Data Valuation for LLM Fine-Tuning: Efficient Shapley Value Approximation via Language Model Arithmetic
作者: Mélissa Tamine, Otmane Sakhi, Benjamin Heymann
分类: cs.LG, cs.GT, stat.ML
发布日期: 2025-12-12 (更新: 2026-01-26)
备注: 11 pages, 2 figures
💡 一句话要点
提出基于语言模型算术的高效Shapley值近似方法,用于LLM微调的数据估值
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据估值 大型语言模型 直接偏好优化 Shapley值 模型微调
📋 核心要点
- 现有数据估值方法在LLM微调中计算Shapley值成本高昂,需要多次模型重训练,计算量巨大。
- 利用DPO训练LLM的特定数学结构,论文提出了一种可扩展的Shapley值计算方法,显著降低计算复杂度。
- 该方法为数据所有者在数据管理和投资决策方面提供支持,并促进数据所有者之间的协作和公平收益分配。
📝 摘要(中文)
数据是训练大型语言模型(LLM)的关键资产,与计算资源和熟练人员同等重要。虽然一些训练数据是公开可用的,但生成专有数据集(如人类偏好标注)或从现有来源整理新数据集需要大量投资。由于更大的数据集通常会产生更好的模型性能,因此自然会产生两个问题。首先,数据所有者如何就管理策略和数据源投资做出明智的决策?其次,多个数据所有者如何协作汇集资源以训练更好的模型,同时公平地分配收益?数据估值问题并非大型语言模型所独有,机器学习社区已通过合作博弈论的视角对其进行了研究,其中Shapley值是普遍的解决方案概念。然而,对于数据估值而言,计算Shapley值的成本非常高昂,通常需要多次模型重新训练,这对于大型机器学习模型来说可能是令人望而却步的。在这项工作中,我们证明了对于使用直接偏好优化(DPO)训练的LLM,这种计算挑战得到了极大的简化。我们展示了DPO的特定数学结构如何实现可扩展的Shapley值计算。我们相信这一观察结果开启了数据估值和大型语言模型交叉领域的许多应用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)微调过程中数据估值的计算成本问题。传统上,使用Shapley值进行数据估值需要对模型进行多次重训练,这对于参数量巨大的LLM来说是极其耗时的。现有方法难以在可接受的时间内完成数据估值,阻碍了数据所有者进行明智的投资决策和协作。
核心思路:论文的核心思路是利用直接偏好优化(DPO)训练的LLM的特定数学结构,推导出一种高效的Shapley值计算方法。DPO的数学特性使得Shapley值的计算可以被简化,避免了大量的模型重训练。通过这种方式,可以在更短的时间内完成数据估值,从而为数据所有者提供有价值的信息。
技术框架:该方法主要包含以下几个阶段: 1. 使用DPO训练LLM。 2. 基于DPO的数学结构,推导Shapley值的近似计算公式。 3. 使用该公式计算每个训练样本的Shapley值。 4. 基于Shapley值进行数据评估和选择。
关键创新:该方法最重要的技术创新点在于发现了DPO训练的LLM的数学结构与Shapley值计算之间的联系,并利用这种联系实现了高效的Shapley值近似计算。与传统的需要多次模型重训练的方法相比,该方法极大地降低了计算复杂度,使得在LLM微调中进行数据估值成为可能。
关键设计:论文的关键设计在于如何将DPO的损失函数与Shapley值的计算联系起来。具体来说,论文推导了一个基于DPO损失函数的Shapley值近似计算公式,该公式避免了对模型进行多次重训练。此外,论文可能还涉及一些参数设置,例如DPO训练的学习率、batch size等,这些参数可能会影响Shapley值计算的准确性和效率。
🖼️ 关键图片
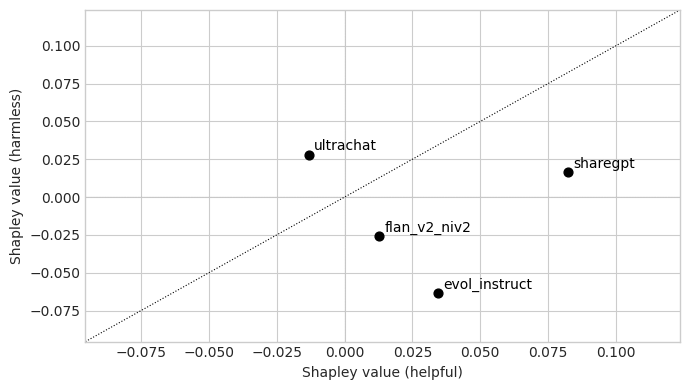
📊 实验亮点
论文的主要亮点在于提出了基于DPO的高效Shapley值近似计算方法。该方法避免了传统Shapley值计算中大量的模型重训练,显著降低了计算成本。虽然摘要中没有给出具体的性能数据,但可以推断,该方法在计算效率方面相比传统方法有显著提升,使得在LLM微调中进行数据估值成为可能。
🎯 应用场景
该研究成果可应用于多个领域。数据所有者可以利用该方法评估其数据集的价值,从而做出更明智的投资决策。多个数据所有者可以利用该方法进行协作,共同训练更强大的LLM,并公平地分配收益。此外,该方法还可以用于数据选择和清洗,从而提高LLM的性能和效率。未来,该方法有望推动LLM在各个领域的应用。
📄 摘要(原文)
Data is a critical asset for training large language models (LLMs), alongside compute resources and skilled workers. While some training data is publicly available, substantial investment is required to generate proprietary datasets, such as human preference annotations or to curate new ones from existing sources. As larger datasets generally yield better model performance, two natural questions arise. First, how can data owners make informed decisions about curation strategies and data sources investment? Second, how can multiple data owners collaboratively pool their resources to train superior models while fairly distributing the benefits? This problem, data valuation, which is not specific to large language models, has been addressed by the machine learning community through the lens of cooperative game theory, with the Shapley value being the prevalent solution concept. However, computing Shapley values is notoriously expensive for data valuation, typically requiring numerous model retrainings, which can become prohibitive for large machine learning models. In this work, we demonstrate that this computational challenge is dramatically simplified for LLMs trained with Direct Preference Optimization (DPO). We show how the specific mathematical structure of DPO enables scalable Shapley value computation. We believe this observation unlocks many applications at the intersection of data valuation and large language models.