LLaDA2.0: Scaling Up Diffusion Language Models to 100B
作者: Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Liwang Zhu, Yihong Zhuang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-10 (更新: 2025-12-24)
备注: 19 pages
💡 一句话要点
LLaDA2.0:通过扩散语言模型扩展至1000亿参数,实现高效部署。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 大规模语言模型 自回归模型 知识继承 混合专家模型
📋 核心要点
- 现有自回归模型训练成本高昂,难以扩展到更大规模,且推理效率存在瓶颈。
- LLaDA2.0通过将预训练的自回归模型转换为离散扩散语言模型,实现知识继承和高效扩展。
- 该方法在16B和100B参数规模上验证了有效性,并在性能和效率上均有提升,模型已开源。
📝 摘要(中文)
本文介绍了LLaDA2.0,这是一组离散扩散大型语言模型(dLLM),通过从自回归(AR)模型进行系统转换,扩展到总计1000亿参数,为前沿规模的部署建立了一个新的范例。LLaDA2.0没有从头开始进行昂贵的训练,而是坚持知识继承、渐进适应和效率感知的设计原则,并通过一种新颖的基于三阶段块级WSD的训练方案,将预训练的AR模型无缝转换为dLLM:在块扩散中逐步增加块大小(预热),大规模全序列扩散(稳定)和恢复到紧凑大小的块扩散(衰减)。通过与SFT和DPO的后训练对齐,我们获得了LLaDA2.0-mini (16B)和LLaDA2.0-flash (100B),这是两个针对实际部署优化的指令调整的混合专家(MoE)变体。通过保留并行解码的优势,这些模型在前沿规模上提供了卓越的性能和效率。这两个模型都是开源的。
🔬 方法详解
问题定义:现有的大型语言模型主要采用自回归(AR)架构,虽然在生成任务上表现出色,但训练成本随着模型规模的增长而急剧增加。此外,自回归模型的推理过程是串行的,难以充分利用并行计算资源,导致推理效率较低。因此,如何降低训练成本,提高推理效率,是当前大型语言模型面临的重要挑战。
核心思路:LLaDA2.0的核心思路是将预训练的自回归模型转换为离散扩散语言模型(dLLM)。扩散模型具有并行解码的优势,可以显著提高推理效率。通过知识继承和渐进适应,避免了从头开始训练扩散模型的高昂成本。
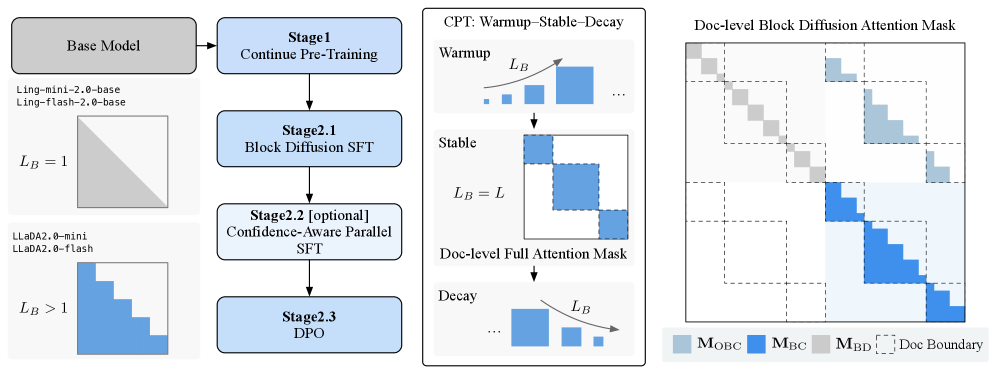
技术框架:LLaDA2.0的整体框架包含三个主要阶段:预热阶段(warm-up)、稳定阶段(stable)和衰减阶段(decay)。在预热阶段,逐步增加块大小进行块扩散;在稳定阶段,进行大规模全序列扩散;在衰减阶段,恢复到紧凑大小的块扩散。此外,还采用了SFT(Supervised Fine-Tuning)和DPO(Direct Preference Optimization)进行后训练对齐,以提升模型的指令遵循能力。
关键创新:LLaDA2.0的关键创新在于提出了一种三阶段块级WSD(Word Sense Disambiguation)训练方案,用于将预训练的自回归模型转换为离散扩散语言模型。该方案通过渐进增加块大小、全序列扩散和块大小衰减,实现了知识继承和高效训练。与从头开始训练扩散模型相比,该方法显著降低了训练成本。
关键设计:LLaDA2.0采用了混合专家(MoE)架构,以进一步提高模型容量和性能。在训练过程中,使用了块级WSD损失函数,以确保扩散过程能够保留原始自回归模型的语义信息。此外,还对SFT和DPO的超参数进行了精细调整,以获得最佳的指令遵循效果。
🖼️ 关键图片
📊 实验亮点
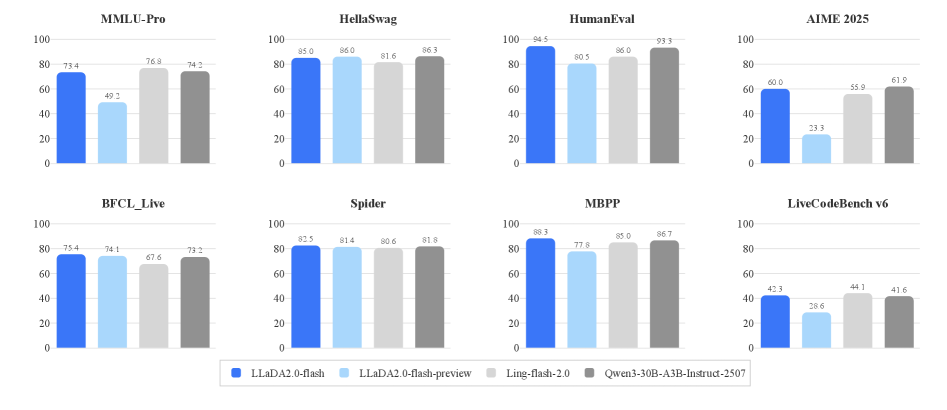
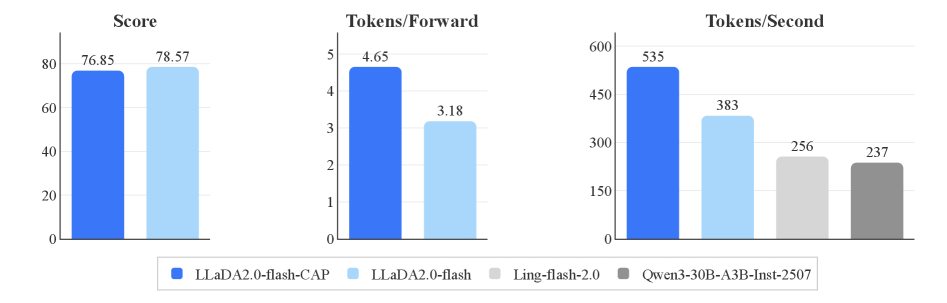
LLaDA2.0在16B和100B参数规模上进行了实验验证。实验结果表明,LLaDA2.0在性能和效率上均优于现有的自回归模型。具体而言,LLaDA2.0-flash (100B) 在多个benchmark上取得了领先的性能,同时保持了较高的推理速度。开源的LLaDA2.0模型为社区提供了强大的基础模型。
🎯 应用场景
LLaDA2.0具有广泛的应用前景,可用于各种自然语言处理任务,如文本生成、机器翻译、对话系统等。其高效的推理能力使其特别适用于需要快速响应的场景,如在线客服、智能助手等。此外,LLaDA2.0的开源特性将促进扩散模型在自然语言处理领域的进一步研究和应用。
📄 摘要(原文)
This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.