FOAM: Blocked State Folding for Memory-Efficient LLM Training
作者: Ziqing Wen, Jiahuan Wang, Ping Luo, Dongsheng Li, Tao Sun
分类: cs.LG, cs.AI
发布日期: 2025-12-08
💡 一句话要点
FOAM:面向内存高效LLM训练的块状状态折叠优化器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 内存优化 优化器 梯度压缩 残差校正
📋 核心要点
- 现有LLM训练方法在内存效率方面存在挑战,如Adam等优化器带来显著内存瓶颈。
- FOAM通过块状梯度均值压缩优化器状态,并使用残差校正恢复信息,提升内存效率。
- 实验表明,FOAM显著降低内存占用,加速收敛,并与其他优化器兼容,性能优越。
📝 摘要(中文)
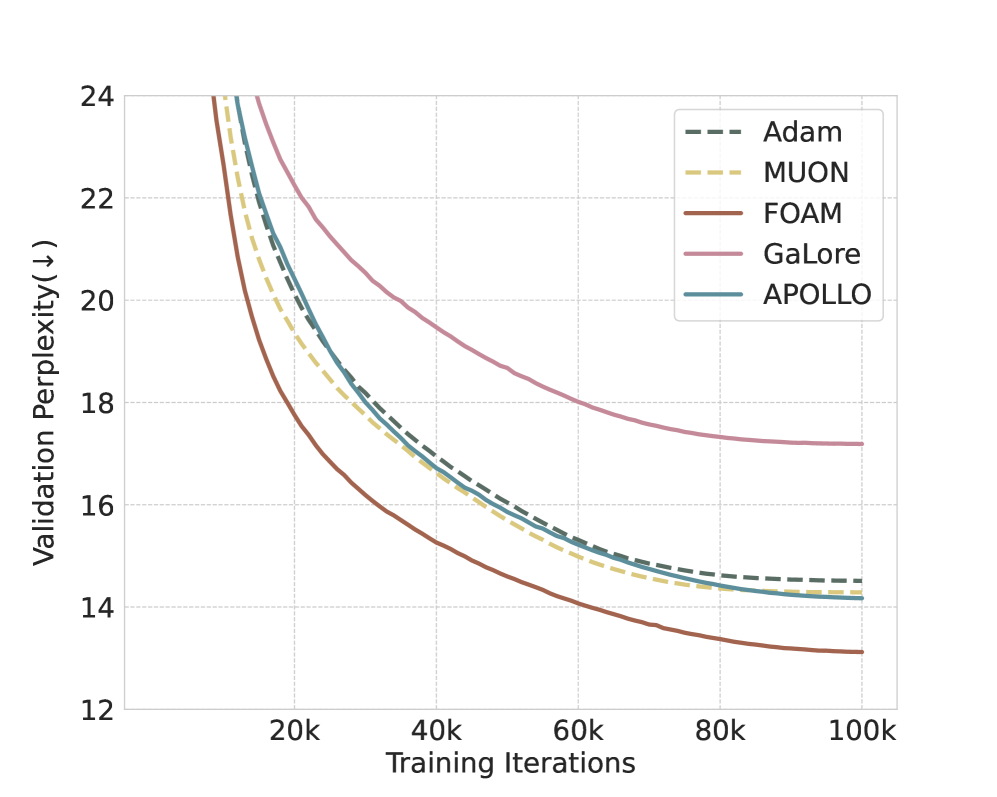
大型语言模型(LLM)因其庞大的参数量和广泛的训练数据而表现出卓越的性能。然而,它们的规模导致训练期间出现严重的内存瓶颈,尤其是在使用像Adam这样内存密集型优化器时。现有的内存高效方法通常依赖于奇异值分解(SVD)、投影或权重冻结等技术,这些技术会引入大量的计算开销,需要额外的内存进行投影,或者降低模型性能。在本文中,我们提出了一种名为Folded Optimizer with Approximate Moment(FOAM)的方法,该方法通过计算块状梯度均值来压缩优化器状态,并结合残差校正来恢复丢失的信息。理论上,FOAM在标准非凸优化设置下实现了与原始Adam相当的收敛速度。实验表明,FOAM将总训练内存减少了约50%,消除了高达90%的优化器状态内存开销,并加速了收敛。此外,FOAM与其他内存高效优化器兼容,提供的性能和吞吐量与全秩和现有的内存高效基线相匹配或超过。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练过程中,由于优化器状态(如Adam的动量和方差)占用大量内存而导致的内存瓶颈问题。现有的内存优化方法,如SVD、投影或权重冻结,要么引入额外的计算开销,要么需要额外的内存,甚至可能降低模型性能。
核心思路:FOAM的核心思路是通过对梯度进行分块处理,计算每个块的梯度均值,以此来压缩优化器状态。同时,为了弥补因压缩而损失的信息,引入残差校正机制,以提升收敛性能。这种方法旨在在不显著增加计算负担或降低模型性能的前提下,大幅减少优化器状态的内存占用。
技术框架:FOAM的整体框架包括以下几个主要步骤:1) 将梯度划分为多个块;2) 计算每个块的梯度均值,作为压缩后的梯度表示;3) 使用压缩后的梯度更新优化器状态;4) 计算残差校正项,用于补偿压缩带来的信息损失;5) 将残差校正项添加到更新后的优化器状态中。
关键创新:FOAM的关键创新在于其块状梯度均值压缩和残差校正机制的结合。与传统的降维方法(如SVD)相比,FOAM的计算复杂度更低,且不需要额外的投影内存。残差校正机制能够有效地恢复因压缩而损失的信息,从而保证了模型的收敛性能。
关键设计:FOAM的关键设计包括块的大小选择和残差校正项的计算方法。块的大小决定了压缩率和信息损失之间的平衡。残差校正项的设计需要保证能够有效地补偿信息损失,同时避免引入过多的计算开销。论文中可能探讨了不同的块大小和残差校正项计算方法,并给出了相应的实验结果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FOAM能够将总训练内存减少约50%,并消除高达90%的优化器状态内存开销。在收敛速度方面,FOAM与原始Adam相当,甚至在某些情况下表现更好。此外,FOAM与其他内存高效优化器兼容,能够进一步提升性能和吞吐量,优于现有的内存高效基线。
🎯 应用场景
FOAM具有广泛的应用前景,尤其适用于训练参数规模巨大的LLM。它可以显著降低训练所需的内存资源,使得在资源受限的硬件上训练大型模型成为可能。此外,FOAM还可以应用于其他需要使用内存密集型优化器的机器学习任务,例如图像识别、语音识别等。该研究的成果有助于推动LLM的普及和应用,加速人工智能领域的发展。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance due to their large parameter counts and extensive training data. However, their scale leads to significant memory bottlenecks during training, especially when using memory-intensive optimizers like Adam. Existing memory-efficient approaches often rely on techniques such as singular value decomposition (SVD), projections, or weight freezing, which can introduce substantial computational overhead, require additional memory for projections, or degrade model performance. In this paper, we propose Folded Optimizer with Approximate Moment (FOAM), a method that compresses optimizer states by computing block-wise gradient means and incorporates a residual correction to recover lost information. Theoretically, FOAM achieves convergence rates equivalent to vanilla Adam under standard non-convex optimization settings. Empirically, FOAM reduces total training memory by approximately 50\%, eliminates up to 90\% of optimizer state memory overhead, and accelerates convergence. Furthermore, FOAM is compatible with other memory-efficient optimizers, delivering performance and throughput that match or surpass both full-rank and existing memory-efficient baselines.