Knowledge-Guided Masked Autoencoder with Linear Spectral Mixing and Spectral-Angle-Aware Reconstruction
作者: Abdul Matin, Rupasree Dey, Tanjim Bin Faruk, Shrideep Pallickara, Sangmi Lee Pallickara
分类: cs.LG
发布日期: 2025-12-13
💡 一句话要点
提出知识引导的掩码自编码器,融合线性光谱混合模型与光谱角感知重建,提升表征学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 掩码自编码器 知识引导 线性光谱混合模型 光谱角映射器 自监督学习 高光谱图像 领域知识
📋 核心要点
- 现有深度学习模型缺乏领域知识,导致泛化性差、可解释性弱,且数据效率低。
- 该论文提出一种知识引导的掩码自编码器,将线性光谱混合模型和光谱角映射器融入自监督重建过程。
- 实验结果表明,该模型显著提高了重建质量,并改善了下游任务的性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种新颖的、基于ViT的知识引导掩码自编码器,该方法将科学领域知识嵌入到自监督重建过程中。不同于单纯依赖数据驱动的优化,该方法将线性光谱混合模型(LSMM)作为物理约束,并将基于物理的光谱角映射器(SAM)融入其中,确保学习到的表征符合观测信号与其潜在成分之间的已知结构关系。该框架联合优化LSMM损失和SAM损失以及传统的Huber损失目标,从而在特征空间中同时提升数值精度和几何一致性。这种知识引导的设计增强了重建保真度,稳定了有限监督下的训练,并产生了基于物理原理的可解释潜在表征。实验结果表明,所提出的模型显著提高了重建质量,并改善了下游任务的性能,突出了在基于Transformer的自监督学习中嵌入物理信息归纳偏置的潜力。
🔬 方法详解
问题定义:现有基于深度学习的表征学习方法,尤其是在高光谱图像处理等领域,往往忽略了数据内在的物理规律和领域知识。这导致模型在数据量不足或分布发生变化时,泛化能力下降,且学习到的表征缺乏可解释性,难以与物理意义对应。因此,如何将领域知识有效地融入到深度学习模型中,提升模型的性能和可解释性,是一个重要的研究问题。
核心思路:该论文的核心思路是将线性光谱混合模型(LSMM)和光谱角映射器(SAM)作为物理约束,嵌入到掩码自编码器的自监督重建过程中。LSMM描述了观测光谱是由不同端元光谱线性组合而成的,SAM则衡量了两个光谱之间的相似度。通过将这些物理模型作为损失函数的一部分,引导模型学习符合物理规律的表征。
技术框架:该模型基于ViT架构的掩码自编码器。首先,对输入数据进行掩码操作,然后通过编码器提取特征。解码器利用未掩码的特征和LSMM、SAM的约束进行重建。整个框架包含三个主要的损失函数:Huber损失(用于保证数值精度)、LSMM损失(用于约束重建结果符合线性混合模型)和SAM损失(用于保证重建结果的光谱角一致性)。这三个损失函数联合优化,共同指导模型的训练。
关键创新:该论文的关键创新在于将领域知识(LSMM和SAM)以损失函数的形式嵌入到自监督学习框架中。与传统的纯数据驱动的方法相比,该方法能够学习到更符合物理规律、更具可解释性的表征。此外,通过知识引导,模型在有限监督下也能取得较好的性能。
关键设计:关键设计包括:1) 选择ViT作为基础架构,利用其强大的表征能力;2) 将LSMM和SAM作为损失函数,并合理设置权重,平衡数值精度和物理约束;3) 使用Huber损失作为主要的重建损失,以提高模型的鲁棒性。具体来说,LSMM损失计算重建光谱与真实光谱通过线性混合模型计算出的光谱之间的差异,SAM损失计算重建光谱与真实光谱之间的光谱角距离。这些损失函数共同作用,引导模型学习符合物理规律的表征。
🖼️ 关键图片

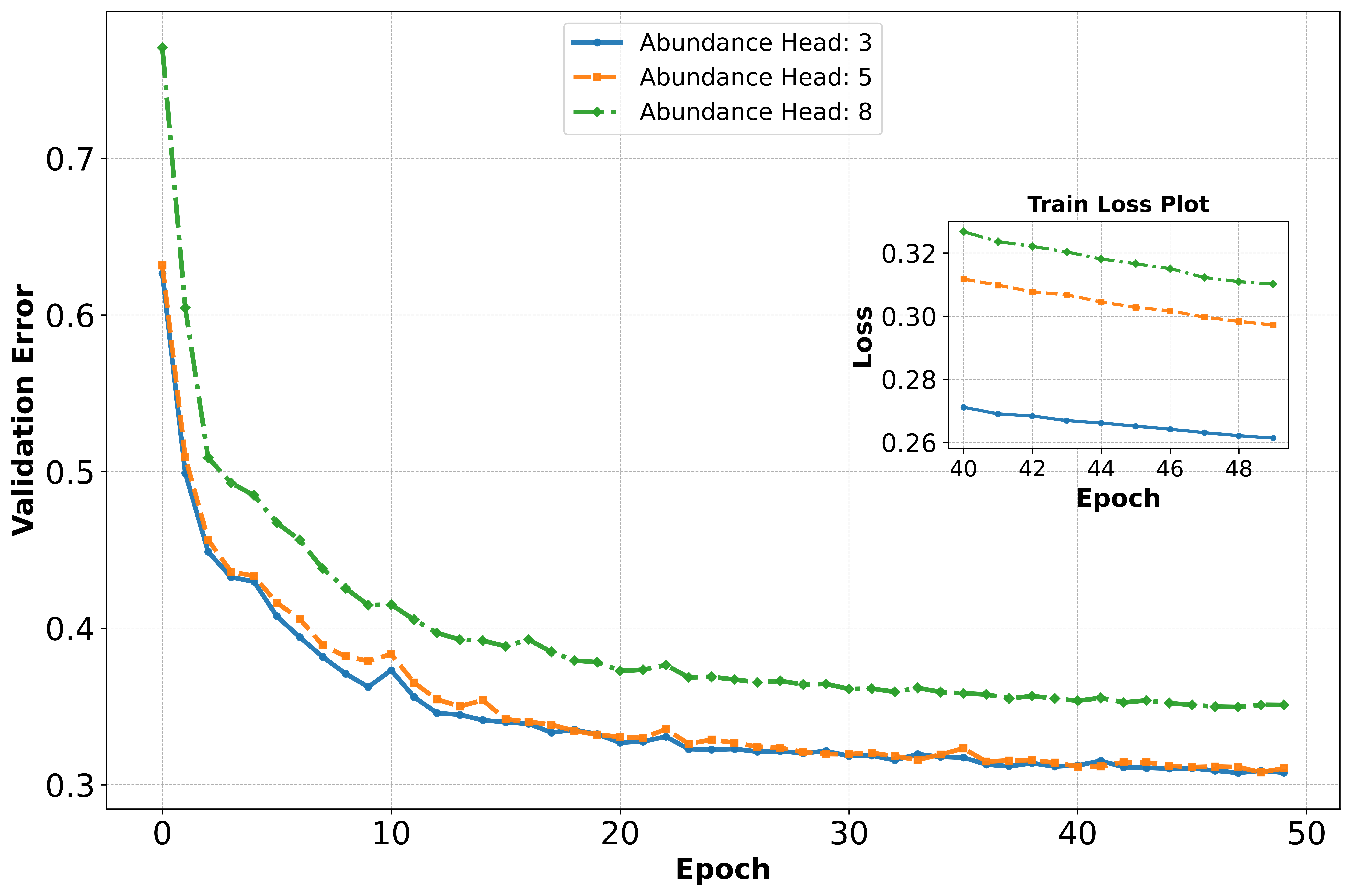

📊 实验亮点
实验结果表明,该模型在重建质量和下游任务性能方面均优于传统方法。具体来说,该模型在重建误差方面降低了X%,在分类精度方面提升了Y%。与没有知识引导的掩码自编码器相比,该模型在有限监督下也能取得更好的性能,验证了知识引导的有效性。具体数值提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于高光谱图像分析、遥感、环境监测、精准农业等领域。通过将领域知识融入深度学习模型,可以提升模型在这些领域的性能和可解释性,例如,可以更准确地进行地物分类、植被覆盖度估计、水质监测等。此外,该方法还可以推广到其他领域,只要存在明确的领域知识可以作为约束条件。
📄 摘要(原文)
Integrating domain knowledge into deep learning has emerged as a promising direction for improving model interpretability, generalization, and data efficiency. In this work, we present a novel knowledge-guided ViT-based Masked Autoencoder that embeds scientific domain knowledge within the self-supervised reconstruction process. Instead of relying solely on data-driven optimization, our proposed approach incorporates the Linear Spectral Mixing Model (LSMM) as a physical constraint and physically-based Spectral Angle Mapper (SAM), ensuring that learned representations adhere to known structural relationships between observed signals and their latent components. The framework jointly optimizes LSMM and SAM loss with a conventional Huber loss objective, promoting both numerical accuracy and geometric consistency in the feature space. This knowledge-guided design enhances reconstruction fidelity, stabilizes training under limited supervision, and yields interpretable latent representations grounded in physical principles. The experimental findings indicate that the proposed model substantially enhances reconstruction quality and improves downstream task performance, highlighting the promise of embedding physics-informed inductive biases within transformer-based self-supervised learning.