Citation-Grounded Code Comprehension: Preventing LLM Hallucination Through Hybrid Retrieval and Graph-Augmented Context
作者: Jahidul Arafat
分类: cs.SE, cs.LG
发布日期: 2025-12-13
💡 一句话要点
提出混合检索与图增强上下文的代码理解方法,解决LLM代码幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码理解 LLM幻觉 混合检索 图数据库 代码结构
📋 核心要点
- 现有代码理解方法依赖文本相似性,忽略代码结构,导致LLM产生幻觉,引用不准确。
- 提出混合检索系统,结合BM25、BGE和Neo4j图扩展,利用代码结构发现跨文件证据。
- 实验结果表明,该方法在引用准确率上优于单模基线14-18个百分点,显著减少幻觉。
📝 摘要(中文)
大型语言模型已成为代码理解的重要工具,使开发者能够通过自然语言接口查询不熟悉的代码库。然而,LLM幻觉,即生成看似合理但实际上不正确的源代码引用,仍然是可靠开发者辅助的关键障碍。本文通过混合检索和轻量级结构推理,解决了实现可验证、基于引用的代码理解的挑战。我们的工作基于对30个Python存储库和180个开发者查询的系统评估,比较了检索方式、图扩展策略和引用验证机制。我们发现,引用准确性的挑战源于稀疏词汇匹配、密集语义相似性和跨文件架构依赖性之间的相互作用。其中,跨文件证据发现是引用完整性的最大贡献者,但由于现有系统依赖于纯文本相似性而不利用代码结构,因此在很大程度上被忽视。我们提倡将基于引用的生成作为代码理解系统的架构原则,并通过实现92%的引用准确率和零幻觉来证明这一需求。具体来说,我们开发了一种混合检索系统,该系统结合了BM25稀疏匹配、BGE密集嵌入和通过导入关系进行的Neo4j图扩展,该系统优于单模基线14到18个百分点,同时在62%的架构查询中发现了纯文本相似性遗漏的跨文件证据。
🔬 方法详解
问题定义:现有基于LLM的代码理解方法,在生成代码引用时,容易产生幻觉,即引用了实际上并不存在的代码片段。这是因为现有方法主要依赖于文本相似性匹配,忽略了代码的结构化信息,例如模块间的依赖关系,导致无法准确地找到跨文件的相关证据。
核心思路:本文的核心思路是结合文本相似性和代码结构信息,构建一个混合检索系统。该系统不仅考虑代码的文本内容,还利用代码的导入关系构建图结构,从而能够发现跨文件的依赖关系,提高代码引用的准确性和完整性。这样设计的目的是为了弥补纯文本相似性匹配的不足,更好地理解代码的上下文信息。
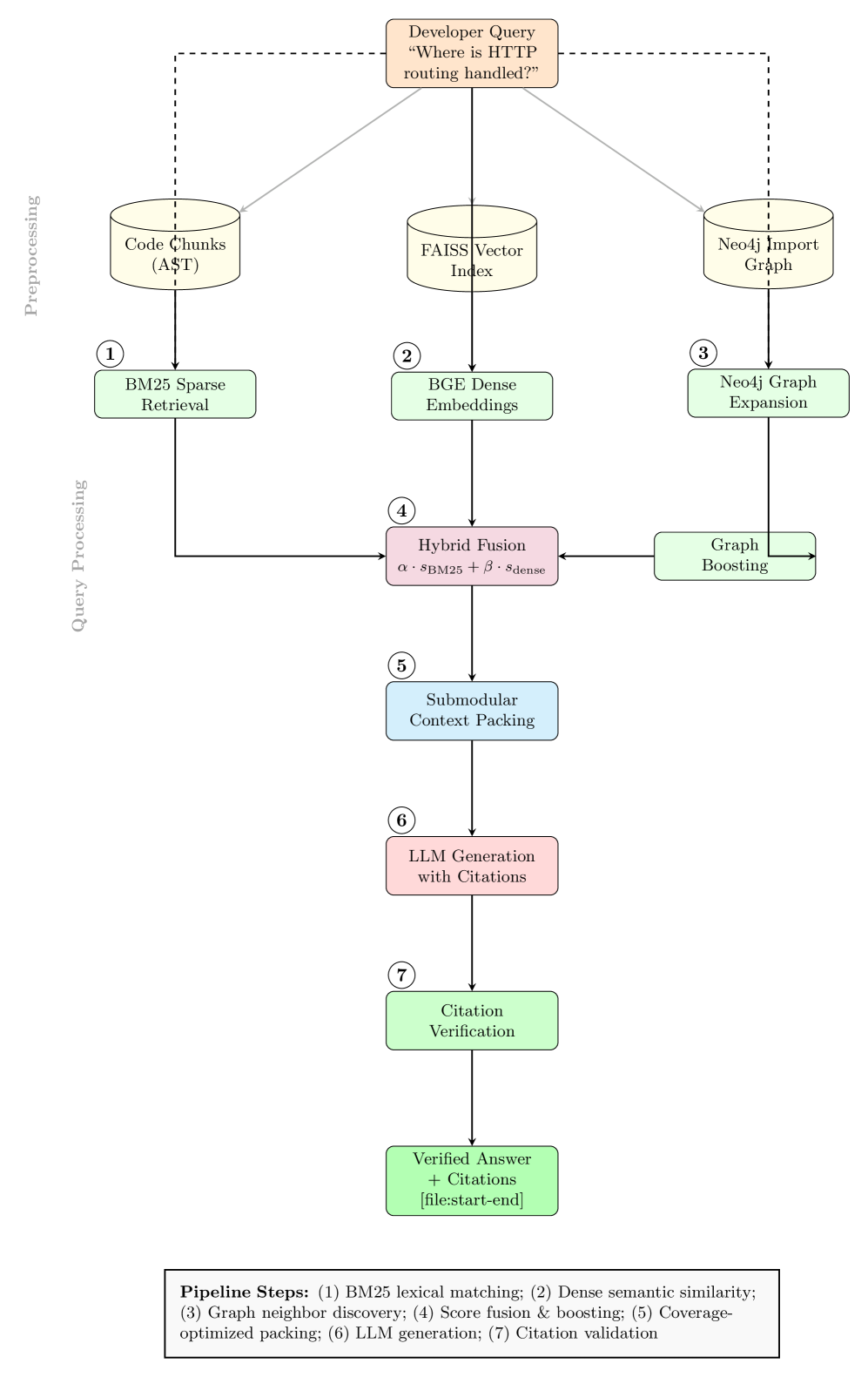
技术框架:该方法包含以下几个主要模块:1) BM25稀疏匹配:使用BM25算法进行初始的文本检索,快速找到与查询相关的代码片段。2) BGE密集嵌入:使用BGE模型对代码片段进行语义编码,计算语义相似度,进一步筛选相关代码。3) Neo4j图扩展:利用代码的导入关系构建图数据库,通过图遍历算法,发现跨文件的依赖关系,扩展检索范围。4) 引用验证:对检索到的代码片段进行验证,确保引用的准确性。
关键创新:该方法最重要的创新点在于将代码的结构信息(导入关系)融入到检索过程中。传统的代码理解方法主要依赖于文本相似性,而该方法通过构建代码的依赖关系图,能够发现跨文件的依赖关系,从而更全面地理解代码的上下文信息。这种混合检索的方式,能够有效地减少LLM的幻觉,提高代码引用的准确性。
关键设计:在Neo4j图扩展中,关键在于如何定义节点和边的关系。节点代表代码文件或函数,边代表导入关系。图遍历算法的选择也很重要,需要根据查询的特点选择合适的算法,例如深度优先搜索或广度优先搜索。此外,BM25和BGE的权重需要进行调整,以平衡文本相似性和语义相似性的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该混合检索系统在引用准确率上达到了92%,显著优于单模基线(BM25或BGE)14-18个百分点。此外,该系统在62%的架构查询中发现了纯文本相似性遗漏的跨文件证据,证明了其在发现代码依赖关系方面的优势。
🎯 应用场景
该研究成果可应用于智能IDE、代码搜索、代码审查等领域,帮助开发者更准确地理解和使用代码,提高开发效率,降低代码错误率。未来可扩展到其他编程语言和更复杂的代码结构,例如类继承、接口实现等。
📄 摘要(原文)
Large language models have become essential tools for code comprehension, enabling developers to query unfamiliar codebases through natural language interfaces. However, LLM hallucination, generating plausible but factually incorrect citations to source code, remains a critical barrier to reliable developer assistance. This paper addresses the challenges of achieving verifiable, citation grounded code comprehension through hybrid retrieval and lightweight structural reasoning. Our work is grounded in systematic evaluation across 30 Python repositories with 180 developer queries, comparing retrieval modalities, graph expansion strategies, and citation verification mechanisms. We find that challenges of citation accuracy arise from the interplay between sparse lexical matching, dense semantic similarity, and cross file architectural dependencies. Among these, cross file evidence discovery is the largest contributor to citation completeness, but it is largely overlooked because existing systems rely on pure textual similarity without leveraging code structure. We advocate for citation grounded generation as an architectural principle for code comprehension systems and demonstrate this need by achieving 92 percent citation accuracy with zero hallucinations. Specifically, we develop a hybrid retrieval system combining BM25 sparse matching, BGE dense embeddings, and Neo4j graph expansion via import relationships, which outperforms single mode baselines by 14 to 18 percentage points while discovering cross file evidence missed by pure text similarity in 62 percent of architectural queries.