BOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models
作者: Zhengyang Wang, Ziyue Liu, Ruijie Zhang, Avinash Maurya, Paul Hovland, Bogdan Nicolae, Franck Cappello, Zheng Zhang
分类: cs.LG, cs.DC
发布日期: 2025-12-13
💡 一句话要点
BOOST:面向低秩大语言模型的瓶颈优化可扩展训练框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩模型 瓶颈架构 张量并行 分布式训练 大语言模型 模型训练加速 GPU优化
📋 核心要点
- 现有Transformer模型训练受限于计算和通信成本,尤其是在大规模预训练中,扩展性面临挑战。
- BOOST框架提出瓶颈感知张量并行,并结合多种优化策略,专门为低秩瓶颈架构设计,提升训练效率。
- 实验表明,BOOST在多种低秩模型上优于全秩模型和朴素3D并行低秩模型,加速比分别达到1.46-1.91倍和1.87-2.27倍。
📝 摘要(中文)
Transformer模型预训练的规模受到日益增长的计算和通信成本的限制。低秩瓶颈架构提供了一种有前景的解决方案,可以在对准确性影响最小的情况下显著减少训练时间和内存占用。尽管算法效率很高,但瓶颈架构在标准张量并行下扩展性较差。简单地应用为全秩方法设计的3D并行会导致过度的通信和较差的GPU利用率。为了解决这个限制,我们提出了BOOST,这是一个为大规模低秩瓶颈架构量身定制的高效训练框架。BOOST引入了一种新颖的瓶颈感知张量并行,并结合了在线RMSNorm、线性层分组和低秩激活检查点等优化,以实现端到端训练加速。在不同低秩瓶颈架构上的评估表明,BOOST比全秩模型基线实现了1.46-1.91倍的加速,比使用朴素集成的3D并行的低秩模型实现了1.87-2.27倍的加速,同时提高了GPU利用率并降低了通信开销。
🔬 方法详解
问题定义:论文旨在解决大规模低秩瓶颈Transformer模型训练中,标准张量并行导致的通信开销过大和GPU利用率低下的问题。现有为全秩模型设计的3D并行策略,直接应用于低秩模型时,无法充分发挥低秩结构的优势,导致训练效率低下。
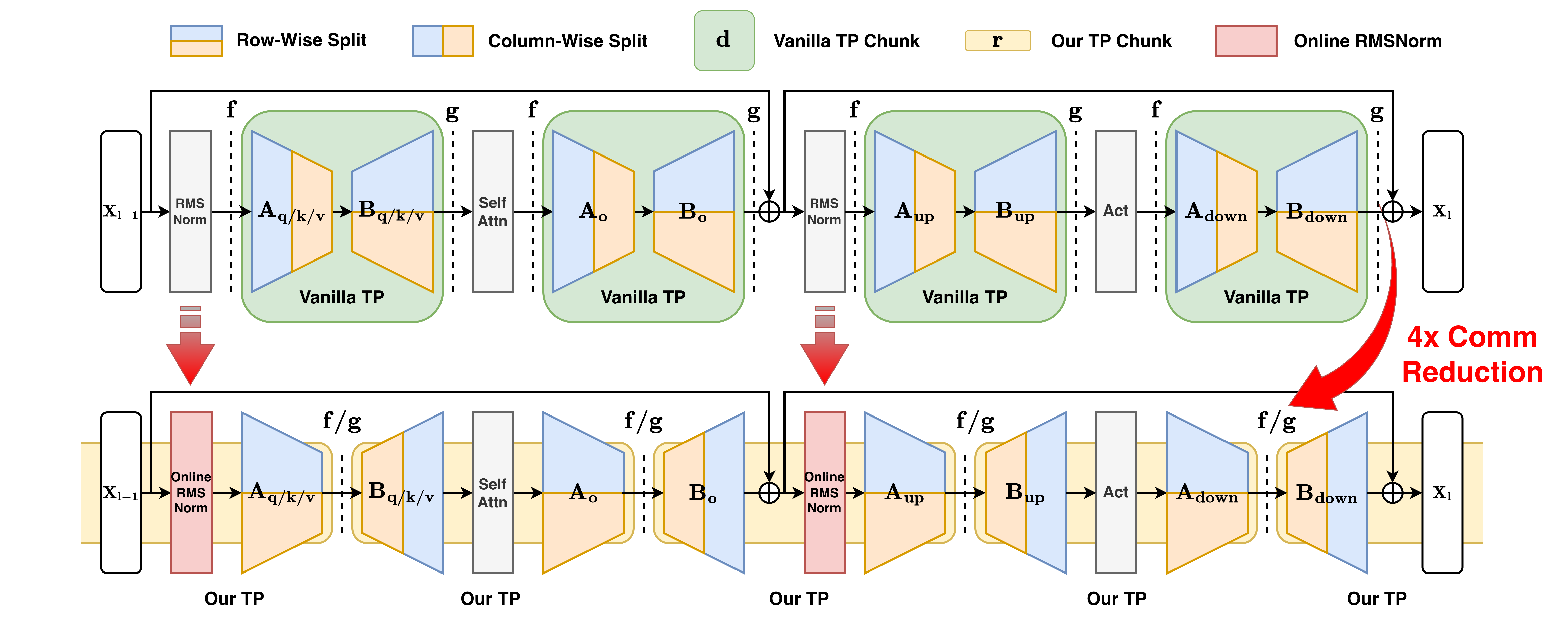
核心思路:论文的核心思路是设计一种专门针对低秩瓶颈架构的张量并行策略,即瓶颈感知张量并行。该策略充分利用低秩结构的特性,减少通信量,提高GPU利用率。同时,结合其他优化技术,进一步提升端到端训练速度。
技术框架:BOOST框架主要包含以下几个关键模块:1) 瓶颈感知张量并行:针对低秩瓶颈层设计,优化数据在不同GPU上的分布和通信方式。2) 在线RMSNorm:在训练过程中动态调整RMSNorm的参数,提高训练稳定性。3) 线性层分组:将多个线性层组合在一起进行计算,减少kernel launch的开销。4) 低秩激活检查点:只对低秩激活进行checkpoint,减少内存占用。
关键创新:最重要的技术创新点是瓶颈感知张量并行。与传统的张量并行方法不同,该方法充分考虑了低秩结构的特点,通过优化数据分布和通信策略,显著降低了通信开销,提高了GPU利用率。
关键设计:论文中没有明确给出关键参数设置的具体数值,但强调了在线RMSNorm的使用,这有助于稳定训练过程。线性层分组通过减少kernel launch开销来提升效率。低秩激活检查点则通过只保存低秩激活来降低内存占用,从而允许更大的batch size或更大的模型规模。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BOOST框架在不同的低秩瓶颈架构上均取得了显著的加速效果。与全秩模型基线相比,BOOST实现了1.46-1.91倍的加速;与朴素集成的3D并行低秩模型相比,BOOST实现了1.87-2.27倍的加速。同时,BOOST还提高了GPU利用率并降低了通信开销。
🎯 应用场景
BOOST框架可应用于大规模低秩语言模型的预训练和微调,尤其适用于资源受限的场景。通过降低训练成本和提高训练效率,BOOST能够加速低秩模型的开发和部署,推动自然语言处理技术在各个领域的应用,例如智能客服、机器翻译、文本生成等。
📄 摘要(原文)
The scale of transformer model pre-training is constrained by the increasing computation and communication cost. Low-rank bottleneck architectures offer a promising solution to significantly reduce the training time and memory footprint with minimum impact on accuracy. Despite algorithmic efficiency, bottleneck architectures scale poorly under standard tensor parallelism. Simply applying 3D parallelism designed for full-rank methods leads to excessive communication and poor GPU utilization. To address this limitation, we propose BOOST, an efficient training framework tailored for large-scale low-rank bottleneck architectures. BOOST introduces a novel Bottleneck-aware Tensor Parallelism, and combines optimizations such as online-RMSNorm, linear layer grouping, and low-rank activation checkpointing to achieve end-to-end training speedup. Evaluations on different low-rank bottleneck architectures demonstrate that BOOST achieves 1.46-1.91$\times$ speedup over full-rank model baselines and 1.87-2.27$\times$ speedup over low-rank model with naively integrated 3D parallelism, with improved GPU utilization and reduced communication overhead.