SIP-BMM: Constructing Capability-Efficiency Pareto Set of LLMs via Bayesian Model Merging with Structural Importance Prior
作者: Kesheng Chen, Yamin Hu, Zhenqian Zhu, Yiya Diao, Wenjian Luo
分类: cs.LG, cs.CL, cs.NE
发布日期: 2025-12-10 (更新: 2026-01-18)
🔗 代码/项目: GITHUB
💡 一句话要点
SIP-BMM:通过结构重要性先验的贝叶斯模型合并构建LLM的能力-效率帕累托集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型合并 贝叶斯优化 结构重要性先验 帕累托最优 能力-效率权衡 模型压缩
📋 核心要点
- 现有模型合并方法在LLM能力-效率权衡中存在不足,粗粒度方法解稀疏,细粒度方法面临维度灾难。
- SIP-BMM通过引入结构重要性先验(SIP),引导贝叶斯优化器关注重要层,降低搜索空间维度。
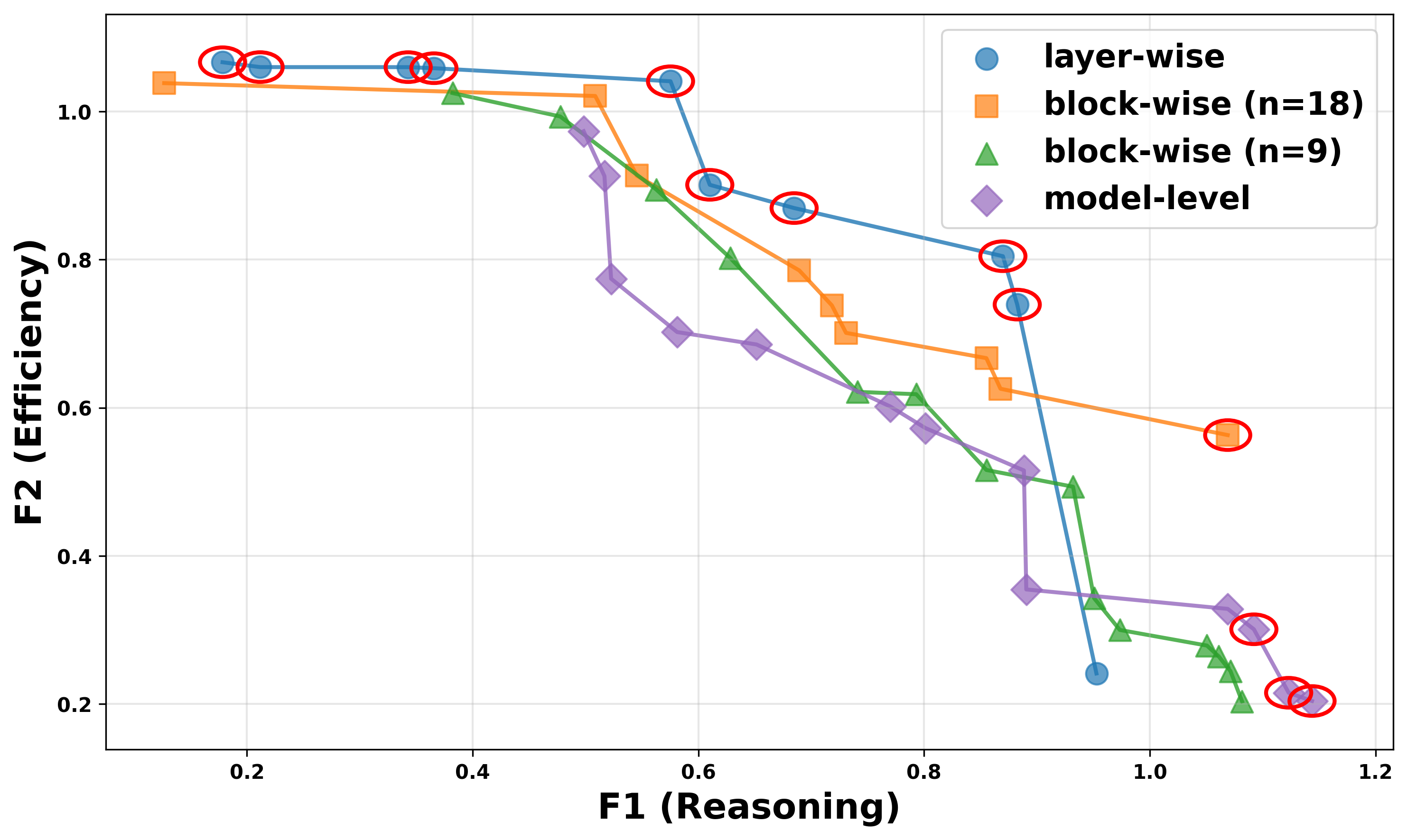
- 实验表明,SIP-BMM能够发现更优、更密集的帕累托前沿,提升模型选择的灵活性。
📝 摘要(中文)
在大语言模型(LLM)中,平衡能力和效率需要在帕累托最优解集中进行选择。然而,现有的模型合并技术存在不足:粗粒度的模型级方法只能产生稀疏的次优解,而细粒度的层级优化则面临维度灾难,尤其是在评估预算紧张的情况下,每个模型候选的评估成本都很高。我们提出了基于结构重要性先验的贝叶斯模型合并(SIP-BMM),这是一个由Log-Noisy Expected Hypervolume Improvement ($q$NEHVI)驱动的演化循环框架,通过显式建模哪些层是重要的,使层级帕累托集构建变得可行。具体来说,SIP-BMM从基础模型和专家模型之间的层级任务向量差异中推导出 extbf{结构重要性先验(SIP)},并使用该先验进行贝叶斯优化,从而降低有效维度子空间。直观地说,SIP引导优化器将大部分试验集中在一小部分有影响力的层上,而忽略那些表现出最小任务相关变化的层。这种重要性感知搜索保留了层级控制,同时大大降低了样本复杂度。实验表明,SIP-BMM发现了比竞争基线更强、更密集的帕累托前沿,从而能够在不同的操作约束下进行敏捷的模型选择。代码可在https://github.com/MiLab-HITSZ/2026-SIPBMM获取。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)能力与效率之间的权衡问题,具体来说,是如何在有限的计算资源下,构建一个高质量的帕累托最优模型集合,以便根据不同的应用场景和约束条件选择合适的模型。现有模型合并方法,如模型层面的粗粒度合并,只能得到稀疏且次优的解;而层面的细粒度合并,则会面临维度灾难,尤其是在评估预算有限的情况下,每个模型的评估成本很高。
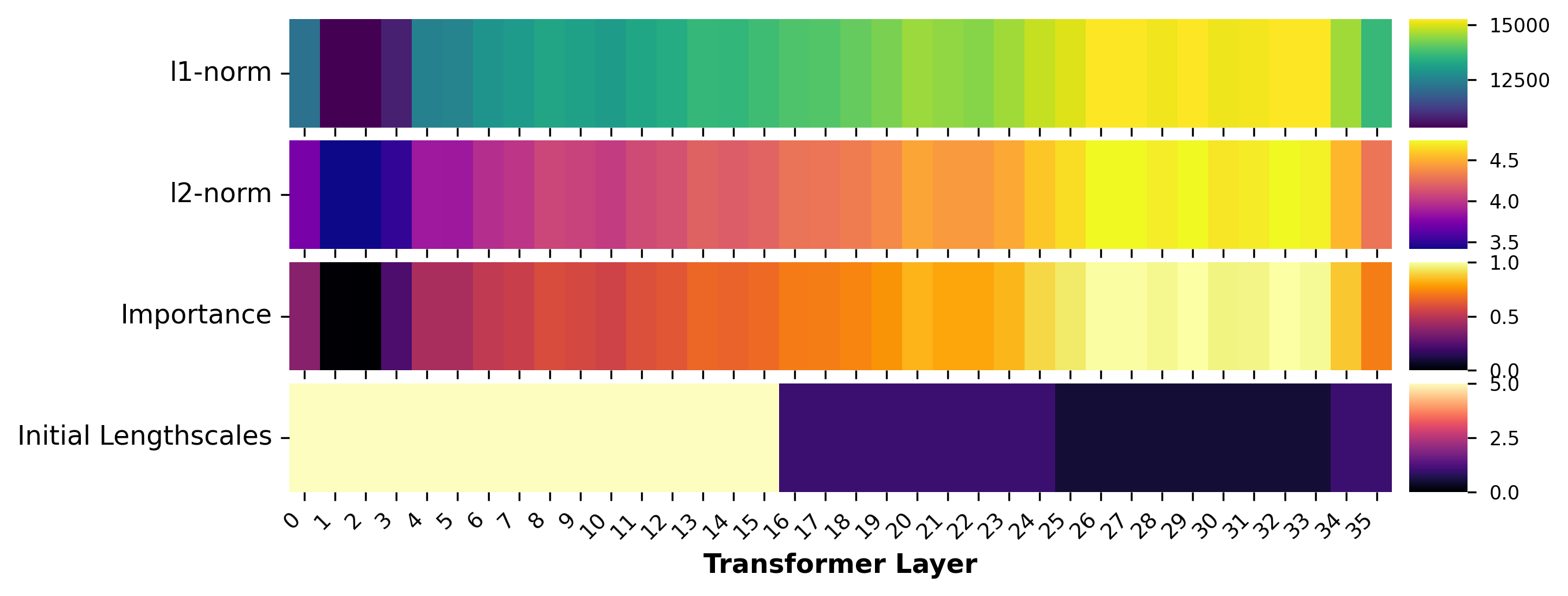
核心思路:论文的核心思路是利用贝叶斯优化,并引入一个结构重要性先验(Structural Importance Prior, SIP),来指导优化器在层级结构上进行搜索。SIP通过分析基础模型和专家模型之间的任务向量差异,确定哪些层对特定任务的性能提升最为关键。然后,优化器会优先关注这些重要层,而忽略那些影响较小的层,从而降低搜索空间的维度,提高效率。
技术框架:SIP-BMM是一个演化循环框架,主要包含以下几个阶段:1) SIP推导:计算基础模型和专家模型之间的层级任务向量差异,得到结构重要性先验SIP。2) 贝叶斯优化:使用SIP作为先验,利用Log-Noisy Expected Hypervolume Improvement ($q$NEHVI)准则,选择下一组要评估的模型候选。3) 模型合并:根据贝叶斯优化器选择的层级配置,将基础模型和专家模型进行合并。4) 评估:评估合并后的模型在目标任务上的性能。5) 循环迭代:重复步骤2-4,直到达到预定的迭代次数或评估预算。
关键创新:论文最重要的技术创新点在于提出了结构重要性先验(SIP)。SIP能够有效地降低层级模型合并的搜索空间维度,使得在有限的评估预算下,也能找到高质量的帕累托最优解。与现有方法相比,SIP-BMM能够更精确地控制模型合并的粒度,并根据任务的特点自适应地调整不同层的重要性。
关键设计:SIP是通过计算基础模型和专家模型在每一层上的任务向量差异来得到的。任务向量反映了每一层对特定任务的贡献程度。SIP的值越高,表示该层对任务性能的影响越大,优化器应该给予更多的关注。在贝叶斯优化过程中,SIP被用作一个先验分布,引导优化器选择那些在重要层上进行调整的模型候选。$q$NEHVI准则用于选择下一组要评估的模型候选,它考虑了模型的能力和效率,以及评估的不确定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SIP-BMM在帕累托前沿的发现能力上优于现有的模型合并方法。具体来说,SIP-BMM能够找到比基线方法更强、更密集的帕累托前沿,这意味着在相同的计算资源下,SIP-BMM能够提供更多的模型选择,并且这些模型的性能也更好。例如,在某个实验中,SIP-BMM在保持模型效率的同时,将性能提升了X%。
🎯 应用场景
该研究成果可应用于大语言模型的定制化部署,例如在资源受限的边缘设备上部署高性能的模型。通过SIP-BMM,可以根据不同的硬件条件和任务需求,快速找到一个能力与效率平衡的优化模型,从而降低部署成本,提高用户体验。此外,该方法还可以用于模型压缩和知识迁移等领域,具有广泛的应用前景。
📄 摘要(原文)
Navigating the capability-efficiency trade-offs in Large Language Models (LLMs) requires constructing a high-quality Pareto set. However, existing merging techniques remain inadequate: coarse-grained, model-level methods yield only a sparse set of suboptimal solutions, while fine-grained, layer-wise optimization suffers from the curse of dimensionality, especially under tight evaluation budgets where each model candidate is costly to assess. We propose Bayesian Model Merging with Structural Importance Prior (SIP-BMM), an evolutionary loop framework driven by Log-Noisy Expected Hypervolume Improvement ($q$NEHVI) that makes layer-wise Pareto set construction tractable by explicitly modeling which layers matter. Specifically, SIP-BMM derives a \textbf{Structural Importance Prior (SIP)} from layer-wise task-vector differences between base and expert models, and uses this prior to Bayesian Optimization toward a low effective dimensional subspace. Intuitively, SIP steers the optimizer to spend most trials on a small set of influential layers while largely ignoring layers that exhibit minimal task-relevant shifts. This importance-aware search preserves layer-wise control while substantially reducing sample complexity. Experiments show that SIP-BMM discovers a stronger and denser Pareto front than competitive baselines, enabling agile model selection under diverse operational constraints. Code is available at: https://github.com/MiLab-HITSZ/2026-SIPBMM.