GraphPerf-RT: A Graph-Driven Performance Model for Hardware-Aware Scheduling of OpenMP Codes
作者: Mohammad Pivezhandi, Mahdi Banisharif, Saeed Bakhshan, Abusayeed Saifullah, Ali Jannesari
分类: cs.LG
发布日期: 2025-12-12 (更新: 2026-01-21)
备注: 49 pages, 4 figures, 19 tables
💡 一句话要点
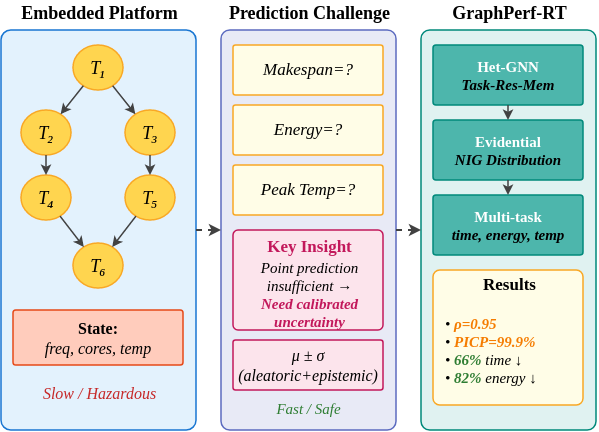
提出GraphPerf-RT,用于OpenMP代码硬件感知调度的图驱动性能模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图神经网络 性能建模 硬件感知调度 嵌入式系统 实时调度
📋 核心要点
- 传统调度方法在嵌入式平台上难以应对AI代理工作负载的不规则性,且存在过热风险。
- GraphPerf-RT通过异构图统一任务拓扑、代码语义和运行时上下文,实现硬件感知的性能预测。
- 实验表明,GraphPerf-RT能有效降低makespan和能量消耗,同时避免热违规。
📝 摘要(中文)
本文提出GraphPerf-RT,一种图神经网络代理模型,旨在嵌入式平台上实现实时、风险感知的资源和热约束下的自主AI代理调度。传统启发式算法难以处理工作负载的不规则性,表格回归器丢弃了结构信息,而无模型强化学习(RL)存在过热风险。GraphPerf-RT统一了任务DAG拓扑、CFG导出的代码语义以及运行时上下文(每个核心的DVFS、热状态、利用率),构建了一个异构图,其中类型化的边编码了优先级、放置和竞争关系。采用具有Normal-Inverse-Gamma先验的证据回归提供校准的不确定性。在风险感知调度的makespan预测上进行了验证。在三个ARM平台(Jetson TX2、Orin NX、RUBIK Pi)上的实验表明,对数变换后的makespan的R^2 = 0.81,Spearman rho = 0.95,保守不确定性校准(95%置信度下PICP = 99.9%)。与四种RL方法的集成表明,以GraphPerf-RT作为世界模型的多智能体模型强化学习与无模型基线相比,实现了66%的makespan减少和82%的能量减少,且没有热违规。
🔬 方法详解
问题定义:论文旨在解决嵌入式平台上自主AI代理的实时、风险感知调度问题。现有方法,如启发式算法、表格回归器和无模型强化学习,分别存在处理不规则工作负载能力差、忽略结构信息和容易导致过热等痛点。这些问题限制了AI代理在资源受限环境中的可靠性和效率。
核心思路:论文的核心思路是利用图神经网络(GNN)学习任务的性能模型,该模型能够同时考虑任务之间的依赖关系(DAG拓扑)、代码的语义信息(CFG)以及运行时的硬件状态(如DVFS、温度和利用率)。通过将这些信息编码到异构图中,GNN能够更准确地预测任务的执行时间,从而为调度器提供更可靠的依据。
技术框架:GraphPerf-RT的整体框架包括以下几个主要模块:1)异构图构建模块:将任务DAG、CFG和运行时上下文信息编码为异构图,其中节点表示任务、代码块或硬件资源,边表示任务之间的依赖关系、代码块之间的控制流或资源竞争关系。2)图神经网络模型:使用GNN学习异构图的节点表示,从而预测任务的执行时间。3)证据回归模块:使用Normal-Inverse-Gamma先验进行证据回归,提供校准的不确定性估计。4)调度器集成:将GraphPerf-RT作为世界模型集成到强化学习调度器中,实现风险感知的调度。
关键创新:GraphPerf-RT的关键创新在于:1)统一了任务DAG拓扑、CFG导出的代码语义和运行时上下文到一个异构图中,从而能够更全面地捕捉影响任务性能的因素。2)使用证据回归提供校准的不确定性估计,从而能够进行风险感知的调度。3)首次将GNN应用于嵌入式系统的实时调度问题,并取得了显著的性能提升。
关键设计:在异构图构建方面,论文设计了不同类型的节点和边来表示任务、代码块、硬件资源以及它们之间的关系。在GNN模型方面,论文采用了图注意力网络(GAT)来学习节点表示。在证据回归方面,论文使用了Normal-Inverse-Gamma先验来建模预测的不确定性。损失函数包括预测误差和不确定性损失,以提高模型的准确性和可靠性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GraphPerf-RT在三个ARM平台(Jetson TX2、Orin NX、RUBIK Pi)上取得了显著的性能提升。在makespan预测方面,R^2达到0.81,Spearman rho达到0.95,且不确定性校准良好(95%置信度下PICP = 99.9%)。与无模型强化学习基线相比,集成GraphPerf-RT的多智能体模型强化学习实现了66%的makespan减少和82%的能量减少,且没有热违规。
🎯 应用场景
GraphPerf-RT可应用于各种嵌入式系统和边缘计算场景,例如自动驾驶、机器人、无人机等。通过实现硬件感知的实时调度,可以提高系统的性能、降低功耗,并确保任务的可靠执行。该研究为开发更智能、更高效的嵌入式AI系统提供了新的思路。
📄 摘要(原文)
Autonomous AI agents on embedded platforms require real-time, risk-aware scheduling under resource and thermal constraints. Classical heuristics struggle with workload irregularity, tabular regressors discard structural information, and model-free reinforcement learning (RL) risks overheating. We introduce GraphPerf-RT, a graph neural network surrogate achieving deep learning accuracy at heuristic speeds (2-7ms). GraphPerf-RT is, to our knowledge, the first to unify task DAG topology, CFG-derived code semantics, and runtime context (per-core DVFS, thermal state, utilization) in a heterogeneous graph with typed edges encoding precedence, placement, and contention. Evidential regression with Normal-Inverse-Gamma priors provides calibrated uncertainty; we validate on makespan prediction for risk-aware scheduling. Experiments on three ARM platforms (Jetson TX2, Orin NX, RUBIK Pi) achieve R^2 = 0.81 on log-transformed makespan with Spearman rho = 0.95 and conservative uncertainty calibration (PICP = 99.9% at 95% confidence). Integration with four RL methods demonstrates that multi-agent model-based RL with GraphPerf-RT as the world model achieves 66% makespan reduction and 82% energy reduction versus model-free baselines, with zero thermal violations.