Multi-Objective Reinforcement Learning for Large-Scale Mixed Traffic Control
作者: Iftekharul Islam, Weizi Li
分类: cs.MA, cs.LG
发布日期: 2025-12-12
💡 一句话要点
提出基于多目标强化学习的大规模混合交通控制框架,提升公平性和安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 多目标强化学习 混合交通控制 交通信号优化 公平性 安全性
📋 核心要点
- 现有混合交通控制方法在效率和安全性约束方面表现出色,但缺乏确保公平性的机制,导致低需求车辆的系统性拥堵。
- 论文提出一种分层框架,结合多目标强化学习进行局部交叉口控制,以及战略路由进行网络级协调,以平衡效率、公平性和安全性。
- 实验结果表明,该方法在降低等待时间、减少最大拥堵和降低冲突率方面均有显著提升,同时保持燃油效率。
📝 摘要(中文)
本文提出了一种用于大规模混合交通控制的分层框架,该框架结合了用于局部交叉口控制的多目标强化学习和用于网络级协调的战略路由。该方法引入了冲突威胁向量,为智能体提供显式的风险信号以主动避免冲突,并引入了队列奇偶性惩罚,以确保所有交通流的公平服务。在真实网络上进行的大量实验表明,与基线相比,平均等待时间减少高达53%,最大拥堵减少高达86%,冲突率降低高达86%,同时保持了燃油效率。分析表明,战略路由的有效性随机器人车辆(RV)渗透率的提高而提高,在更高的自主水平下变得越来越有价值。结果表明,通过精心设计的奖励函数进行多目标优化,并结合战略性RV路由,可以在公平性和安全性指标方面产生显著效益,这对于公平的混合自主部署至关重要。
🔬 方法详解
问题定义:现有混合交通控制方法难以在效率、公平性和安全性之间取得平衡,尤其是在公平性方面,容易导致低需求交通流的车辆长时间等待,产生系统性的拥堵问题。因此,需要设计一种能够同时优化多个目标,并确保所有交通流都能获得公平服务的控制策略。
核心思路:论文的核心思路是利用多目标强化学习来学习局部交叉口的控制策略,并通过战略路由来协调网络级别的交通流。通过精心设计的奖励函数,鼓励智能体在优化效率的同时,兼顾公平性和安全性。冲突威胁向量用于提供风险信号,队列奇偶性惩罚用于确保公平服务。
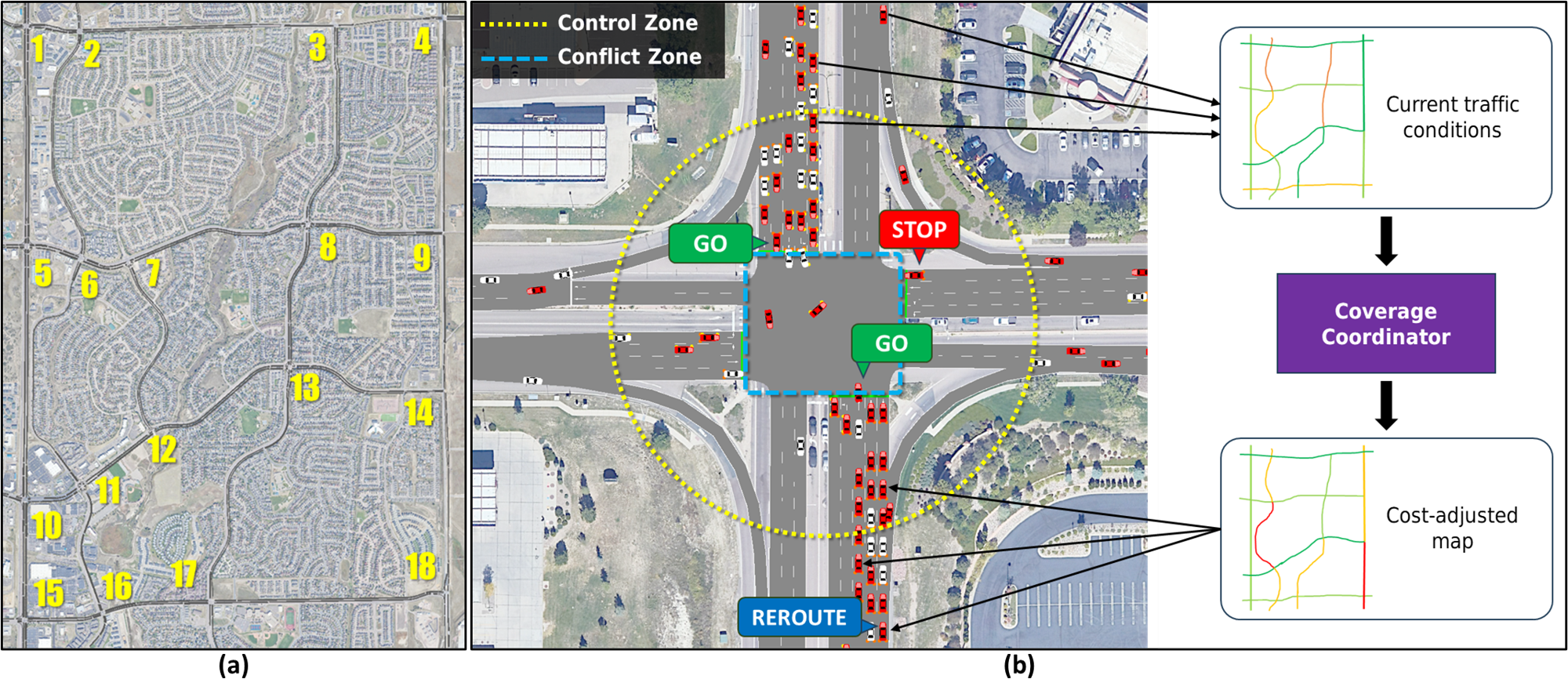
技术框架:该框架是一个分层结构,包含两个主要模块:1) 局部交叉口控制模块:使用多目标强化学习智能体控制每个交叉口的信号灯相位,目标是优化效率、公平性和安全性。智能体接收冲突威胁向量和队列长度等信息作为输入,输出信号灯相位。2) 网络级战略路由模块:根据全局交通状况,为机器人车辆(RV)规划最优路径,以缓解拥堵,提高整体效率。
关键创新:论文的关键创新在于:1) 引入了冲突威胁向量,为智能体提供显式的风险信号,使其能够主动避免潜在的冲突。2) 设计了队列奇偶性惩罚,鼓励智能体公平地服务于所有交通流,避免低需求交通流的车辆长时间等待。3) 提出了一个分层框架,将局部交叉口控制和网络级战略路由相结合,实现了全局优化。
关键设计:在多目标强化学习中,奖励函数由三个部分组成:效率奖励(例如,减少车辆等待时间)、公平性奖励(例如,队列奇偶性惩罚)和安全性奖励(例如,避免冲突)。冲突威胁向量的计算方式未知,但其目的是量化潜在的冲突风险。战略路由模块的具体实现方式未知,但其目标是为RV规划最优路径。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与基线方法相比,该方法在真实交通网络中取得了显著的性能提升。具体而言,平均等待时间减少高达53%,最大拥堵减少高达86%,冲突率降低高达86%,同时保持了燃油效率。此外,实验还表明,战略路由的有效性随机器人车辆(RV)渗透率的提高而提高,在更高的自主水平下变得越来越有价值。
🎯 应用场景
该研究成果可应用于智能交通系统,特别是混合交通环境下的交通信号控制和车辆路径规划。通过平衡效率、公平性和安全性,可以提升城市交通的整体运行效率,改善交通拥堵状况,并为自动驾驶车辆的部署提供更安全、更公平的交通环境。该方法对于提升城市交通的可持续性和宜居性具有重要意义。
📄 摘要(原文)
Effective mixed traffic control requires balancing efficiency, fairness, and safety. Existing approaches excel at optimizing efficiency and enforcing safety constraints but lack mechanisms to ensure equitable service, resulting in systematic starvation of vehicles on low-demand approaches. We propose a hierarchical framework combining multi-objective reinforcement learning for local intersection control with strategic routing for network-level coordination. Our approach introduces a Conflict Threat Vector that provides agents with explicit risk signals for proactive conflict avoidance, and a queue parity penalty that ensures equitable service across all traffic streams. Extensive experiments on a real-world network across different robot vehicle (RV) penetration rates demonstrate substantial improvements: up to 53% reductions in average wait time, up to 86% reductions in maximum starvation, and up to 86\% reduction in conflict rate compared to baselines, while maintaining fuel efficiency. Our analysis reveals that strategic routing effectiveness scales with RV penetration, becoming increasingly valuable at higher autonomy levels. The results demonstrate that multi-objective optimization through well-curated reward functions paired with strategic RV routing yields significant benefits in fairness and safety metrics critical for equitable mixed-autonomy deployment.