The Geometry of Persona: Disentangling Personality from Reasoning in Large Language Models
作者: Zhixiang Wang
分类: cs.LG, cs.AI
发布日期: 2025-12-08
备注: 10 pages, 3 figures, 1 table. Code and dataset available at https://huggingface.co/Zx93/Soul-Engine-Qwen2.5-0.5B
💡 一句话要点
提出Soul Engine框架,通过解耦人格与推理能力实现安全可控的LLM个性化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 人格解耦 线性表示 零样本学习
📋 核心要点
- 现有LLM个性化方法依赖微调,导致推理能力下降,面临稳定-可塑性困境。
- Soul Engine框架基于线性表示假设,通过解耦人格向量实现个性化,无需微调。
- 实验证明该方法能高精度刻画人格,保持模型推理能力,并实现确定性行为控制。
📝 摘要(中文)
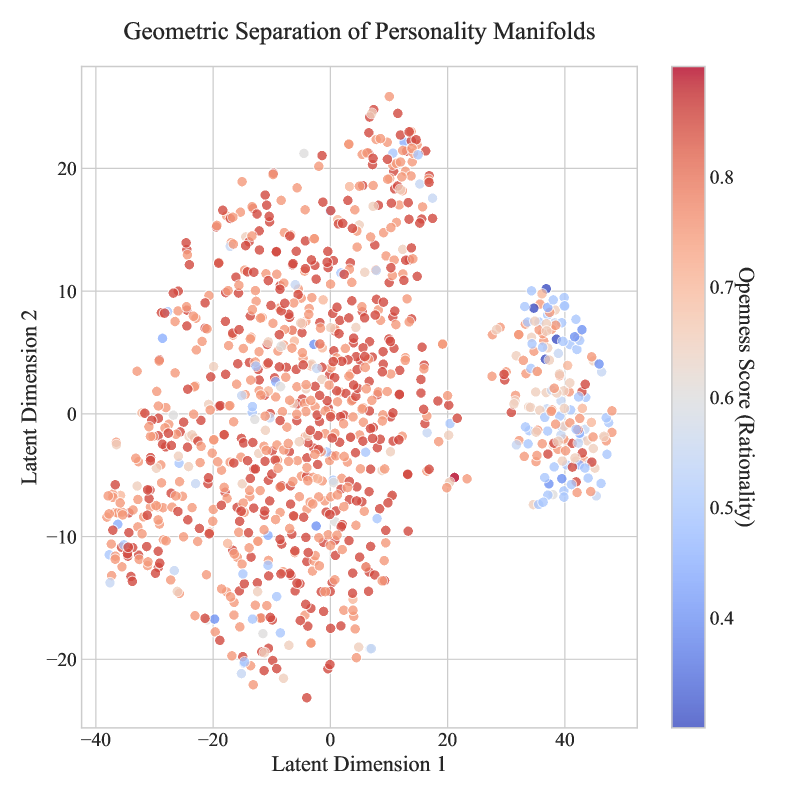
当前个性化大型语言模型(LLM)的部署受到稳定-可塑性困境的限制。主流的对齐方法,如监督微调(SFT),依赖于随机权重更新,这通常会导致“对齐税”——降低通用推理能力。本文提出了Soul Engine,一个基于线性表示假设的框架,该假设认为人格特质以正交线性子空间的形式存在。我们引入了SoulBench,一个通过动态上下文采样构建的数据集。使用冻结的Qwen-2.5基座上的双头架构,我们在不修改骨干权重的情况下提取了解耦的人格向量。实验表明三个突破:高精度分析(MSE为0.011);几何正交性(T-SNE可视化证实人格流形是不同的和连续的,允许“零样本人格注入”);确定性引导(通过向量算术实现对行为的鲁棒控制)。这项工作挑战了微调对于个性化的必要性,并为安全、可控的AI个性化提供了数学上严谨的基础。
🔬 方法详解
问题定义:现有的大型语言模型个性化方法,例如监督微调(SFT),通常需要修改模型的权重参数。这种方法的缺点在于,它可能会降低模型原有的通用推理能力,即产生所谓的“对齐税”。因此,如何实现既能赋予模型个性化特征,又能保持其原有推理能力,是一个重要的挑战。
核心思路:本文的核心思路是基于“线性表示假设”,即认为人格特质可以表示为模型内部的线性子空间。通过学习和提取这些线性子空间,可以将人格特征与模型的推理能力解耦。这样,在进行个性化时,只需要调整人格相关的线性子空间,而无需修改模型的整体权重,从而避免了“对齐税”的问题。
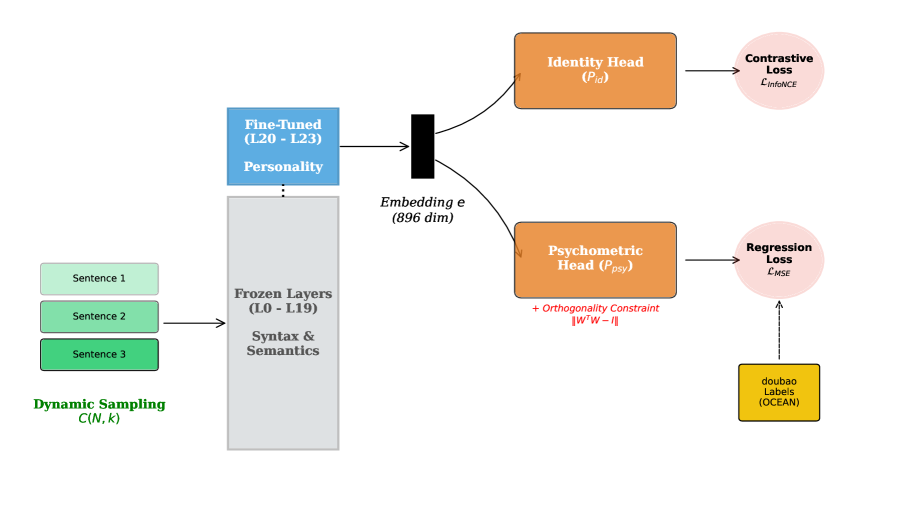
技术框架:Soul Engine框架主要包含以下几个模块:1) 数据集构建:使用动态上下文采样构建SoulBench数据集,用于训练和评估人格化模型。2) 双头架构:在冻结的Qwen-2.5基座上构建双头架构,一个头用于预测人格特征,另一个头用于生成文本。3) 人格向量提取:通过训练双头架构,提取与人格特征相关的线性子空间,得到人格向量。4) 零样本人格注入:通过调整人格向量,实现对模型行为的控制,而无需修改模型本身的权重。
关键创新:该论文最重要的创新点在于提出了基于线性表示假设的Soul Engine框架,实现了人格特征与推理能力的解耦。与传统的微调方法相比,该方法无需修改模型权重,从而避免了“对齐税”的问题。此外,该方法还实现了高精度的人格刻画和确定性的行为控制。
关键设计:在双头架构中,一个头用于预测人格特征,采用均方误差(MSE)作为损失函数,以提高人格刻画的精度。另一个头用于生成文本,采用交叉熵损失函数。通过训练,可以得到与人格特征相关的线性子空间,即人格向量。此外,论文还设计了动态上下文采样方法,以构建更具挑战性的SoulBench数据集。
🖼️ 关键图片
📊 实验亮点
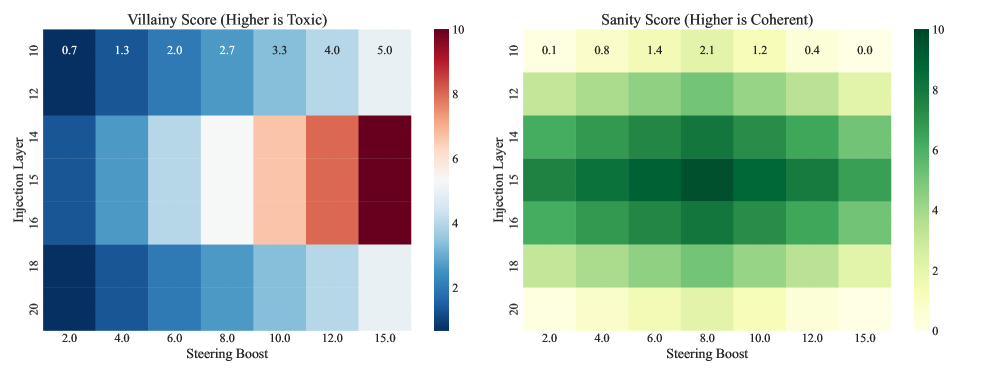
实验结果表明,Soul Engine框架能够实现高精度的人格刻画,MSE达到0.011。通过T-SNE可视化,验证了人格流形的正交性和连续性,实现了零样本人格注入。此外,通过向量算术,实现了对模型行为的鲁棒控制。这些结果表明,该方法在实现安全、可控的AI个性化方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要个性化AI助手的场景,例如:心理咨询、教育辅导、娱乐互动等。通过Soul Engine框架,可以创建具有特定人格特征的AI角色,从而提供更贴近用户需求的个性化服务。此外,该方法还可以用于控制AI的行为,使其更加安全和可控,降低潜在的伦理风险。
📄 摘要(原文)
Background: The deployment of personalized Large Language Models (LLMs) is currently constrained by the stability-plasticity dilemma. Prevailing alignment methods, such as Supervised Fine-Tuning (SFT), rely on stochastic weight updates that often incur an "alignment tax" -- degrading general reasoning capabilities. Methods: We propose the Soul Engine, a framework based on the Linear Representation Hypothesis, which posits that personality traits exist as orthogonal linear subspaces. We introduce SoulBench, a dataset constructed via dynamic contextual sampling. Using a dual-head architecture on a frozen Qwen-2.5 base, we extract disentangled personality vectors without modifying the backbone weights. Results: Our experiments demonstrate three breakthroughs. First, High-Precision Profiling: The model achieves a Mean Squared Error (MSE) of 0.011 against psychological ground truth. Second, Geometric Orthogonality: T-SNE visualization confirms that personality manifolds are distinct and continuous, allowing for "Zero-Shot Personality Injection" that maintains original model intelligence. Third, Deterministic Steering: We achieve robust control over behavior via vector arithmetic, validated through extensive ablation studies. Conclusion: This work challenges the necessity of fine-tuning for personalization. By transitioning from probabilistic prompting to deterministic latent intervention, we provide a mathematically rigorous foundation for safe, controllable AI personalization.