Learning to Extract Context for Context-Aware LLM Inference
作者: Minseon Kim, Lucas Caccia, Zhengyan Shi, Matheus Pereira, Marc-Alexandre Côté, Xingdi Yuan, Alessandro Sordoni
分类: cs.LG
发布日期: 2025-12-12
💡 一句话要点
提出基于强化学习的上下文提取框架,提升LLM在安全任务中的可靠性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文提取 强化学习 大语言模型 安全推理 用户意图
📋 核心要点
- 现有LLM对用户请求的理解常常不足,忽略了用户意图、先验知识等上下文信息,导致不安全或不必要的拒绝。
- 论文提出一种基于强化学习的上下文提取框架,从用户提示中推断上下文信号,并利用这些信号指导LLM生成更合适的响应。
- 实验结果表明,该方法能有效降低LLM生成有害响应的比例,并提高对良性提示的依从性,提升了LLM的安全性。
📝 摘要(中文)
本文挑战了LLM直接响应用户请求的传统框架,认为用户请求存在于更广泛的意图、知识和经验上下文中,这些上下文强烈影响着适当的答案。为此,本文提出了一种框架,从用户提示本身提取并利用这种上下文信息。具体来说,训练一个基于强化学习的上下文生成器,该生成器以类似自编码器的方式设计,用于推断基于提示的上下文信号,并使用它们来指导响应生成。这种方法对于安全任务尤其重要,在安全任务中,模糊的请求可能会绕过安全措施,而良性但令人困惑的请求可能会触发不必要的拒绝。实验表明,该方法在SafetyInstruct数据集上将有害响应平均降低了5.6%,并在XSTest和WildJailbreak上将攻击成功率与良性提示依从性的调和平均值提高了6.2%。这些结果证明了上下文提取对于更安全、更可靠的LLM推理的有效性。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在处理用户请求时,通常直接基于提示进行响应,忽略了用户请求背后的上下文信息,如用户意图、先验知识和潜在风险。这种做法可能导致LLM产生不安全或不恰当的回复,或者对良性请求进行不必要的拒绝。因此,如何让LLM理解用户请求的上下文,从而生成更安全、更可靠的回复,是本文要解决的核心问题。
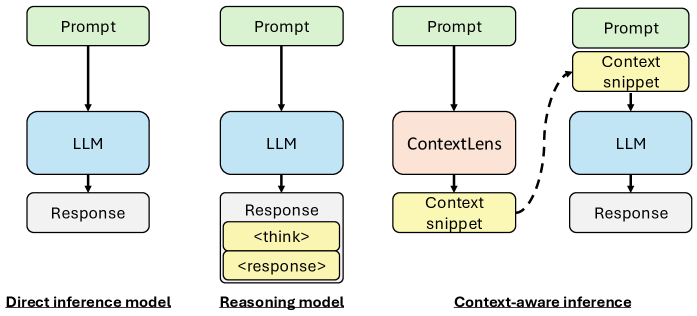
核心思路:本文的核心思路是从用户提示本身提取上下文信息,并利用这些信息来指导LLM的响应生成。具体来说,设计一个上下文生成器,该生成器能够从用户提示中推断出隐藏的上下文信号,例如用户的意图、知识背景和潜在风险。然后,将这些上下文信号融入到LLM的输入中,从而引导LLM生成更符合用户意图和更安全的回复。
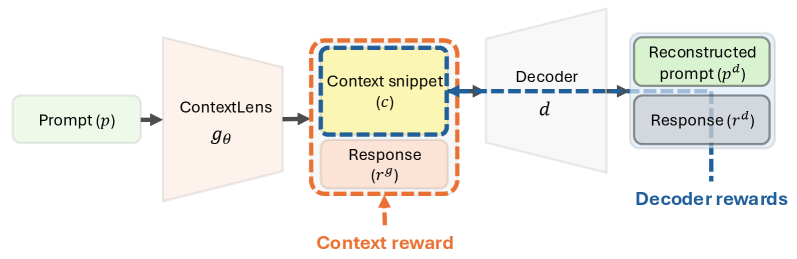
技术框架:该框架主要包含两个模块:上下文生成器和LLM。上下文生成器采用类似自编码器的结构,首先将用户提示编码成一个潜在的上下文向量,然后解码器根据这个向量重建用户提示。通过这种方式,上下文生成器学习到用户提示中蕴含的上下文信息。LLM则接收用户提示和上下文生成器提取的上下文向量作为输入,生成最终的回复。整个框架采用强化学习进行训练,目标是最大化LLM生成安全且符合用户意图的回复的概率。
关键创新:本文的关键创新在于提出了一种基于强化学习的上下文提取方法,能够从用户提示中自动学习并提取上下文信息。与传统的上下文建模方法相比,该方法不需要人工标注上下文信息,而是通过强化学习的方式,让模型自动学习如何从用户提示中提取有用的上下文信息。此外,该方法还能够根据不同的安全任务,自适应地调整上下文提取策略,从而提高LLM在安全任务中的可靠性。
关键设计:上下文生成器采用Transformer结构,编码器和解码器都由多层Transformer块组成。强化学习的奖励函数设计为:如果LLM生成的回复是安全的且符合用户意图,则给予正向奖励;如果LLM生成的回复是不安全的或不符合用户意图,则给予负向奖励。通过这种奖励机制,上下文生成器能够学习到如何提取能够引导LLM生成安全且符合用户意图的回复的上下文信息。
🖼️ 关键图片
📊 实验亮点
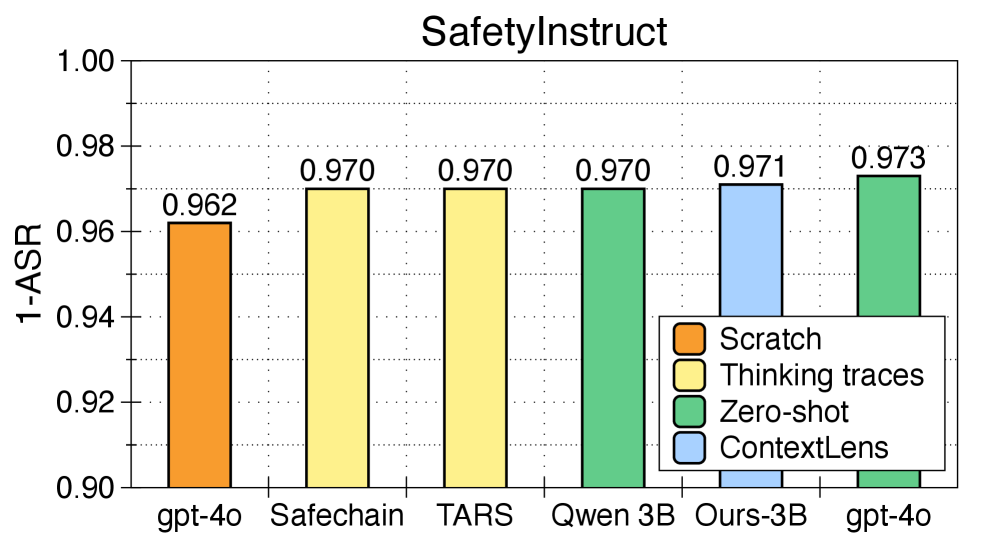
实验结果表明,该方法在SafetyInstruct数据集上将有害响应平均降低了5.6%,并在XSTest和WildJailbreak上将攻击成功率与良性提示依从性的调和平均值提高了6.2%。这些结果表明,通过提取用户请求的上下文信息,可以显著提高LLM在安全任务中的可靠性。
🎯 应用场景
该研究成果可广泛应用于各种需要安全可靠LLM推理的场景,例如智能客服、内容审核、医疗诊断等。通过提取用户请求的上下文信息,可以有效避免LLM生成有害或不恰当的回复,提高用户体验和安全性。未来,该方法还可以扩展到其他类型的任务中,例如情感分析、文本摘要等,从而提升LLM的整体性能。
📄 摘要(原文)
User prompts to large language models (LLMs) are often ambiguous or under-specified, and subtle contextual cues shaped by user intentions, prior knowledge, and risk factors strongly influence what constitutes an appropriate response. Misinterpreting intent or risks may lead to unsafe outputs, while overly cautious interpretations can cause unnecessary refusal of benign requests. In this paper, we question the conventional framework in which LLMs generate immediate responses to requests without considering broader contextual factors. User requests are situated within broader contexts such as intentions, knowledge, and prior experience, which strongly influence what constitutes an appropriate answer. We propose a framework that extracts and leverages such contextual information from the user prompt itself. Specifically, a reinforcement learning based context generator, designed in an autoencoder-like fashion, is trained to infer contextual signals grounded in the prompt and use them to guide response generation. This approach is particularly important for safety tasks, where ambiguous requests may bypass safeguards while benign but confusing requests can trigger unnecessary refusals. Experiments show that our method reduces harmful responses by an average of 5.6% on the SafetyInstruct dataset across multiple foundation models and improves the harmonic mean of attack success rate and compliance on benign prompts by 6.2% on XSTest and WildJailbreak. These results demonstrate the effectiveness of context extraction for safer and more reliable LLM inferences.