Closing the Train-Test Gap in World Models for Gradient-Based Planning
作者: Arjun Parthasarathy, Nimit Kalra, Rohun Agrawal, Yann LeCun, Oumayma Bounou, Pavel Izmailov, Micah Goldblum
分类: cs.LG, cs.RO
发布日期: 2025-12-10
💡 一句话要点
提出数据合成方法,弥合World Model中基于梯度规划的训练-测试差距
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: World Model 梯度规划 模型预测控制 数据合成 训练-测试差距
📋 核心要点
- 基于梯度的规划在World Model中具有高效性潜力,但其性能与传统方法存在差距,主要原因是训练和测试阶段目标不一致。
- 论文提出在训练阶段进行数据合成,模拟测试阶段的动作序列估计,从而缩小训练和测试之间的差异,提升泛化能力。
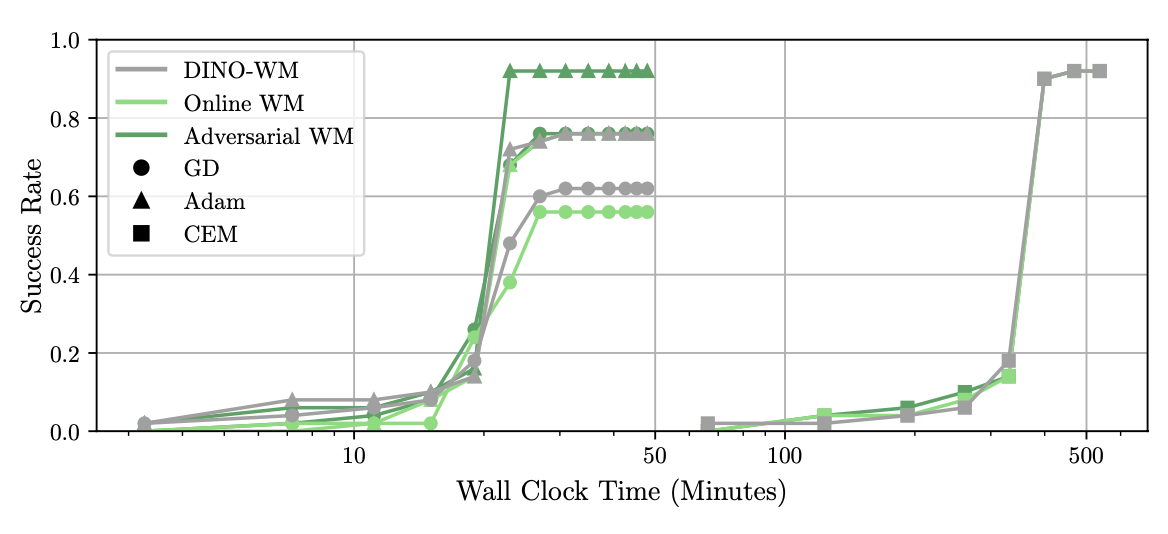
- 实验结果表明,该方法在多种操作和导航任务中,能够在更短的时间内达到或超过传统无梯度方法的性能。
📝 摘要(中文)
本文提出了一种改进的World Model训练方法,旨在提升基于梯度的规划效率。传统的基于World Model的模型预测控制(MPC)依赖离线训练的大规模专家轨迹数据集,以泛化到各种规划任务。与依赖慢速搜索算法或迭代求解优化问题的传统MPC程序相比,基于梯度的规划提供了一种计算高效的替代方案。然而,其性能一直落后于其他方法。本文的核心在于观察到World Model虽然在训练时以预测下一状态为目标,但在测试时却用于估计一系列动作。为了弥合这种训练-测试差距,本文提出了训练时数据合成技术,显著提升了现有World Model的基于梯度的规划性能。在测试时,该方法在10%的时间预算下,性能优于或匹配经典无梯度交叉熵方法(CEM),涵盖了各种物体操作和导航任务。
🔬 方法详解
问题定义:论文旨在解决World Model中基于梯度规划的训练-测试差距问题。现有的World Model虽然在训练时以预测下一状态为目标,但在测试时却用于估计一系列动作,这种不一致导致基于梯度的规划性能不佳。现有方法通常依赖于慢速搜索算法或迭代优化,计算效率较低。
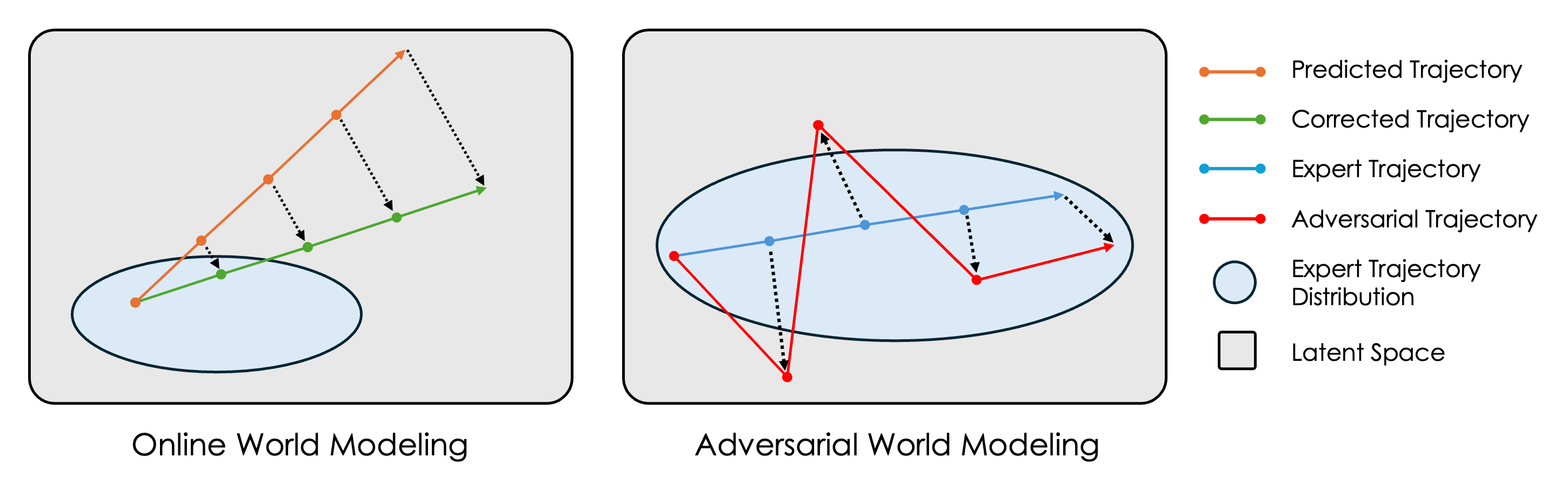
核心思路:论文的核心思路是在训练阶段引入数据合成技术,模拟测试阶段的动作序列估计过程。通过在训练数据中加入合成的动作序列和对应的状态转移,使得World Model能够更好地适应测试阶段的需求,从而提升基于梯度的规划性能。
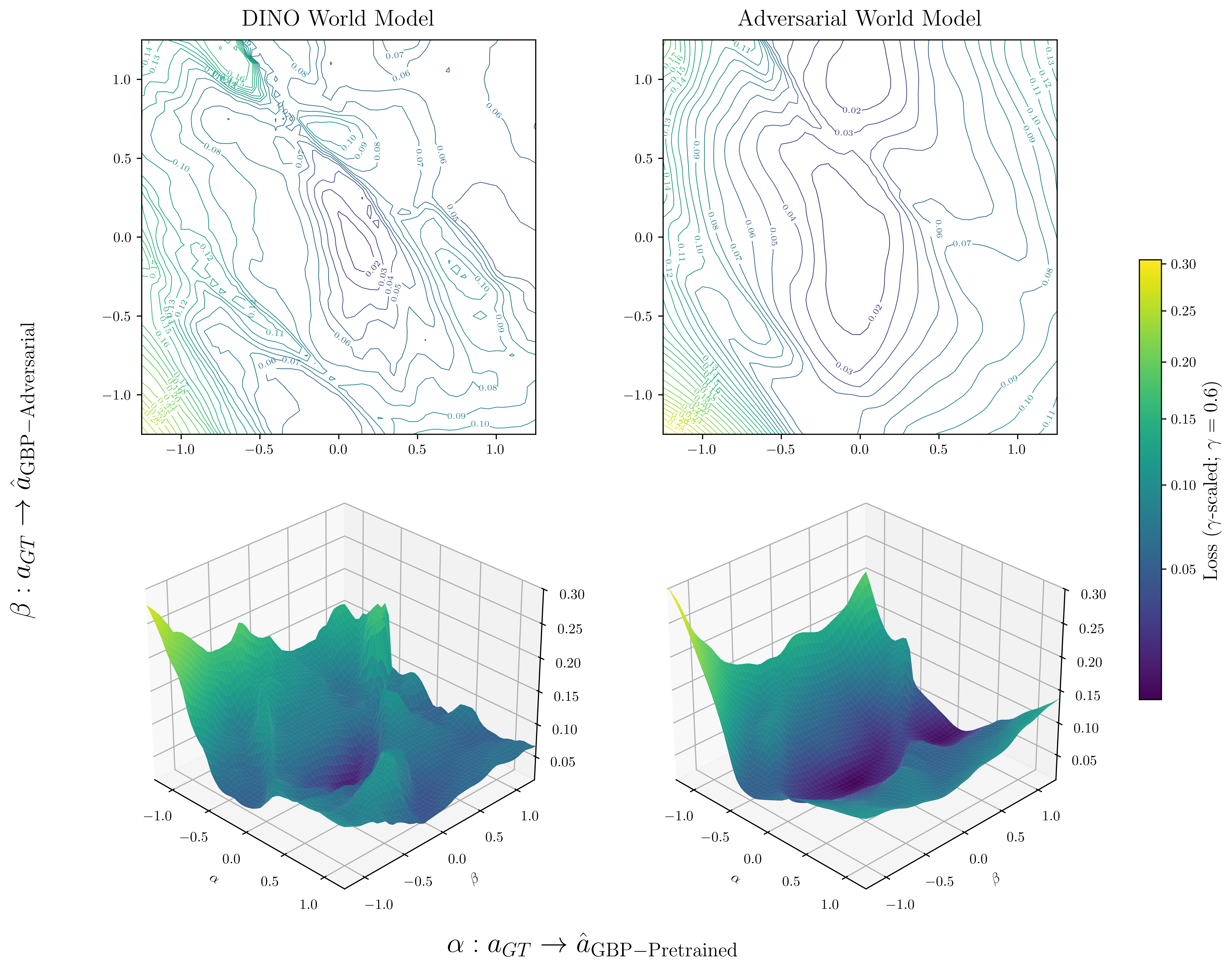
技术框架:整体框架包括World Model的训练和基于梯度的规划两个阶段。在训练阶段,首先使用原始数据训练World Model,然后利用数据合成技术生成新的训练数据。在基于梯度的规划阶段,使用训练好的World Model来预测动作序列的效果,并通过梯度下降优化动作序列。
关键创新:最重要的技术创新点是训练时的数据合成方法,它通过模拟测试阶段的动作序列估计,有效地弥合了训练和测试之间的差距。这种方法不需要修改World Model的结构,而是通过改变训练数据来提升性能。
关键设计:数据合成的关键在于生成具有代表性的动作序列。论文可能采用了随机采样、专家轨迹扰动等方法来生成动作序列,并使用World Model来预测这些动作序列对应的状态转移。损失函数可能包括原始数据的预测损失和合成数据的预测损失,并可能引入正则化项来防止过拟合。具体的网络结构取决于所使用的World Model,可以是循环神经网络(RNN)、Transformer等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多种物体操作和导航任务中,能够在10%的时间预算下,达到或超过经典无梯度交叉熵方法(CEM)的性能。这意味着该方法在保证性能的同时,显著降低了计算成本,提高了规划效率。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过提升World Model的规划能力,可以使机器人在复杂环境中更有效地完成任务,例如物体操作、路径规划等。该方法还可以降低计算成本,提高实时性,从而促进相关技术的实际应用。
📄 摘要(原文)
World models paired with model predictive control (MPC) can be trained offline on large-scale datasets of expert trajectories and enable generalization to a wide range of planning tasks at inference time. Compared to traditional MPC procedures, which rely on slow search algorithms or on iteratively solving optimization problems exactly, gradient-based planning offers a computationally efficient alternative. However, the performance of gradient-based planning has thus far lagged behind that of other approaches. In this paper, we propose improved methods for training world models that enable efficient gradient-based planning. We begin with the observation that although a world model is trained on a next-state prediction objective, it is used at test-time to instead estimate a sequence of actions. The goal of our work is to close this train-test gap. To that end, we propose train-time data synthesis techniques that enable significantly improved gradient-based planning with existing world models. At test time, our approach outperforms or matches the classical gradient-free cross-entropy method (CEM) across a variety of object manipulation and navigation tasks in 10% of the time budget.