Revisiting the Scaling Properties of Downstream Metrics in Large Language Model Training
作者: Jakub Krajewski, Amitis Shidani, Dan Busbridge, Sam Wiseman, Jason Ramapuram
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-09
💡 一句话要点
提出直接建模框架,提升大语言模型下游任务性能预测的准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 Scaling Law 下游任务 性能预测 训练预算
📋 核心要点
- 现有大语言模型下游任务性能预测依赖预训练损失等代理指标,准确性不高,且两阶段预测方法易累积误差。
- 论文提出直接建模训练预算与下游任务性能scaling关系的方法,使用幂律拟合log accuracy,简化预测流程。
- 实验表明,该方法在外推性上优于两阶段方法,并能预测不同token-to-parameter比例下的accuracy。
📝 摘要(中文)
本文挑战了传统观点,即预测大语言模型(LLM)下游任务性能不可靠,传统方法通常侧重于预训练损失等代理指标。本文提出了一种直接框架,用于建模基准性能与训练预算之间的scaling关系。研究发现,对于固定的token-to-parameter比例,简单的幂律可以准确描述多个流行下游任务的log accuracy的scaling行为。结果表明,直接方法比先前提出的两阶段程序具有更好的外推性,后者容易累积误差。此外,本文引入了函数形式,可以预测不同token-to-parameter比例下的accuracy,并考虑重复采样下的推理计算。本文在参数高达17B、训练数据高达350B tokens的模型上验证了研究结果,使用了两种数据集混合。为了支持可重复性并鼓励未来研究,本文发布了完整的预训练损失和下游评估结果。
🔬 方法详解
问题定义:现有的大语言模型scaling law研究主要关注预训练损失等代理指标,而下游任务的性能预测一直被认为不可靠。传统的两阶段预测方法,即先预测预训练损失,再根据预训练损失预测下游任务性能,容易累积误差,导致最终预测结果不准确。因此,如何更准确地预测大语言模型在下游任务上的性能,是本文要解决的核心问题。
核心思路:本文的核心思路是直接建模训练预算(例如训练tokens的数量)与下游任务性能之间的scaling关系,避免使用预训练损失作为中间代理。通过假设下游任务的log accuracy与训练预算之间存在简单的幂律关系,可以直接拟合数据,从而预测模型在不同训练规模下的性能。这种方法简化了预测流程,减少了误差累积的可能性。
技术框架:本文提出的框架主要包含以下几个步骤:1) 选择一组下游任务作为评估基准;2) 在不同的训练预算下训练一系列大语言模型;3) 记录每个模型在下游任务上的性能(例如accuracy);4) 使用幂律函数拟合训练预算与下游任务性能之间的关系;5) 使用拟合的幂律函数预测更大规模模型在下游任务上的性能。
关键创新:本文最重要的技术创新点在于提出了直接建模训练预算与下游任务性能之间scaling关系的方法,避免了使用预训练损失作为中间代理,从而减少了误差累积的可能性。此外,本文还引入了函数形式,可以预测不同token-to-parameter比例下的accuracy,并考虑了重复采样下的推理计算。
关键设计:本文的关键设计包括:1) 使用幂律函数(power law)来建模训练预算与下游任务性能之间的关系,公式为 log(accuracy) = a * log(budget) + b,其中 a 和 b 是可学习的参数;2) 针对不同的token-to-parameter比例,引入了额外的函数形式来预测accuracy;3) 考虑了重复采样下的推理计算,并将其纳入到预测模型中。
🖼️ 关键图片
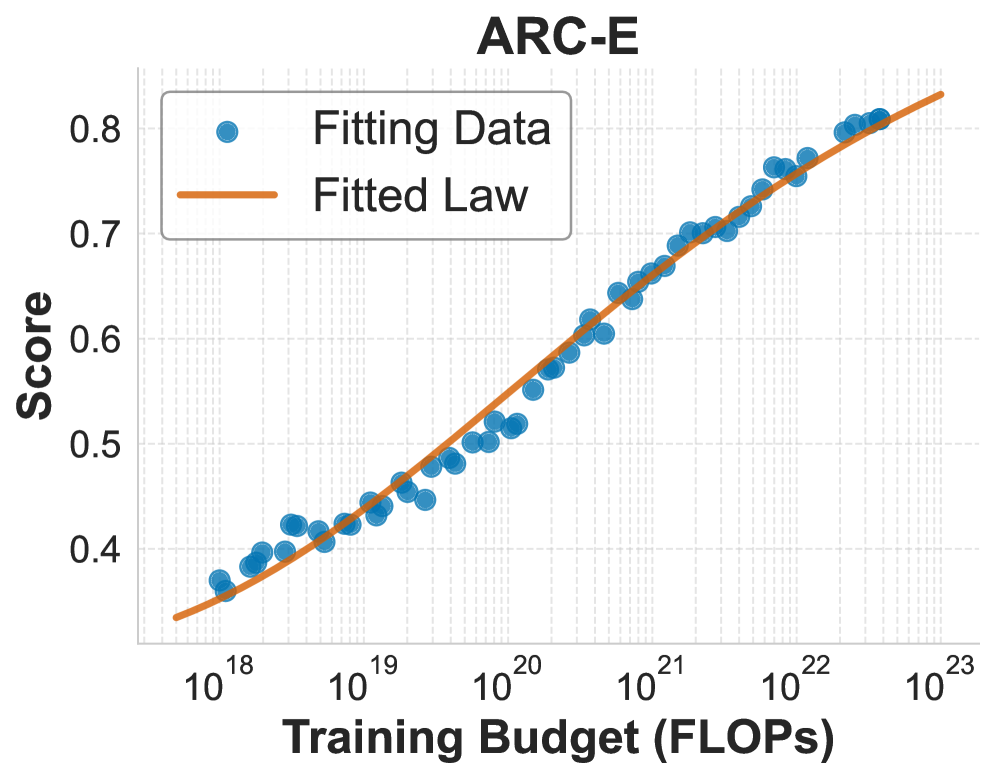
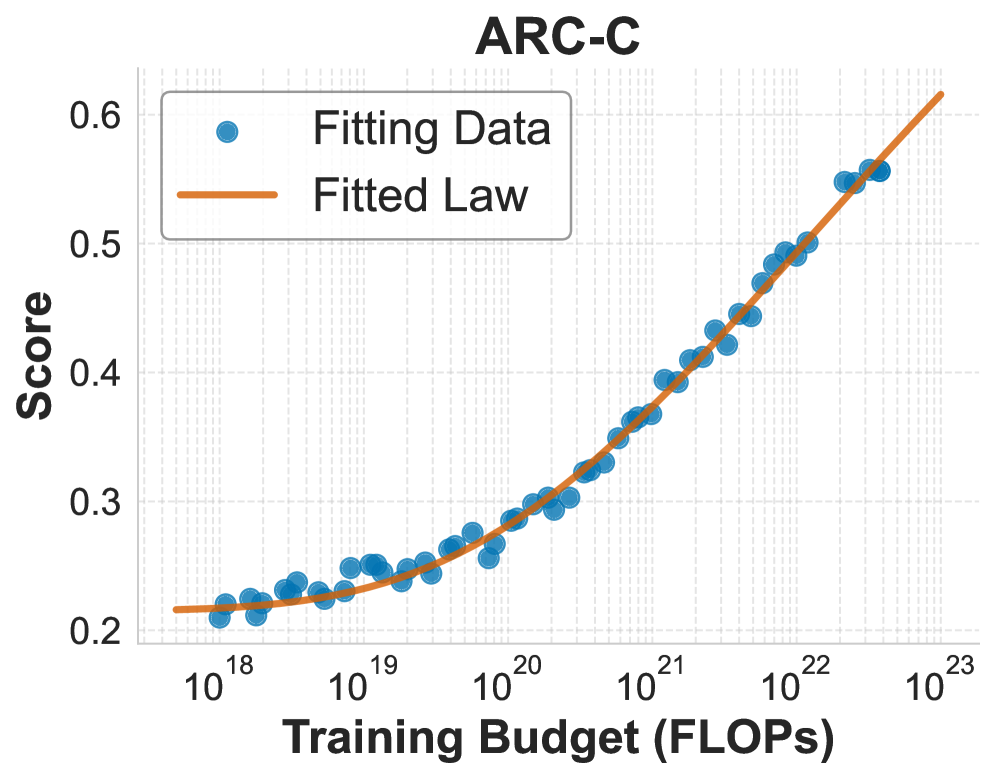
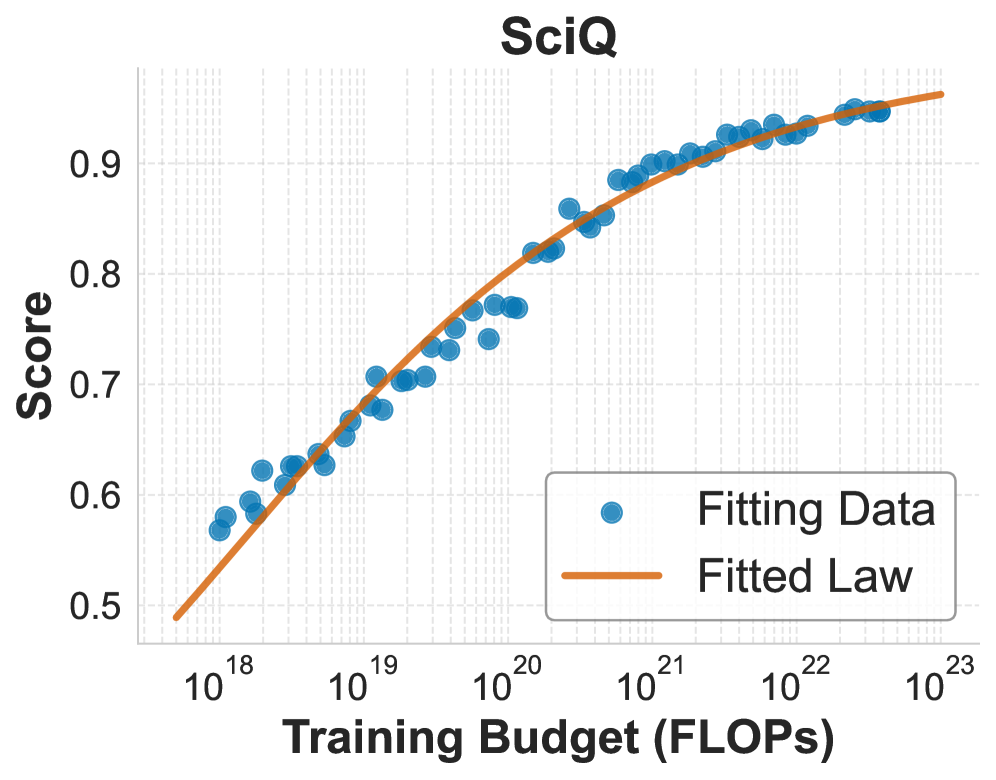
📊 实验亮点
实验结果表明,本文提出的直接建模方法在预测下游任务性能方面优于传统的两阶段方法。具体来说,该方法在多个下游任务上都取得了更高的预测准确率,并且在外推性方面表现更好。此外,本文还验证了该方法在参数高达17B、训练数据高达350B tokens的模型上的有效性。
🎯 应用场景
该研究成果可应用于大语言模型的训练和部署优化。通过准确预测模型在不同训练规模下的下游任务性能,可以帮助研究人员和工程师更有效地分配计算资源,选择合适的模型规模,并优化训练策略。此外,该方法还可以用于评估不同模型架构的潜力,指导模型设计。
📄 摘要(原文)
While scaling laws for Large Language Models (LLMs) traditionally focus on proxy metrics like pretraining loss, predicting downstream task performance has been considered unreliable. This paper challenges that view by proposing a direct framework to model the scaling of benchmark performance from the training budget. We find that for a fixed token-to-parameter ratio, a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks. Our results show that the direct approach extrapolates better than the previously proposed two-stage procedure, which is prone to compounding errors. Furthermore, we introduce functional forms that predict accuracy across token-to-parameter ratios and account for inference compute under repeated sampling. We validate our findings on models with up to 17B parameters trained on up to 350B tokens across two dataset mixtures. To support reproducibility and encourage future research, we release the complete set of pretraining losses and downstream evaluation results.