Insight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
作者: Yunkai Zhang, Yawen Zhang, Ming Zheng, Kezhen Chen, Chongyang Gao, Ruian Ge, Siyuan Teng, Amine Jelloul, Jinmeng Rao, Xiaoyuan Guo, Chiang-Wei Fang, Zeyu Zheng, Jie Yang
分类: cs.LG
发布日期: 2025-12-12
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出Insight Miner,一个基于大规模多模态模型的时间序列分析框架,并构建了首个通用领域时间序列-语言对齐数据集TS-Insights。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分析 多模态模型 自然语言处理 指令微调 领域知识 时间序列描述 大规模数据集
📋 核心要点
- 现有时间序列分析依赖领域专家,耗时费力,缺乏通用性和自动化。
- Insight Miner利用大规模多模态模型,结合统计特征提取和GPT-4生成,实现时间序列的自动描述和洞察挖掘。
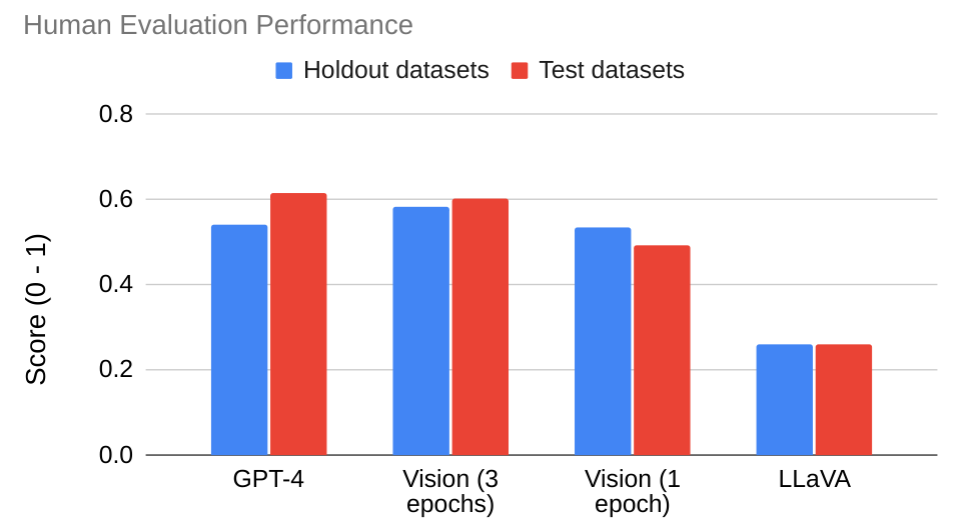
- 在TS-Insights数据集上,Insight Miner超越了LLaVA和GPT-4等先进模型,验证了其有效性。
📝 摘要(中文)
时间序列数据在环境分析、农业、交通运输和金融等众多科学和工业领域至关重要。然而,从此类数据中挖掘洞察通常需要深厚的领域专业知识,这个过程既耗时又费力。在本文中,我们提出了Insight Miner,一个大规模多模态模型(LMM),旨在生成高质量、全面的时间序列描述,并富含特定领域的知识。为了实现这一目标,我们引入了TS-Insights,这是第一个用于时间序列和语言对齐的通用领域数据集。TS-Insights包含从20个预测数据集中抽样的10万个时间序列窗口。我们使用一种新颖的agentic workflow构建了这个数据集,在该工作流程中,我们使用统计工具从原始时间序列中提取特征,然后使用GPT-4将它们合成为连贯的趋势描述。在TS-Insights上进行指令微调后,Insight Miner在生成时间序列描述和洞察方面优于最先进的多模态模型,如LLaVA和GPT-4。我们的研究结果表明,在时间序列分析中利用LMM是一个很有前景的方向,并且是使LLM能够将时间序列解释为原生输入模态的基础步骤。
🔬 方法详解
问题定义:现有时间序列分析方法需要领域专家进行手动分析,过程耗时且成本高昂,缺乏通用性和自动化能力。现有的多模态模型在处理时间序列数据时表现不佳,无法有效提取和理解时间序列中的信息。
核心思路:论文的核心思路是利用大规模多模态模型(LMM)学习时间序列数据和自然语言描述之间的对应关系。通过构建一个高质量的时间序列-语言对齐数据集,并在此数据集上对LMM进行指令微调,使模型能够自动生成时间序列的描述和洞察。
技术框架:Insight Miner的整体框架包括数据准备、特征提取、描述生成和模型训练四个主要阶段。首先,从多个时间序列数据集中采样时间序列窗口。然后,使用统计工具提取时间序列的特征。接着,利用GPT-4等大型语言模型将提取的特征合成为连贯的趋势描述。最后,使用TS-Insights数据集对LMM进行指令微调,使其能够生成高质量的时间序列描述。
关键创新:论文的关键创新在于构建了首个通用领域的时间序列-语言对齐数据集TS-Insights,并提出了一种新颖的agentic workflow来生成该数据集。此外,论文还展示了通过指令微调LMM,可以有效提升其在时间序列分析任务中的性能。
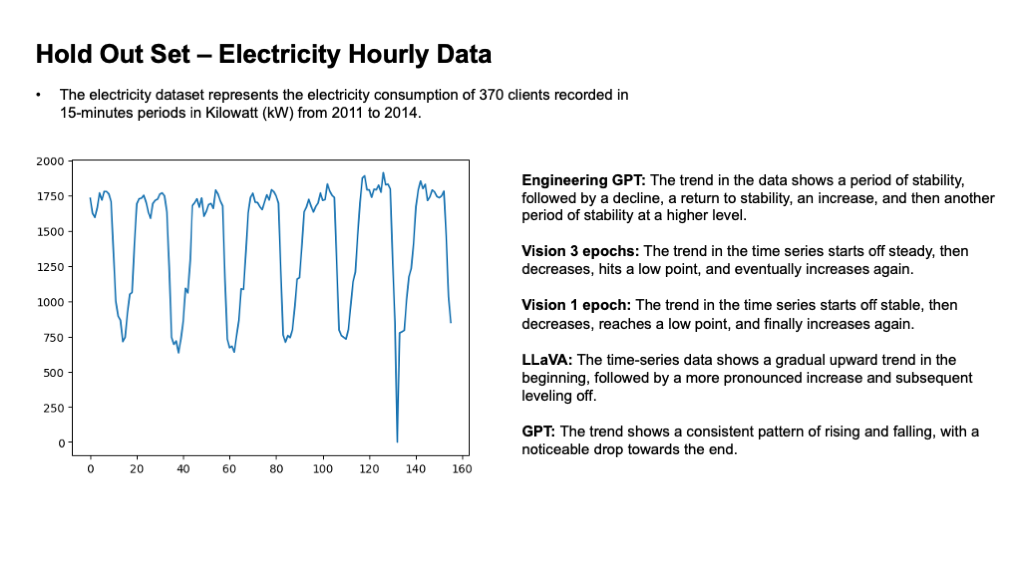
关键设计:TS-Insights数据集包含10万个时间序列窗口,采样自20个不同的预测数据集。Agentic workflow使用多种统计工具提取时间序列的特征,包括趋势、季节性和周期性等。GPT-4被用于将提取的特征合成为自然语言描述。Insight Miner使用指令微调方法,在TS-Insights数据集上对LMM进行训练,目标是最小化生成描述与真实描述之间的差异。
🖼️ 关键图片

📊 实验亮点
Insight Miner在TS-Insights数据集上进行了评估,结果表明其在生成时间序列描述和洞察方面优于LLaVA和GPT-4等先进的多模态模型。实验结果验证了Insight Miner在时间序列分析任务中的有效性,并表明LMM在处理时间序列数据方面具有巨大的潜力。
🎯 应用场景
Insight Miner可应用于金融、环境监测、交通运输、农业等多个领域,帮助用户快速理解和分析时间序列数据,发现潜在的趋势和模式。该研究为LLM在时间序列分析中的应用奠定了基础,未来可扩展到更复杂的时序预测和异常检测任务。
📄 摘要(原文)
Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.