Mitigating the Safety Alignment Tax with Null-Space Constrained Policy Optimization
作者: Yifan Niu, Han Xiao, Dongyi Liu, Nuo Chen, Jia Li
分类: cs.LG
发布日期: 2025-12-12 (更新: 2026-01-30)
备注: accepted by ICLR 2026
💡 一句话要点
提出Null-Space约束策略优化(NSPO)以缓解LLM安全对齐中的能力遗忘问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 强化学习 策略优化 零空间投影 能力保留 对齐税
📋 核心要点
- 现有LLM安全对齐方法在强化学习中存在“对齐税”问题,即提升安全性的同时会损害模型原有的通用能力。
- 论文提出Null-Space约束策略优化(NSPO),通过将安全策略梯度投影到通用任务的零空间,来缓解能力遗忘。
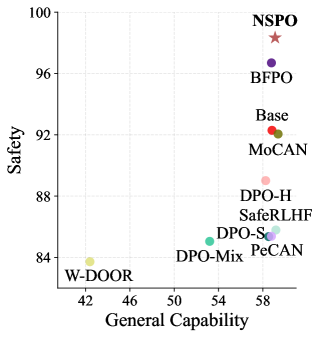
- 实验表明,NSPO在保证通用任务性能的同时,显著提升了LLM的安全性,且数据效率更高。
📝 摘要(中文)
随着大型语言模型(LLMs)在现实世界应用中日益普及,确保其行为符合人类价值观、社会规范和伦理原则至关重要。然而,在强化学习(RL)下的安全对齐常常遭受遗忘已学习到的通用能力的困扰,即所谓的对齐税。为了解决这个问题,我们引入了Null-Space约束策略优化(NSPO),这是一种新颖的RL框架,用于LLM安全对齐,同时保留其核心能力。安全策略梯度在几何上被投影到通用任务的零空间中,从而减轻了安全对齐税。此外,我们从理论上证明了NSPO保留了模型原有的核心能力,同时仍然保证了有效安全对齐的下降方向。大量实验表明,NSPO优于现有方法,在不牺牲数学、代码和指令跟随等通用任务的准确性的前提下,实现了最先进的安全性能。值得注意的是,NSPO具有数据效率,仅需PKU-SafeRLHF中40%的公共人工标注安全数据即可实现有希望的安全性能,而无需像现有对齐方法那样的大量混合通用任务数据。
🔬 方法详解
问题定义:现有基于强化学习的LLM安全对齐方法,在提升模型安全性的同时,往往会牺牲模型在通用任务上的性能,例如数学、代码生成等,这种现象被称为“对齐税”。现有的方法需要大量混合通用任务数据来缓解这个问题,但数据获取成本高昂。
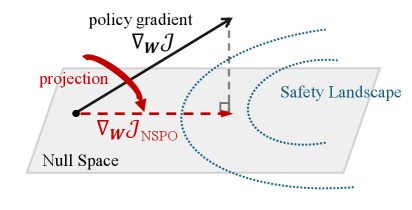
核心思路:NSPO的核心思路是将安全策略的梯度投影到通用任务策略梯度的零空间(Null-Space)中。这意味着安全策略的更新方向不会影响通用任务的性能。通过这种方式,可以在不损害模型原有能力的前提下,提升模型的安全性。
技术框架:NSPO的整体框架基于策略优化算法,例如PPO。其主要流程包括:1) 使用通用任务数据训练一个初始的LLM;2) 使用安全数据定义安全奖励函数;3) 在策略更新时,计算安全策略梯度和通用任务策略梯度;4) 将安全策略梯度投影到通用任务策略梯度的零空间;5) 使用投影后的梯度更新策略。
关键创新:NSPO的关键创新在于利用零空间投影来解耦安全策略和通用任务策略的更新。与现有方法相比,NSPO不需要大量混合通用任务数据,即可在保证通用能力的同时提升安全性。此外,论文还从理论上证明了NSPO能够保留模型原有的核心能力,并保证安全对齐的有效性。
关键设计:NSPO的关键设计包括:1) 精确计算通用任务策略梯度和安全策略梯度;2) 有效的零空间投影算法,确保投影后的梯度仍然能够提升安全性;3) 合理的安全奖励函数设计,引导模型学习安全的行为。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NSPO在PKU-SafeRLHF数据集上取得了state-of-the-art的安全性能,同时在数学、代码和指令跟随等通用任务上保持了较高的准确率。值得注意的是,NSPO仅使用40%的PKU-SafeRLHF数据即可达到现有方法的性能水平,展现了其数据效率优势。
🎯 应用场景
NSPO可应用于各种需要安全对齐的大型语言模型,例如聊天机器人、智能助手等。该方法能够提升这些模型在开放环境中的安全性,避免生成有害或不当内容,同时保证其在通用任务上的性能。这有助于提高用户信任度,并促进LLM在更广泛领域的应用。
📄 摘要(原文)
As Large Language Models (LLMs) are increasingly deployed in real-world applications, it is important to ensure their behaviors align with human values, societal norms, and ethical principles. However, safety alignment under Reinforcement Learning (RL) often suffers from forgetting learned general abilities, which is also known as the alignment tax. To address this issue, we introduce Null-Space constrained Policy Optimization (NSPO), a novel RL framework for LLM safety alignment while preserving their core abilities. The safety policy gradients are geometrically projected into the null space of general tasks, thereby mitigating the safety alignment tax. In addition, we theoretically prove that NSPO preserves the model's original core capabilities, while still guaranteeing a descent direction for effective safety alignment. Extensive experiments demonstrate that NSPO outperforms existing methods by a large margin, achieving state-of-the-art safety performance without sacrificing accuracy on general tasks, including math, code, and instruction-following tasks. Notably, NSPO is data-efficient and only requires 40% of public human-annotated safety data from PKU-SafeRLHF to achieve promising safety performance, without a large amount of mixed general tasks data in existing alignment methods.