Balanced Accuracy: The Right Metric for Evaluating LLM Judges -- Explained through Youden's J statistic
作者: Stephane Collot, Colin Fraser, Justin Zhao, William F. Shen, Timon Willi, Ilias Leontiadis
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-08 (更新: 2026-01-19)
备注: 10 pages, 5 figures
💡 一句话要点
提出使用Balanced Accuracy评估LLM Judge,解决传统指标对类别不平衡的敏感性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 Balanced Accuracy 类别不平衡 Youden's J统计量 LLM Judge
📋 核心要点
- 现有评估LLM Judge的指标(如准确率、精确率)易受类别不平衡影响,导致评估结果偏差。
- 论文提出使用Balanced Accuracy作为评估LLM Judge的指标,该指标与Youden's J统计量等价,能更准确反映Judge的性能。
- 通过理论分析、实验和模拟,证明了使用Balanced Accuracy选择Judge能获得更可靠、更稳健的评估结果。
📝 摘要(中文)
对大型语言模型(LLM)进行严格评估依赖于比较模型在期望行为或不良行为(例如任务通过率或违反策略)方面的普遍程度。这些普遍性估计由分类器(LLM Judge或人工标注者)产生,因此分类器的选择对于可信的评估至关重要。常用的评估指标,如准确率(Accuracy)、精确率(Precision)和F1值,对类别不平衡和正类的任意选择很敏感,并且可能偏向于扭曲普遍性估计的Judge。本文表明,Youden's J统计量在理论上与选择最佳Judge来比较模型是一致的,并且Balanced Accuracy是J的等价线性变换。通过分析论证、经验示例和模拟,本文证明了使用Balanced Accuracy选择Judge可以带来更好、更稳健的分类器选择。
🔬 方法详解
问题定义:论文旨在解决使用传统指标(如准确率、精确率和F1值)评估LLM Judge时,由于类别不平衡问题导致的评估偏差。现有方法对正负类的定义敏感,并且容易选择出扭曲真实数据分布的Judge,从而影响LLM的公平和准确评估。
核心思路:论文的核心思路是利用Balanced Accuracy(或等价的Youden's J统计量)作为评估LLM Judge的标准。Balanced Accuracy通过分别计算正类和负类的召回率,然后取平均值,从而减轻类别不平衡的影响。这种方法能够更准确地反映Judge在不同类别上的表现,避免选择出在多数类上表现好但在少数类上表现差的Judge。
技术框架:论文没有提出新的技术框架,而是对现有的评估流程进行了改进。其核心在于将Balanced Accuracy引入到LLM Judge的选择过程中。具体流程如下:1)使用不同的LLM Judge对LLM的输出进行分类;2)计算每个LLM Judge的Balanced Accuracy;3)选择Balanced Accuracy最高的LLM Judge作为最终的评估者。
关键创新:论文的关键创新在于将Balanced Accuracy这一在医学诊断等领域广泛应用的指标引入到LLM Judge的评估中。与传统的准确率等指标相比,Balanced Accuracy对类别不平衡具有更强的鲁棒性,能够更准确地反映LLM Judge的真实性能。此外,论文还从理论上证明了Balanced Accuracy与Youden's J统计量的等价性,为使用Balanced Accuracy评估LLM Judge提供了理论支撑。
关键设计:论文的关键设计在于选择Balanced Accuracy作为评估指标。Balanced Accuracy的计算公式为:Balanced Accuracy = (Sensitivity + Specificity) / 2,其中Sensitivity是正类的召回率,Specificity是负类的召回率。这种设计保证了即使在类别极度不平衡的情况下,Balanced Accuracy也能提供一个相对公平的评估结果。
🖼️ 关键图片
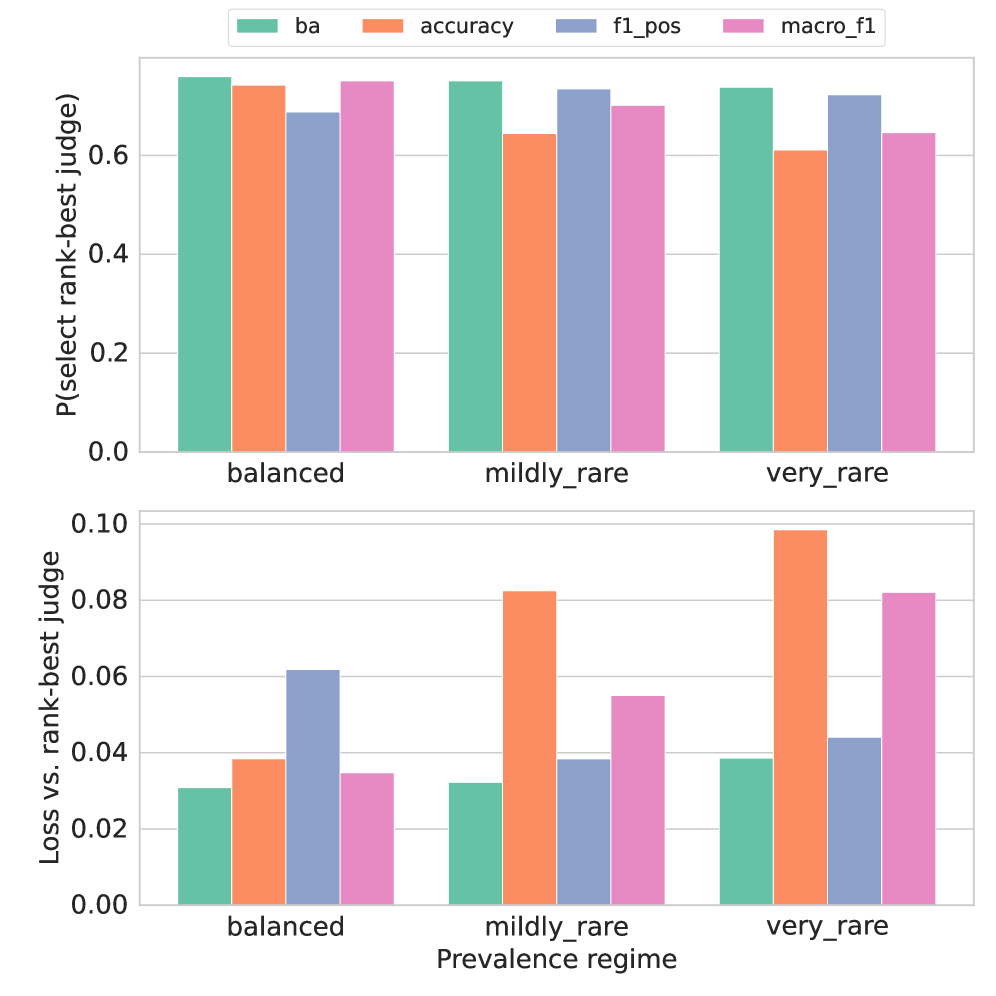
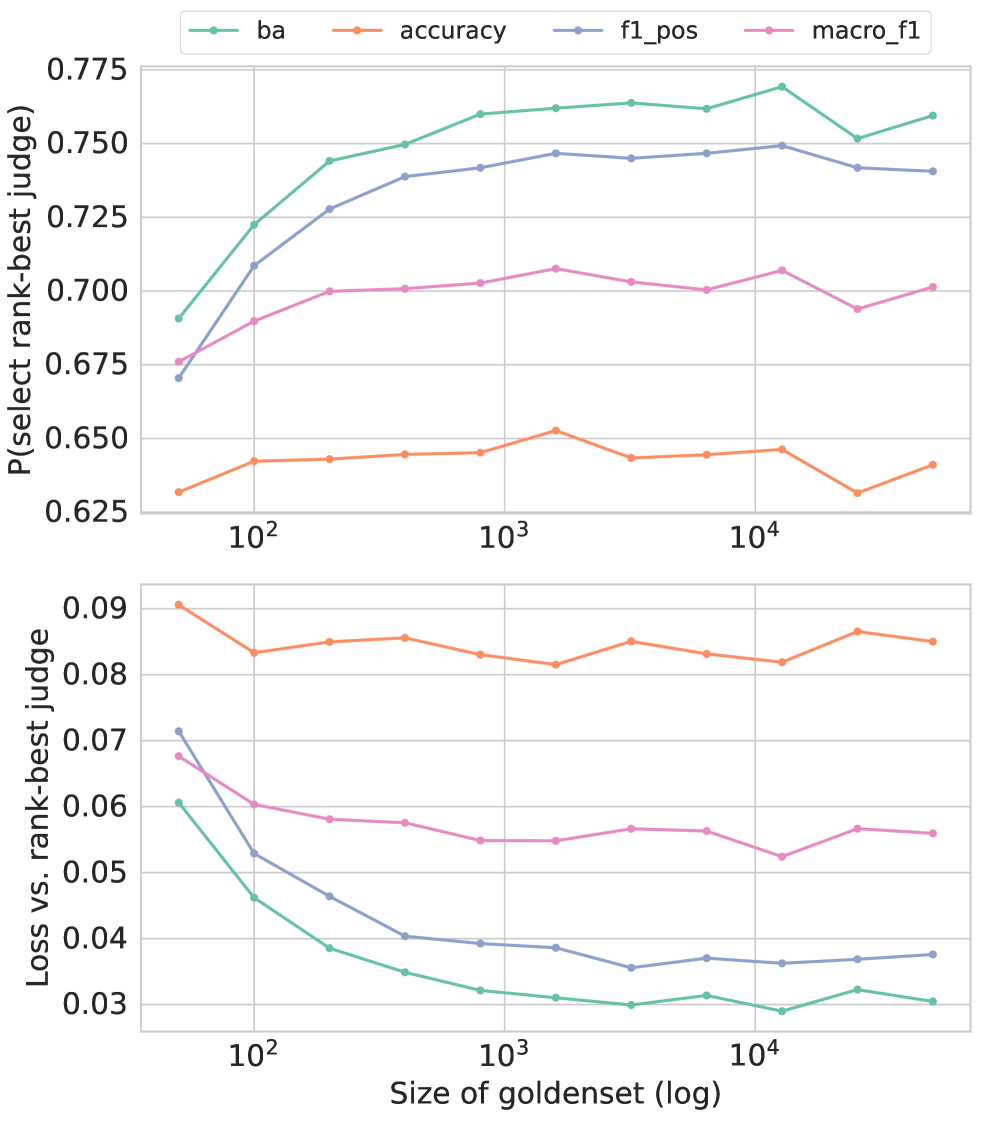
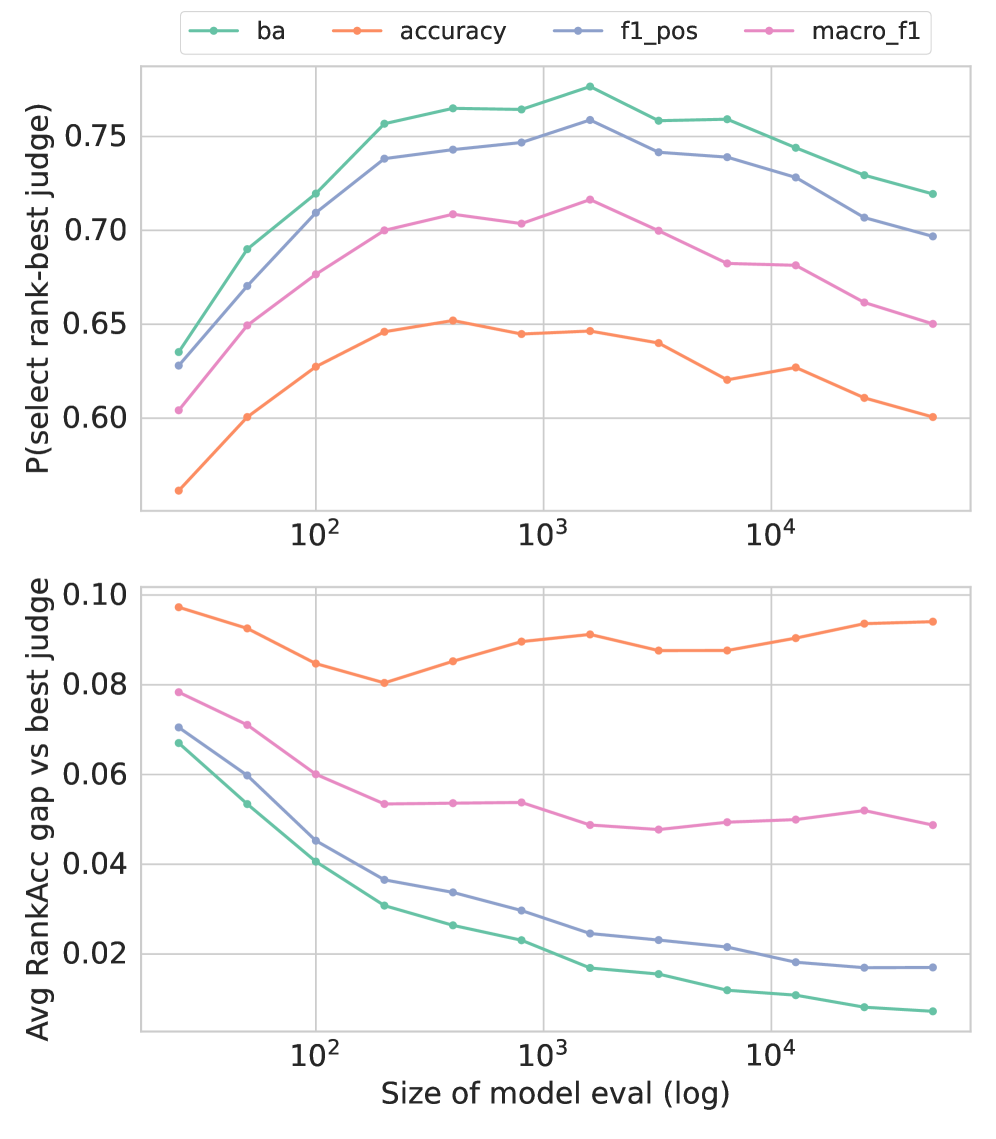
📊 实验亮点
论文通过理论分析、经验示例和模拟实验,证明了使用Balanced Accuracy选择LLM Judge能够获得更稳健的评估结果。具体来说,使用Balanced Accuracy选择的Judge能够更准确地反映LLM在不同类别上的表现,避免了传统指标对类别不平衡的敏感性问题。实验结果表明,使用Balanced Accuracy可以显著提高LLM评估的准确性和可靠性。
🎯 应用场景
该研究成果可应用于各种需要评估LLM输出质量的场景,例如LLM的安全性评估、任务完成度评估、以及生成内容的质量评估。通过使用Balanced Accuracy选择更可靠的LLM Judge,可以提高LLM评估的准确性和公平性,从而促进LLM技术的健康发展。
📄 摘要(原文)
Rigorous evaluation of large language models (LLMs) relies on comparing models by the prevalence of desirable or undesirable behaviors, such as task pass rates or policy violations. These prevalence estimates are produced by a classifier, either an LLM-as-a-judge or human annotators, making the choice of classifier central to trustworthy evaluation. Common metrics used for this choice, such as Accuracy, Precision, and F1, are sensitive to class imbalance and to arbitrary choices of positive class, and can favor judges that distort prevalence estimates. We show that Youden's $J$ statistic is theoretically aligned with choosing the best judge to compare models, and that Balanced Accuracy is an equivalent linear transformation of $J$. Through both analytical arguments and empirical examples and simulations, we demonstrate how selecting judges using Balanced Accuracy leads to better, more robust classifier selection.