用Base Model的输出进行修正。
关键创新:TS-DP的关键创新在于将推测解码与强化学习相结合,实现了时序自适应的扩散策略加速。传统的推测解码方法通常采用固定的参数,无法根据任务难度动态调整计算量。TS-DP通过RL-based Scheduler,能够根据环境状态和任务难度,自适应地调整推测解码的参数,从而在保证精度的前提下最大化加速效果。这是首次将强化学习应用于扩散策略的推测解码中。
关键设计:Drafter Model采用Transformer架构,通过蒸馏学习模仿Base Model的输出。RL-based Scheduler使用策略梯度算法进行训练,其状态空间包括环境状态、任务难度等信息,动作空间包括推测步数等参数。奖励函数的设计目标是最大化推理速度,同时保证精度。具体而言,奖励函数可以包括推理时间的负值和验证通过的推测步数的正值。损失函数包括Drafter Model的蒸馏损失和RL-based Scheduler的策略梯度损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TS-DP在多种具身环境中实现了显著的推理加速,最高可达4.17倍。同时,TS-DP保持了较高的精度,超过94%的推测草稿被接受。TS-DP能够达到25Hz的推理频率,实现了实时的基于扩散的控制,而不会降低性能。这些结果表明,TS-DP是一种有效的扩散策略加速方法,具有很强的实用价值。
🎯 应用场景
TS-DP具有广泛的应用前景,尤其是在需要实时控制的具身智能任务中,例如机器人操作、自动驾驶、虚拟现实等。通过加速扩散策略的推理速度,TS-DP可以使这些应用更加实用和高效。此外,TS-DP的时序自适应性使其能够更好地应对动态变化的环境,提高系统的鲁棒性和适应性。
📄 摘要(原文)
Diffusion Policy (DP) excels in embodied control but suffers from high inference latency and computational cost due to multiple iterative denoising steps. The temporal complexity of embodied tasks demands a dynamic and adaptable computation mode. Static and lossy acceleration methods, such as quantization, fail to handle such dynamic embodied tasks, while speculative decoding offers a lossless and adaptive yet underexplored alternative for DP. However, it is non-trivial to address the following challenges: how to match the base model's denoising quality at lower cost under time-varying task difficulty in embodied settings, and how to dynamically and interactively adjust computation based on task difficulty in such environments. In this paper, we propose Temporal-aware Reinforcement-based Speculative Diffusion Policy (TS-DP), the first framework that enables speculative decoding for DP with temporal adaptivity. First, to handle dynamic environments where task difficulty varies over time, we distill a Transformer-based drafter to imitate the base model and replace its costly denoising calls. Second, an RL-based scheduler further adapts to time-varying task difficulty by adjusting speculative parameters to maintain accuracy while improving efficiency. Extensive experiments across diverse embodied environments demonstrate that TS-DP achieves up to 4.17 times faster inference with over 94% accepted drafts, reaching an inference frequency of 25 Hz and enabling real-time diffusion-based control without performance degradation.