Benchmarking the Generality of Vision-Language-Action Models
作者: Pranav Guruprasad, Sudipta Chowdhury, Harsh Sikka, Mridul Sharma, Helen Lu, Sean Rivera, Aryan Khurana, Hangliang Ren, Yangyue Wang
分类: cs.LG
发布日期: 2025-12-12
备注: 23 pages, 7 figures, and 1 table
💡 一句话要点
MultiNet v1.0:用于评估视觉-语言-动作模型跨领域泛化能力的统一基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 视觉语言动作模型 跨领域泛化 多模态学习 机器人控制 基准测试 通用人工智能
📋 核心要点
- 现有VLM/VLA评估分散在孤立基准中,难以评估模型在训练分布外的泛化能力。
- 提出MultiNet v1.0,统一评估VLM/VLA在视觉定位、空间推理等六个能力上的跨领域泛化性。
- 实验表明,现有模型在未见领域、模态或任务转移时性能显著下降,揭示了通用智能的差距。
📝 摘要(中文)
通用多模态智能体有望统一感知、语言和控制,并在各种真实世界领域中稳健运行。然而,当前的评估方法仍然分散在孤立的基准测试中,难以评估当前的基础模型是否真正泛化到其训练分布之外。我们推出了MultiNet v1.0,这是一个统一的基准,用于衡量视觉语言模型(VLM)和视觉语言动作模型(VLA)在六个基础能力体系中的跨领域泛化能力:视觉定位、空间推理、工具使用、物理常识、多智能体协调和连续机器人控制。通过评估GPT-5、Pi0和Magma,我们发现没有模型表现出一致的泛化能力。尽管在训练分布中表现出色,但所有模型在未见过的领域、不熟悉的模态或跨领域任务转移时都表现出显著的性能下降。这些失败表现为模态错位、输出格式不稳定以及领域转移下的灾难性知识退化。我们的研究结果揭示了通用智能的愿景与当前基础模型的实际能力之间仍然存在差距。MultiNet v1.0提供了一个标准化的评估基础,用于诊断这些差距并指导未来通用智能体的开发。代码、数据和排行榜已公开。
🔬 方法详解
问题定义:论文旨在解决当前视觉-语言-动作模型(VLM/VLA)评估体系的碎片化问题。现有评估方法通常针对特定任务或领域,缺乏一个统一的基准来衡量模型在不同领域和任务上的泛化能力。这使得我们难以判断模型是否真正具备通用智能,还是仅仅在特定训练数据上表现良好。现有方法的痛点在于无法有效诊断模型在跨领域泛化方面的不足,阻碍了通用智能体的开发。
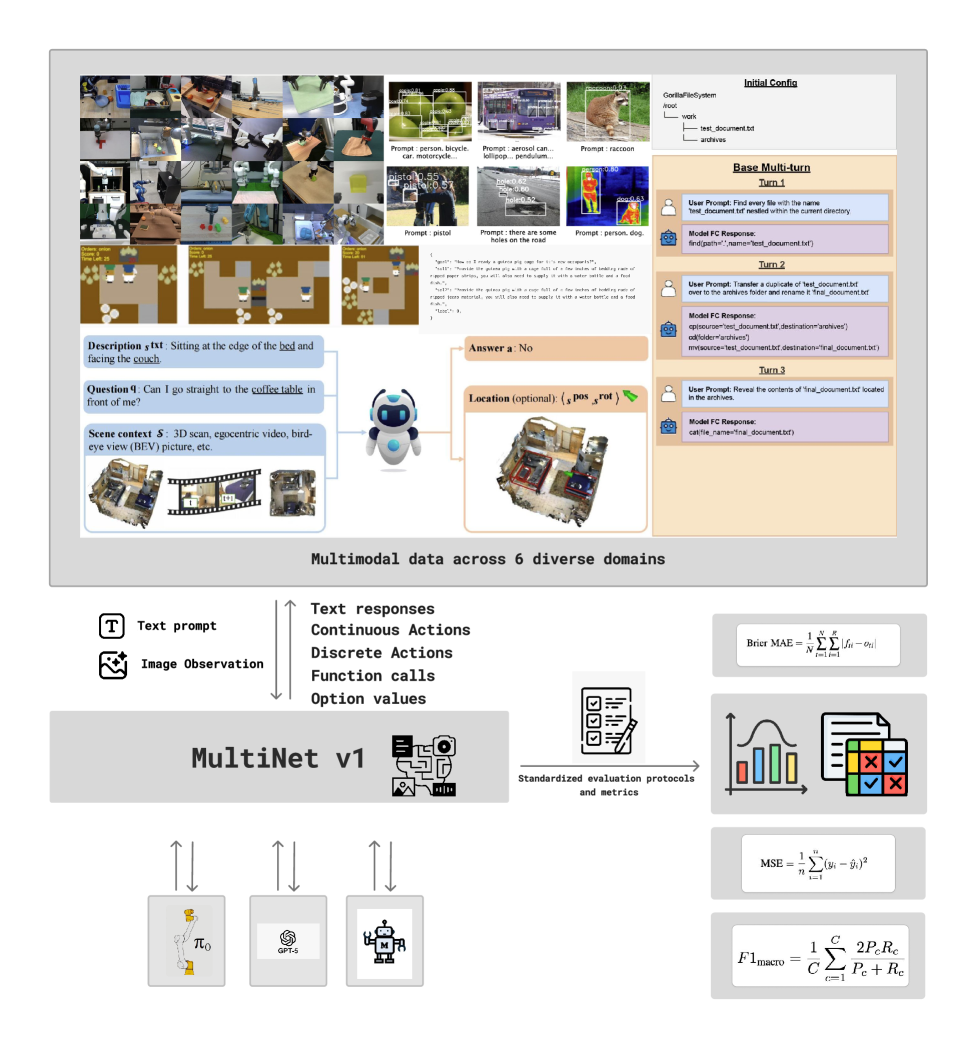
核心思路:论文的核心思路是构建一个综合性的评估基准MultiNet v1.0,该基准覆盖了六个关键的通用能力领域:视觉定位、空间推理、工具使用、物理常识、多智能体协调和连续机器人控制。通过在这些不同领域和任务上评估模型,可以更全面地了解模型的泛化能力,并识别其在特定方面的弱点。这样设计的目的是为了提供一个标准化的平台,促进VLM/VLA的公平比较和持续改进。
技术框架:MultiNet v1.0作为一个评估基准,其技术框架主要体现在数据集和评估协议的设计上。它包含多个来自不同领域的数据集,这些数据集被组织成六个能力类别。评估协议定义了如何在这些数据集上测试模型,并使用统一的指标来衡量模型的性能。具体来说,评估流程包括:(1) 输入视觉和语言信息给VLM/VLA模型;(2) 模型根据输入生成动作或输出;(3) 根据预定义的评估指标,将模型的输出与ground truth进行比较,计算性能得分。
关键创新:MultiNet v1.0的关键创新在于其统一性和综合性。它首次将多个不同领域的任务整合到一个统一的评估框架中,从而能够更全面地评估VLM/VLA的泛化能力。与以往专注于特定任务的评估方法相比,MultiNet v1.0能够更好地揭示模型在跨领域泛化方面的不足,并为未来的研究提供更清晰的方向。
关键设计:MultiNet v1.0的关键设计体现在数据集的选择和评估指标的定义上。数据集的选择需要覆盖不同的领域和任务,以确保评估的全面性。评估指标需要能够准确地反映模型在不同能力上的表现。论文中可能涉及到针对不同任务的特定评估指标,例如,在机器人控制任务中,可能会使用成功率、路径长度等指标;在视觉定位任务中,可能会使用准确率、召回率等指标。具体的参数设置和网络结构取决于被评估的VLM/VLA模型,MultiNet v1.0本身并不限定模型的具体实现。
🖼️ 关键图片
📊 实验亮点
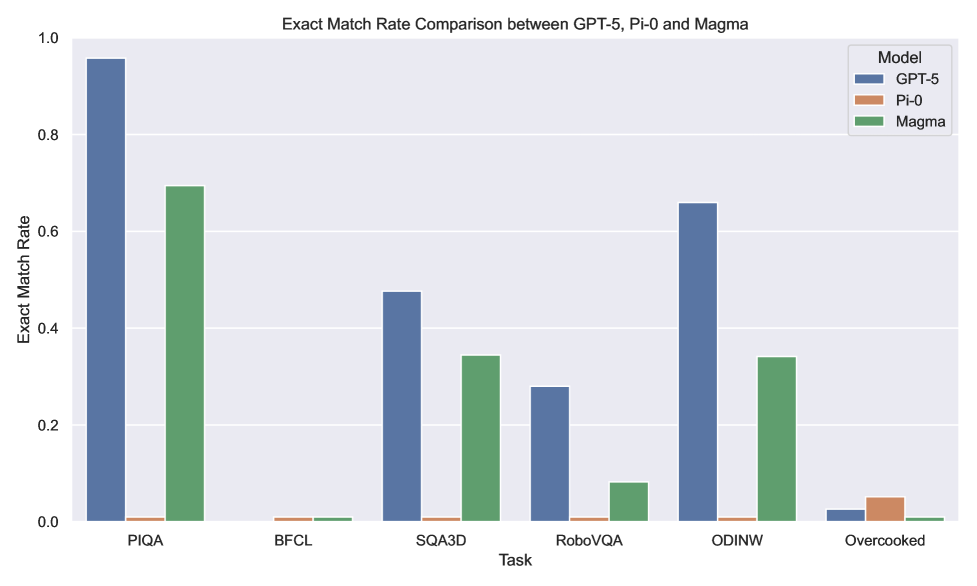
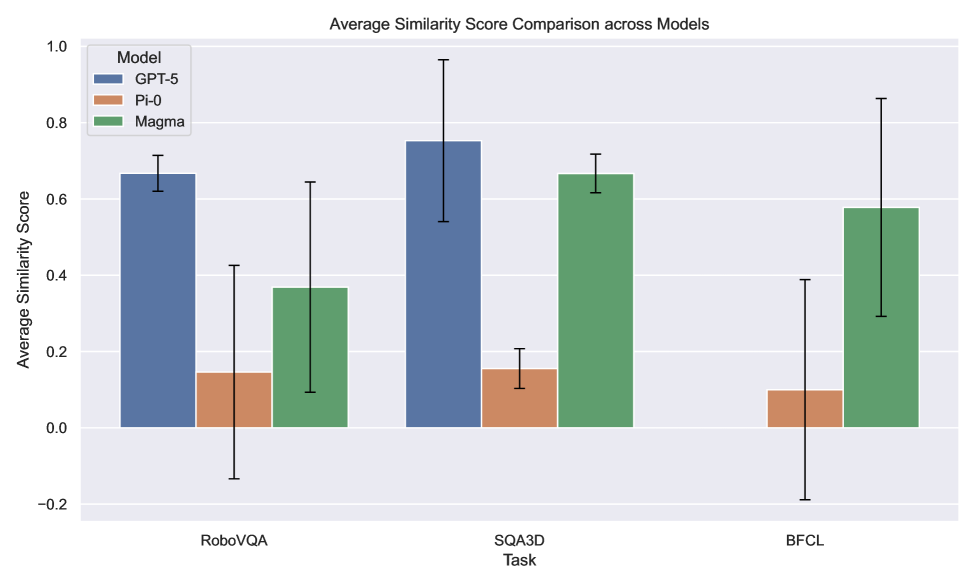
实验结果表明,即使是GPT-5、Pi0和Magma等先进模型,在MultiNet v1.0的跨领域评估中也表现出显著的性能下降。具体而言,模型在未见过的领域、不熟悉的模态或跨领域任务转移时,性能大幅降低,揭示了当前VLM/VLA在泛化能力方面的局限性。这些发现强调了开发更具通用性和鲁棒性的模型的重要性。
🎯 应用场景
该研究成果可广泛应用于机器人、自动驾驶、智能助手等领域。通过MultiNet v1.0的评估,可以更有效地开发出具备更强通用性和适应性的智能体,使其能够在复杂多变的环境中完成各种任务。未来,该基准有望推动通用人工智能的发展,并加速智能体在现实世界中的部署。
📄 摘要(原文)
Generalist multimodal agents are expected to unify perception, language, and control - operating robustly across diverse real world domains. However, current evaluation practices remain fragmented across isolated benchmarks, making it difficult to assess whether today's foundation models truly generalize beyond their training distributions. We introduce MultiNet v1.0, a unified benchmark for measuring the cross domain generality of vision language models (VLMs) and vision language action models (VLAs) across six foundational capability regimes. Visual grounding, spatial reasoning, tool use, physical commonsense, multi agent coordination, and continuous robot control. Evaluating GPT 5, Pi0, and Magma, we find that no model demonstrates consistent generality. All exhibit substantial degradation on unseen domains, unfamiliar modalities, or cross domain task shifts despite strong performance within their training distributions.These failures manifest as modality misalignment, output format instability, and catastrophic knowledge degradation under domain transfer.Our findings reveal a persistent gap between the aspiration of generalist intelligence and the actual capabilities of current foundation models.MultiNet v1.0 provides a standardized evaluation substrate for diagnosing these gaps and guiding the development of future generalist agents.Code, data, and leaderboards are publicly available.