DAPO: Design Structure-Aware Pass Ordering in High-Level Synthesis with Graph Contrastive and Reinforcement Learning
作者: Jinming Ge, Linfeng Du, Likith Anaparty, Shangkun Li, Tingyuan Liang, Afzal Ahmad, Vivek Chaturvedi, Sharad Sinha, Zhiyao Xie, Jiang Xu, Wei Zhang
分类: cs.LG
发布日期: 2025-12-12
备注: Accepted by DATE 2026
💡 一句话要点
DAPO:基于图对比学习与强化学习的高层次综合中设计结构感知的Pass排序
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 高层次综合 Pass排序 图对比学习 强化学习 FPGA 硬件加速 设计空间探索
📋 核心要点
- 现有HLS工具采用固定优化策略,无法针对特定设计进行有效优化,缺乏对设计语义的深入理解和硬件指标的准确估计。
- DAPO框架通过图对比学习提取程序语义,利用分析模型进行硬件指标估计,并结合强化学习搜索设计特定的优化策略。
- 实验结果表明,DAPO在经典HLS设计上实现了平均2.36倍的加速,显著优于Vitis HLS。
📝 摘要(中文)
高层次综合(HLS)工具在基于FPGA的领域专用加速器设计中被广泛采用。然而,现有的工具依赖于从软件编译继承而来的固定优化策略,限制了它们的有效性。为特定设计定制优化策略需要深入的语义理解、准确的硬件指标估计和先进的搜索算法——而当前的方法缺乏这些能力。我们提出了DAPO,一个设计结构感知的Pass排序框架,它从控制和数据流图中提取程序语义,采用对比学习生成丰富的嵌入,并利用分析模型进行准确的硬件指标估计。这些组件共同指导强化学习代理发现特定于设计的优化策略。在经典HLS设计上的评估表明,我们的端到端流程平均比Vitis HLS快2.36倍。
🔬 方法详解
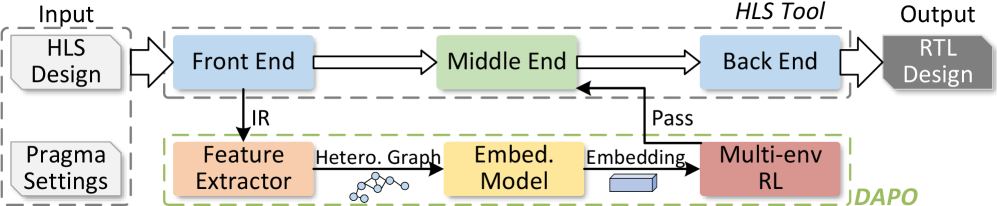
问题定义:论文旨在解决高层次综合(HLS)中Pass排序问题,即如何确定一系列优化Pass的最佳执行顺序,以最大化硬件性能。现有HLS工具通常采用固定的Pass排序策略,无法充分利用特定设计的特性,导致优化效果不佳。痛点在于缺乏对设计语义的深入理解和硬件指标的准确估计,难以找到最优的Pass排序方案。
核心思路:论文的核心思路是利用图对比学习提取程序语义,构建设计结构感知的嵌入表示,并结合分析模型进行硬件指标估计。然后,利用强化学习算法,以硬件性能为奖励,搜索特定于设计的Pass排序策略。这种方法能够根据设计的具体特征动态调整优化策略,从而获得更好的性能。
技术框架:DAPO框架包含三个主要模块:1) 图嵌入模块:从控制和数据流图中提取程序语义,使用图对比学习生成设计结构感知的嵌入表示。2) 硬件指标估计模块:利用分析模型估计不同Pass排序方案的硬件性能指标,如延迟、资源利用率等。3) 强化学习模块:使用强化学习算法,以硬件性能为奖励,搜索最优的Pass排序策略。这三个模块协同工作,实现设计特定的优化策略。
关键创新:DAPO的关键创新在于:1) 提出了一种基于图对比学习的设计结构感知嵌入方法,能够有效提取程序语义。2) 结合分析模型进行硬件指标估计,提高了估计的准确性。3) 利用强化学习算法自动搜索最优的Pass排序策略,避免了人工调整的繁琐和低效。与现有方法相比,DAPO能够更好地适应不同设计的特性,获得更高的性能。
关键设计:在图对比学习中,采用了GCN等图神经网络提取节点特征,并通过对比学习损失函数,使得相似的设计具有相似的嵌入表示。在硬件指标估计中,使用了基于资源约束的延迟模型。在强化学习中,使用了Actor-Critic算法,以硬件性能指标(如延迟)作为奖励信号,训练Agent选择合适的Pass排序。
🖼️ 关键图片


📊 实验亮点
DAPO在经典HLS设计上进行了评估,实验结果表明,DAPO的端到端流程平均比Vitis HLS快2.36倍。这一显著的性能提升证明了DAPO框架的有效性,表明其能够更好地适应不同设计的特性,获得更高的性能。
🎯 应用场景
DAPO可应用于FPGA加速器设计、领域专用计算等领域,通过自动优化HLS工具的Pass排序,提升硬件性能和资源利用率。该研究成果有助于降低FPGA开发的门槛,加速领域专用计算的普及,并为未来的HLS工具开发提供新的思路。
📄 摘要(原文)
High-Level Synthesis (HLS) tools are widely adopted in FPGA-based domain-specific accelerator design. However, existing tools rely on fixed optimization strategies inherited from software compilations, limiting their effectiveness. Tailoring optimization strategies to specific designs requires deep semantic understanding, accurate hardware metric estimation, and advanced search algorithms -- capabilities that current approaches lack. We propose DAPO, a design structure-aware pass ordering framework that extracts program semantics from control and data flow graphs, employs contrastive learning to generate rich embeddings, and leverages an analytical model for accurate hardware metric estimation. These components jointly guide a reinforcement learning agent to discover design-specific optimization strategies. Evaluations on classic HLS designs demonstrate that our end-to-end flow delivers a 2.36 speedup over Vitis HLS on average.