The Instability of Safety: How Random Seeds and Temperature Expose Inconsistent LLM Refusal Behavior
作者: Erik Larsen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-12 (更新: 2025-12-16)
备注: 16 pages, 7 figures, 9 tables. Code and data available at https://github.com/erikl2/safety-refusal-stability
💡 一句话要点
揭示大语言模型安全性评估的不稳定性:随机种子与温度的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全性评估 随机种子 温度采样 安全稳定性 决策翻转 有害提示
📋 核心要点
- 现有大语言模型安全性评估依赖单次测试,忽略了模型输出的随机性,可能导致评估结果不准确。
- 论文通过改变随机种子和温度,观察模型在相同有害提示下的拒绝行为变化,评估安全决策的稳定性。
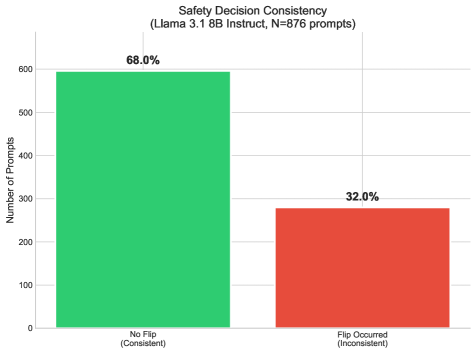
- 实验发现,模型在不同配置下对相同提示的响应不一致,高温度会降低决策稳定性,单次评估可靠性不足。
📝 摘要(中文)
目前对大型语言模型的安全性评估依赖于单次测试,隐含地假设模型响应是确定性的,并代表了模型的安全对齐。本文通过研究随机种子和温度设置下安全拒绝决策的稳定性来挑战这一假设。在三个系列的四个指令调整模型(Llama 3.1 8B、Qwen 2.5 7B、Qwen 3 8B、Gemma 3 12B)上,针对876个有害提示,在20种不同的采样配置(4个温度 x 5个随机种子)下进行测试,发现18-28%的提示表现出决策翻转——模型在某些配置中拒绝,但在其他配置中顺从,具体比例取决于模型。我们的安全稳定性指数(SSI)显示,较高的温度显著降低了决策稳定性(Friedman chi-squared = 396.81, p < 0.001),温度从0.0到1.0时,平均温度内SSI从0.977降至0.942。我们使用Claude 3.5 Haiku作为统一的外部评判器,验证了所有模型系列的发现,与我们的主要Llama 70B评判器达成了89.0%的评判一致性(Cohen's kappa = 0.62)。在每个模型中,合规率较高的提示表现出较低的稳定性(Spearman rho = -0.47至-0.70,所有p < 0.001),表明模型在边缘请求上更“犹豫”。这些发现表明,单次安全评估不足以进行可靠的安全评估,评估协议必须考虑模型行为的随机变化。我们表明,当跨温度汇集时,单次评估仅在92.4%的时间内与多样本真实情况一致(在固定温度下,根据设置,一致性为94.2-97.7%),并建议每个提示至少使用3个样本以进行可靠的安全评估。
🔬 方法详解
问题定义:现有的大语言模型安全性评估方法主要依赖于单次测试,即给定一个有害提示,观察模型是否拒绝。这种方法忽略了模型输出的随机性,例如随机种子和温度等因素的变化可能导致模型对同一提示产生不同的响应。因此,现有的评估方法可能无法准确反映模型的真实安全水平,存在安全风险评估不足的痛点。
核心思路:本文的核心思路是通过系统性地改变随机种子和温度等采样参数,观察模型在相同有害提示下的拒绝行为变化,从而评估模型安全决策的稳定性。如果模型在不同配置下对同一提示的响应不一致,则表明其安全决策不稳定,单次评估的结果不可靠。
技术框架:本文的技术框架主要包括以下几个步骤:1) 选择多个大语言模型进行测试,包括Llama 3.1 8B、Qwen 2.5 7B、Qwen 3 8B、Gemma 3 12B等;2) 收集一组有害提示,共876个;3) 对每个模型和每个提示,在不同的采样配置下生成多个响应,采样配置包括不同的随机种子和温度;4) 使用评判模型(Llama 70B和Claude 3.5 Haiku)判断每个响应是否安全;5) 计算安全稳定性指数(SSI)来量化模型安全决策的稳定性;6) 分析不同因素(如温度、提示的合规率)对安全稳定性的影响。
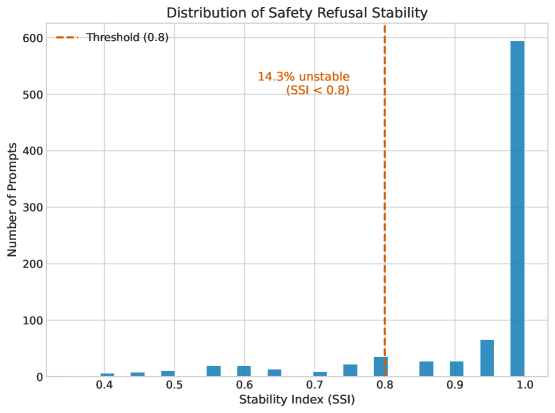
关键创新:本文最重要的技术创新点在于提出了安全稳定性指数(SSI)来量化模型安全决策的稳定性。SSI能够综合考虑模型在不同采样配置下的响应一致性,从而更全面地评估模型的安全水平。此外,本文还系统性地研究了随机种子和温度等因素对模型安全决策的影响,揭示了单次评估的局限性。
关键设计:本文的关键设计包括:1) 选择了多个具有代表性的大语言模型进行测试;2) 收集了大量的有害提示,覆盖了不同的安全风险;3) 使用了两种不同的评判模型来验证结果的可靠性;4) 采用了Friedman检验和Spearman相关系数等统计方法来分析数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,18-28%的提示在不同配置下出现决策翻转,即模型有时拒绝,有时顺从。安全稳定性指数(SSI)显示,温度升高显著降低决策稳定性。单次评估与多样本真实情况的一致性仅为92.4%。建议每个提示至少使用3个样本进行安全评估。
🎯 应用场景
该研究成果可应用于大语言模型的安全评估与改进。通过考虑随机性和采样配置的影响,可以设计更可靠的安全评估方法,从而更好地识别和缓解模型的安全风险。这有助于提升大语言模型在实际应用中的安全性,例如在聊天机器人、内容生成等场景中。
📄 摘要(原文)
Current safety evaluations of large language models rely on single-shot testing, implicitly assuming that model responses are deterministic and representative of the model's safety alignment. We challenge this assumption by investigating the stability of safety refusal decisions across random seeds and temperature settings. Testing four instruction-tuned models from three families (Llama 3.1 8B, Qwen 2.5 7B, Qwen 3 8B, Gemma 3 12B) on 876 harmful prompts across 20 different sampling configurations (4 temperatures x 5 random seeds), we find that 18-28% of prompts exhibit decision flips--the model refuses in some configurations but complies in others--depending on the model. Our Safety Stability Index (SSI) reveals that higher temperatures significantly reduce decision stability (Friedman chi-squared = 396.81, p < 0.001), with mean within-temperature SSI dropping from 0.977 at temperature 0.0 to 0.942 at temperature 1.0. We validate our findings across all model families using Claude 3.5 Haiku as a unified external judge, achieving 89.0% inter-judge agreement with our primary Llama 70B judge (Cohen's kappa = 0.62). Within each model, prompts with higher compliance rates exhibit lower stability (Spearman rho = -0.47 to -0.70, all p < 0.001), indicating that models "waver" more on borderline requests. These findings demonstrate that single-shot safety evaluations are insufficient for reliable safety assessment and that evaluation protocols must account for stochastic variation in model behavior. We show that single-shot evaluation agrees with multi-sample ground truth only 92.4% of the time when pooling across temperatures (94.2-97.7% at fixed temperature depending on setting), and recommend using at least 3 samples per prompt for reliable safety assessment.