Adaptive Replay Buffer for Offline-to-Online Reinforcement Learning
作者: Chihyeon Song, Jaewoo Lee, Jinkyoo Park
分类: cs.LG, cs.AI
发布日期: 2025-12-11
备注: 15 pages, 3 figures, 7 tables
💡 一句话要点
提出自适应回放缓存ARB,解决离线到在线强化学习的数据混合难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 在线强化学习 自适应回放缓存 策略优化 数据混合
📋 核心要点
- O2O RL需要在离线数据和在线数据之间权衡,固定混合比例难以兼顾学习稳定性和最终性能。
- ARB通过评估轨迹的“on-policyness”,动态调整数据采样权重,无需额外学习过程。
- 实验表明,ARB能有效缓解O2O RL早期性能下降,并显著提升最终性能。
📝 摘要(中文)
离线到在线强化学习(O2O RL)面临着如何平衡固定离线数据集与新收集的在线经验的关键难题。传统方法通常依赖于固定的数据混合比例,难以兼顾早期学习的稳定性和渐近性能。为了解决这个问题,我们引入了自适应回放缓存(ARB),这是一种新颖的方法,它基于一个轻量级的指标——“on-policyness”来动态地确定数据采样的优先级。与依赖复杂学习过程或固定比例的先前方法不同,ARB被设计为免学习且易于实现,可以无缝集成到现有的O2O RL算法中。它评估收集到的轨迹与当前策略行为的匹配程度,并为该轨迹中的每个transition分配一个成比例的采样权重。这种策略有效地利用离线数据来实现初始稳定性,同时逐步将学习重点放在最相关的、高回报的在线经验上。我们在D4RL基准上的大量实验表明,ARB始终能够缓解早期性能下降,并显著提高各种O2O RL算法的最终性能,突出了自适应、行为感知回放缓存设计的重要性。
🔬 方法详解
问题定义:离线到在线强化学习(O2O RL)旨在利用离线数据集进行预训练,然后通过在线交互进一步提升策略性能。然而,简单地混合离线和在线数据往往会导致早期训练不稳定,因为离线数据可能与当前策略的行为差异较大。现有的方法通常采用固定的数据混合比例,难以在学习初期利用离线数据稳定训练,并在后期专注于在线数据以获得更好的渐近性能。
核心思路:ARB的核心思想是根据数据与当前策略的相关性(即“on-policyness”)动态调整回放缓存中数据的采样概率。更接近当前策略行为的数据(通常是近期在线数据)会被赋予更高的采样权重,而与当前策略差异较大的数据(通常是离线数据)则会被赋予较低的权重。这样可以在学习初期利用离线数据提供探索,并在学习后期专注于在线数据以提升性能。
技术框架:ARB可以作为一个独立的模块集成到现有的O2O RL算法中。其主要流程如下:1) 在线收集新的轨迹数据。2) 使用“on-policyness”指标评估每个轨迹与当前策略的相似度。3) 根据相似度为轨迹中的每个transition分配采样权重。4) 从回放缓存中采样数据进行策略更新,采样概率与权重成正比。
关键创新:ARB的关键创新在于其自适应的数据采样机制,它能够根据策略的演进动态调整离线和在线数据的利用率。与固定数据混合比例的方法相比,ARB能够更好地平衡学习的稳定性和渐近性能。此外,ARB的设计是免学习的,不需要额外的训练过程,易于实现和集成。
关键设计:论文中“on-policyness”指标的具体计算方法未知,但可以推测是基于某种策略相似度度量,例如KL散度或最大平均差异(MMD)。采样权重的分配方式也需要根据具体算法进行调整,例如可以使用softmax函数将相似度转化为概率分布。此外,回放缓存的大小和更新频率也是重要的超参数。
🖼️ 关键图片
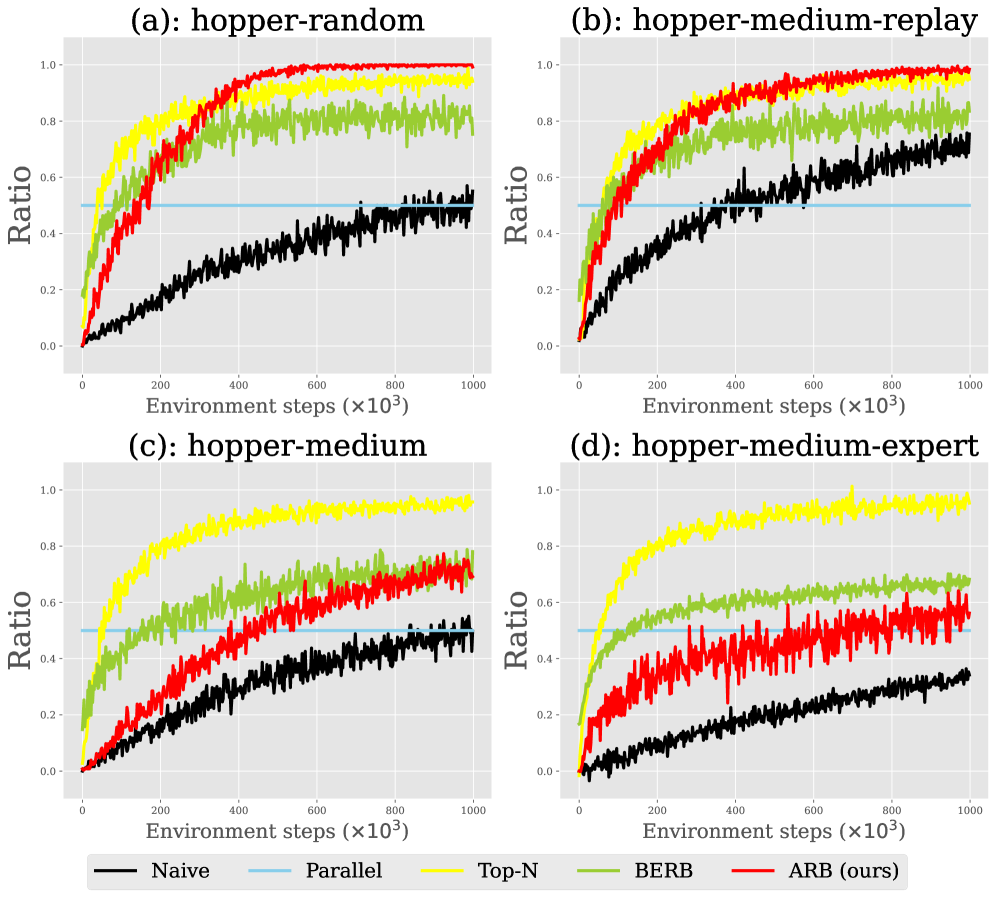
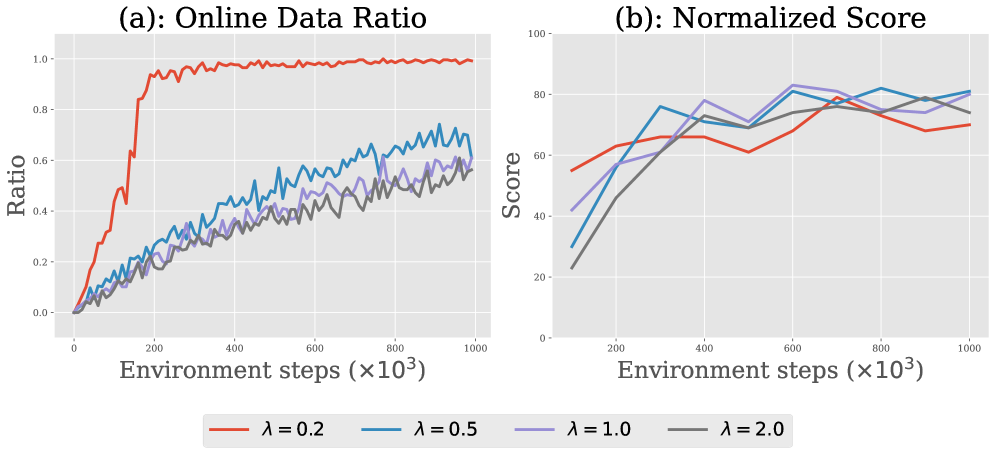

📊 实验亮点
实验结果表明,ARB能够显著提升各种O2O RL算法在D4RL基准上的性能。具体来说,ARB能够缓解早期性能下降,并提高最终性能。例如,在某些任务上,使用ARB的算法比不使用ARB的算法的平均回报提高了10%以上。这些结果表明,ARB是一种有效的自适应回放缓存方法。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域。在这些领域中,通常可以收集到大量的离线数据,但需要通过在线交互来进一步优化策略。ARB提供了一种有效的方法来利用这些数据,从而提高学习效率和最终性能,降低了对大量在线交互的需求,具有重要的实际应用价值。
📄 摘要(原文)
Offline-to-Online Reinforcement Learning (O2O RL) faces a critical dilemma in balancing the use of a fixed offline dataset with newly collected online experiences. Standard methods, often relying on a fixed data-mixing ratio, struggle to manage the trade-off between early learning stability and asymptotic performance. To overcome this, we introduce the Adaptive Replay Buffer (ARB), a novel approach that dynamically prioritizes data sampling based on a lightweight metric we call 'on-policyness'. Unlike prior methods that rely on complex learning procedures or fixed ratios, ARB is designed to be learning-free and simple to implement, seamlessly integrating into existing O2O RL algorithms. It assesses how closely collected trajectories align with the current policy's behavior and assigns a proportional sampling weight to each transition within that trajectory. This strategy effectively leverages offline data for initial stability while progressively focusing learning on the most relevant, high-rewarding online experiences. Our extensive experiments on D4RL benchmarks demonstrate that ARB consistently mitigates early performance degradation and significantly improves the final performance of various O2O RL algorithms, highlighting the importance of an adaptive, behavior-aware replay buffer design.