CHIME: Chiplet-based Heterogeneous Near-Memory Acceleration for Edge Multimodal LLM Inference
作者: Yanru Chen, Runyang Tian, Yue Pan, Zheyu Li, Weihong Xu, Tajana Rosing
分类: cs.AR, cs.LG
发布日期: 2025-12-12
💡 一句话要点
CHIME:面向边缘多模态LLM推理的基于Chiplet的异构近存加速
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 边缘计算 近存计算 异构加速 Chiplet DRAM RRAM
📋 核心要点
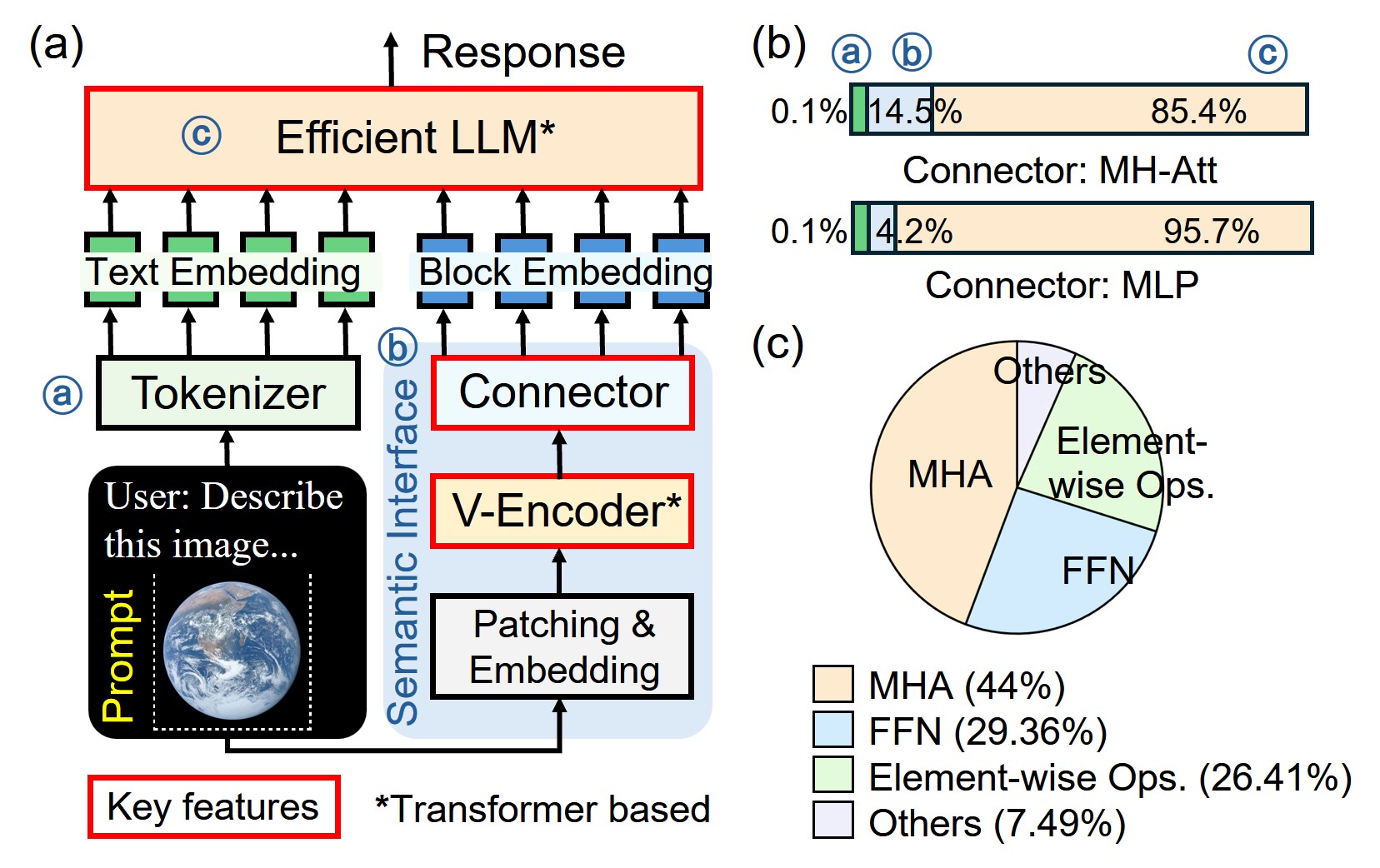
- 边缘设备上多模态LLM推理面临延迟、能耗和连接性挑战,现有方法难以有效处理高维视觉输入带来的KV缓存和数据移动开销。
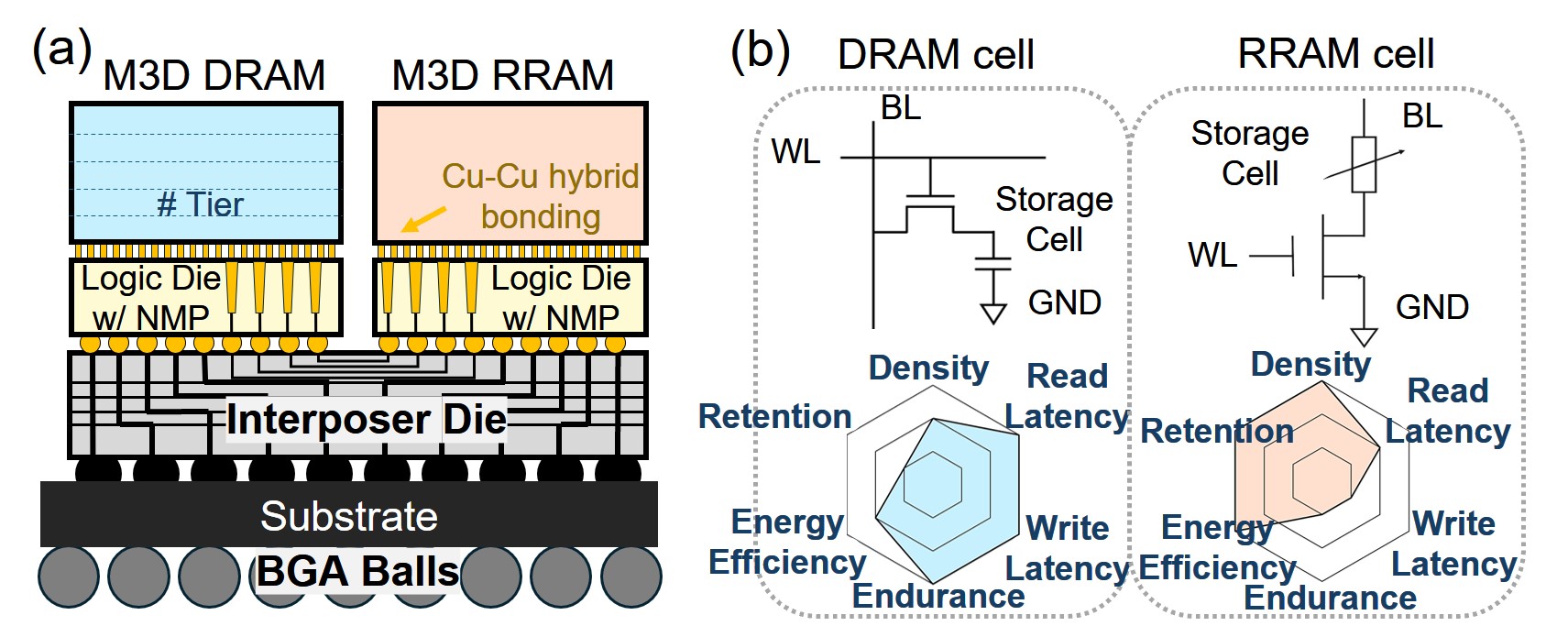
- CHIME利用M3D DRAM和RRAM chiplet的互补优势,DRAM提供低延迟带宽,RRAM提供高密度非易失性存储,并通过协同映射框架优化数据访问。
- 实验表明,CHIME在FastVLM和MobileVLM上相比Jetson Orin NX有显著的加速和能效提升,并优于现有PIM加速器FACIL和纯DRAM方案。
📝 摘要(中文)
大型语言模型(LLM)的普及加速了多模态助手集成到边缘设备中,而边缘设备上的推理通常受到严格的延迟和能源约束,并且互连性不稳定。这些挑战在多模态LLM(MLLM)的背景下变得尤为严峻,因为高维视觉输入被转换为大量的token序列,从而扩大了键值(KV)缓存,并给LLM骨干网络带来了大量的数据移动开销。为了解决这些问题,我们提出了CHIME,一种基于chiplet的异构近存加速方案,用于边缘MLLM推理。CHIME利用集成单片3D(M3D)DRAM和RRAM chiplet的互补优势:DRAM为注意力机制提供低延迟带宽,而RRAM为权重提供密集、非易失性存储。这种异构硬件由协同设计的映射框架协调,该框架在数据附近执行融合内核,从而最大限度地减少跨chiplet的流量,以最大限度地提高有效带宽。在FastVLM(0.6B/1.7B)和MobileVLM(1.7B/3B)上,与边缘GPU NVIDIA Jetson Orin NX相比,CHIME每次推理可实现高达54倍的加速和高达246倍的能效提升。它能维持116.5-266.5 token/J,而Jetson为0.7-1.1 token/J。此外,与最先进的PIM加速器FACIL相比,它提供了高达69.2倍的更高吞吐量。与仅使用M3D DRAM的设计相比,CHIME的异构内存进一步提高了7%的能效和2.4倍的性能。
🔬 方法详解
问题定义:论文旨在解决边缘设备上多模态大型语言模型(MLLM)推理的效率问题。现有的边缘设备在处理MLLM时,由于高维视觉输入导致KV缓存增大和数据移动开销增加,面临着延迟高、能耗大的挑战。传统方法难以在资源受限的边缘环境中实现高性能和低功耗的MLLM推理。
核心思路:论文的核心思路是利用异构近存计算架构,结合DRAM和RRAM的优势,实现高效的MLLM推理。DRAM提供低延迟的带宽,适合处理注意力机制中的数据访问;RRAM提供高密度的非易失性存储,适合存储模型权重。通过将计算靠近数据放置,减少数据移动,从而提高性能和能效。
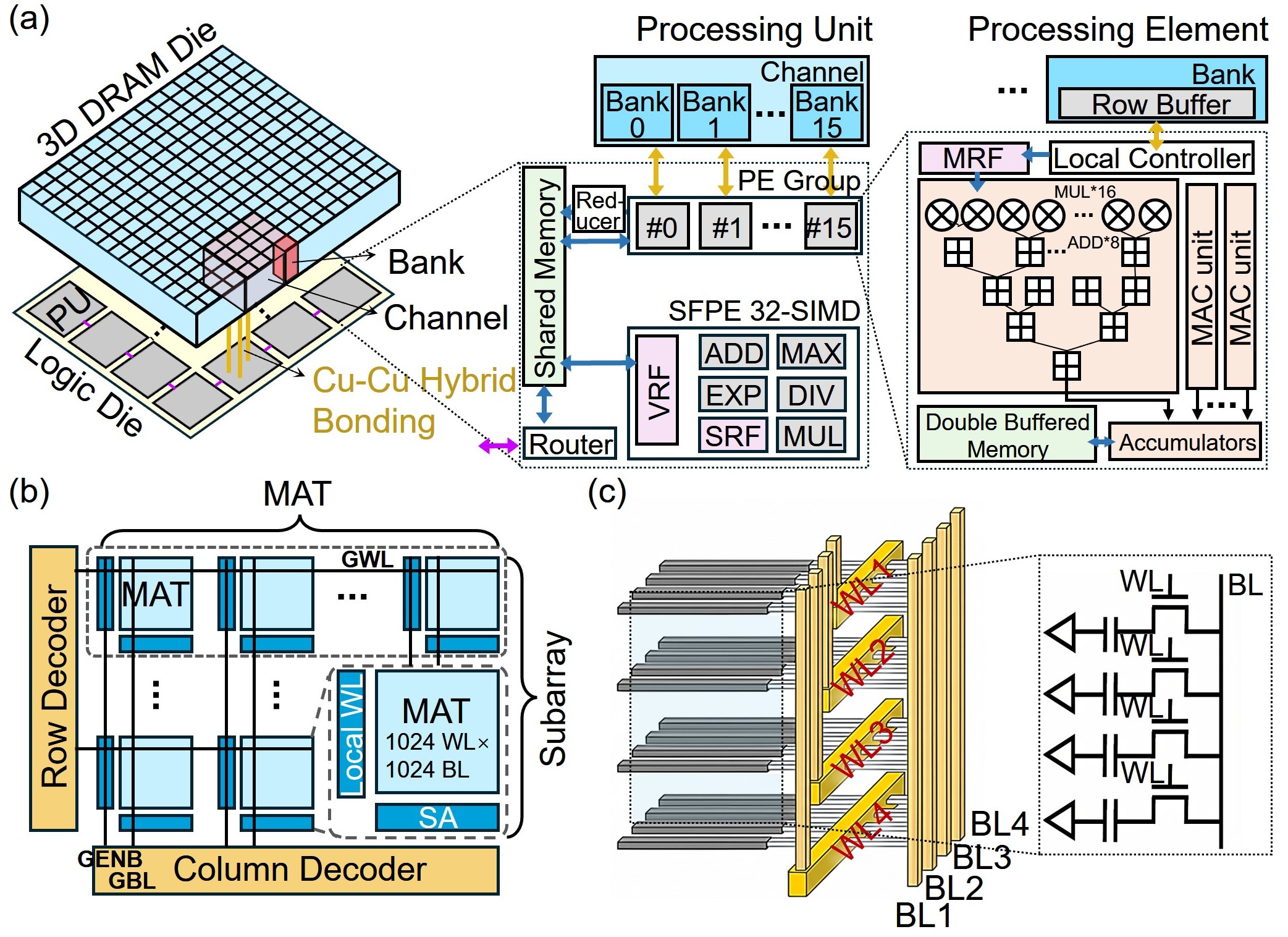
技术框架:CHIME的整体架构包括:1)M3D DRAM chiplet,用于存储和快速访问KV缓存;2)RRAM chiplet,用于存储模型权重;3)协同设计的映射框架,用于将计算任务映射到合适的硬件资源上,并优化数据访问模式。该框架通过融合内核的方式,在数据附近执行计算,减少跨chiplet的数据传输。
关键创新:CHIME的关键创新在于异构内存架构和协同映射框架的结合。传统方法通常使用同构的DRAM或SRAM,无法同时满足低延迟和高密度的需求。CHIME通过结合DRAM和RRAM,实现了性能和存储密度的平衡。协同映射框架能够根据硬件特性,优化数据访问和计算任务的调度,从而最大限度地提高硬件利用率。
关键设计:CHIME的关键设计包括:1)DRAM和RRAM的容量和带宽配置,需要根据MLLM的模型大小和计算需求进行优化;2)协同映射框架中的任务调度算法,需要考虑数据局部性和硬件资源约束,以最小化数据移动和延迟;3)融合内核的设计,需要将多个计算操作合并成一个内核,以减少内核启动和数据传输的开销。
🖼️ 关键图片
📊 实验亮点
CHIME在FastVLM(0.6B/1.7B)和MobileVLM(1.7B/3B)模型上进行了评估,实验结果表明,与NVIDIA Jetson Orin NX相比,CHIME实现了高达54倍的推理速度提升和高达246倍的能效提升。CHIME的能效达到116.5-266.5 token/J,而Jetson Orin NX仅为0.7-1.1 token/J。此外,CHIME的吞吐量比最先进的PIM加速器FACIL高出69.2倍。与仅使用M3D DRAM的设计相比,CHIME的异构内存进一步提高了7%的能效和2.4倍的性能。
🎯 应用场景
CHIME的研究成果可应用于各种边缘设备上的多模态人工智能应用,例如智能手机、AR/VR设备、机器人和自动驾驶汽车。通过提高边缘设备上MLLM推理的效率,可以实现更智能、更实时的用户体验,并降低设备的功耗,延长电池续航时间。该研究还有助于推动多模态人工智能在资源受限环境中的普及。
📄 摘要(原文)
The proliferation of large language models (LLMs) is accelerating the integration of multimodal assistants into edge devices, where inference is executed under stringent latency and energy constraints, often exacerbated by intermittent connectivity. These challenges become particularly acute in the context of multimodal LLMs (MLLMs), as high-dimensional visual inputs are transformed into extensive token sequences, thereby inflating the key-value (KV) cache and imposing substantial data movement overheads to the LLM backbone. To address these issues, we present CHIME, a chiplet-based heterogeneous near-memory acceleration for edge MLLMs inference. CHIME leverages the complementary strengths of integrated monolithic 3D (M3D) DRAM and RRAM chiplets: DRAM supplies low-latency bandwidth for attention, while RRAM offers dense, non-volatile storage for weights. This heterogeneous hardware is orchestrated by a co-designed mapping framework that executes fused kernels near data, minimizing cross-chiplet traffic to maximize effective bandwidth. On FastVLM (0.6B/1.7B) and MobileVLM (1.7B/3B), CHIME achieves up to 54x speedup and up to 246x better energy efficiency per inference as compared to the edge GPU NVIDIA Jetson Orin NX. It sustains 116.5-266.5 token/J compared to Jetson's 0.7-1.1 token/J. Furthermore, it delivers up to 69.2x higher throughput than the state-of-the-art PIM accelerator FACIL. Compared to the M3D DRAM-only design, CHIME's heterogeneous memory further improves energy efficiency by 7% and performance by 2.4x.