Dual Refinement Cycle Learning: Unsupervised Text Classification of Mamba and Community Detection on Text Attributed Graph
作者: Hong Wang, Yinglong Zhang, Hanhan Guo, Xuewen Xia, Xing Xu
分类: cs.LG
发布日期: 2025-12-08 (更新: 2025-12-10)
🔗 代码/项目: GITHUB
💡 一句话要点
提出DRCL:一种无监督文本分类与文本属性图社区检测双重优化框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本分类 社区检测 文本属性图 无监督学习 图神经网络 Mamba 双重优化循环
📋 核心要点
- 现有预训练语言模型依赖大量标注数据,难以在实际文本属性网络中部署。
- DRCL通过GCN和文本语义模块的双向优化循环,在无监督条件下融合结构和语义信息。
- 实验表明,DRCL提升了社区结构和语义质量,且Mamba分类器性能可与监督模型媲美。
📝 摘要(中文)
本文提出了一种双重优化循环学习(DRCL)框架,用于解决现实场景中无标签或无类别定义的文本分类问题。DRCL集成了结构信息和语义信息,通过一个基于GCN的社区检测模块(GCN-CDM)和一个文本语义建模模块(TSMM)之间的warm-start初始化和双向优化循环实现。这两个模块迭代地交换伪标签,使得语义线索能够增强结构聚类,而结构模式能够指导文本表示学习,无需人工监督。在多个文本属性图数据集上,DRCL持续提高了发现的社区的结构和语义质量。此外,仅从DRCL的社区信号训练的基于Mamba的分类器实现了与监督模型相当的准确率,展示了其在标签数据稀缺或昂贵的大规模系统中的部署潜力。
🔬 方法详解
问题定义:现有方法在处理文本属性图时存在局限性。预训练语言模型虽然语义理解能力强,但依赖大量标注数据,难以应用于实际场景。传统的社区检测方法则忽略了文本语义信息,限制了其在内容组织、推荐和风险监控等下游应用中的效果。因此,如何在无监督条件下,有效利用文本属性图中的结构和语义信息,是一个亟待解决的问题。
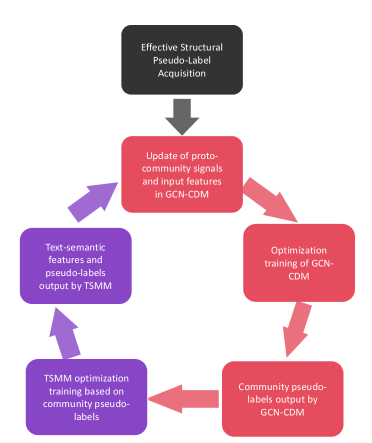
核心思路:DRCL的核心思路是通过一个双向优化循环,迭代地提升社区检测和文本语义建模的质量。GCN-CDM利用图结构信息进行社区检测,TSMM则利用文本信息进行语义建模。两个模块通过交换伪标签,相互指导,从而在无监督条件下实现结构和语义信息的有效融合。
技术框架:DRCL框架包含两个主要模块:GCN-CDM和TSMM。首先,通过warm-start初始化两个模块。然后,GCN-CDM利用图结构信息生成伪标签,并将其传递给TSMM,用于指导文本表示学习。TSMM利用学习到的文本表示,反过来生成伪标签,并将其传递给GCN-CDM,用于优化社区检测结果。这个过程迭代进行,直到两个模块的性能收敛。
关键创新:DRCL的关键创新在于提出了一个双向优化循环,将结构信息和语义信息有机地结合起来。与传统的单向方法相比,DRCL能够更有效地利用文本属性图中的信息,从而提高社区检测和文本分类的性能。此外,使用Mamba作为文本分类器,探索了新型序列模型的潜力。
关键设计:GCN-CDM采用标准的GCN结构,用于学习节点的表示。TSMM可以使用不同的文本建模方法,论文中采用了Mamba。损失函数的设计目标是使GCN-CDM生成的社区结构与TSMM学习到的文本表示尽可能一致。具体而言,可以使用交叉熵损失函数来衡量伪标签的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DRCL在多个文本属性图数据集上显著提高了社区检测的结构和语义质量。例如,在某些数据集上,DRCL的NMI指标提升了超过10%。此外,仅使用DRCL生成的伪标签训练的Mamba分类器,其准确率与使用人工标注数据训练的监督模型相当,证明了DRCL的有效性和实用性。
🎯 应用场景
DRCL适用于各种需要处理文本属性图的场景,例如社交网络分析、内容推荐、风险监控和知识图谱构建。该方法无需人工标注数据,降低了应用成本,使其能够部署在数据量大、标注困难的实际系统中。未来,DRCL可以进一步扩展到处理更复杂的图结构和文本类型,并与其他机器学习技术相结合,以实现更强大的功能。
📄 摘要(原文)
Pretrained language models offer strong text understanding capabilities but remain difficult to deploy in real-world text-attributed networks due to their heavy dependence on labeled data. Meanwhile, community detection methods typically ignore textual semantics, limiting their usefulness in downstream applications such as content organization, recommendation, and risk monitoring. To overcome these limitations, we present Dual Refinement Cycle Learning (DRCL), a fully unsupervised framework designed for practical scenarios where no labels or category definitions are available. DRCL integrates structural and semantic information through a warm-start initialization and a bidirectional refinement cycle between a GCN-based Community Detection Module (GCN-CDM) and a Text Semantic Modeling Module (TSMM). The two modules iteratively exchange pseudo-labels, allowing semantic cues to enhance structural clustering and structural patterns to guide text representation learning without manual supervision. Across several text-attributed graph datasets, DRCL consistently improves the structural and semantic quality of discovered communities. Moreover, a Mamba-based classifier trained solely from DRCL's community signals achieves accuracy comparable to supervised models, demonstrating its potential for deployment in large-scale systems where labeled data are scarce or costly. The code is available at https://github.com/wuanghoong/DRCL.git.