Parent-Guided Semantic Reward Model (PGSRM): Embedding-Based Reward Functions for Reinforcement Learning of Transformer Language Models
作者: Alexandr Plashchinsky
分类: cs.LG
发布日期: 2025-12-07
💡 一句话要点
提出Parent-Guided Semantic Reward Model,用于Transformer语言模型的强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 语言模型 奖励模型 语义相似度 Transformer PPO 嵌入向量
📋 核心要点
- 现有方法依赖二元正确性信号或需要人工标注的奖励模型,成本高昂且奖励信号稀疏。
- PGSRM利用父模型的输出嵌入作为参考,计算子模型输出的语义相似度作为奖励,无需额外训练或人工干预。
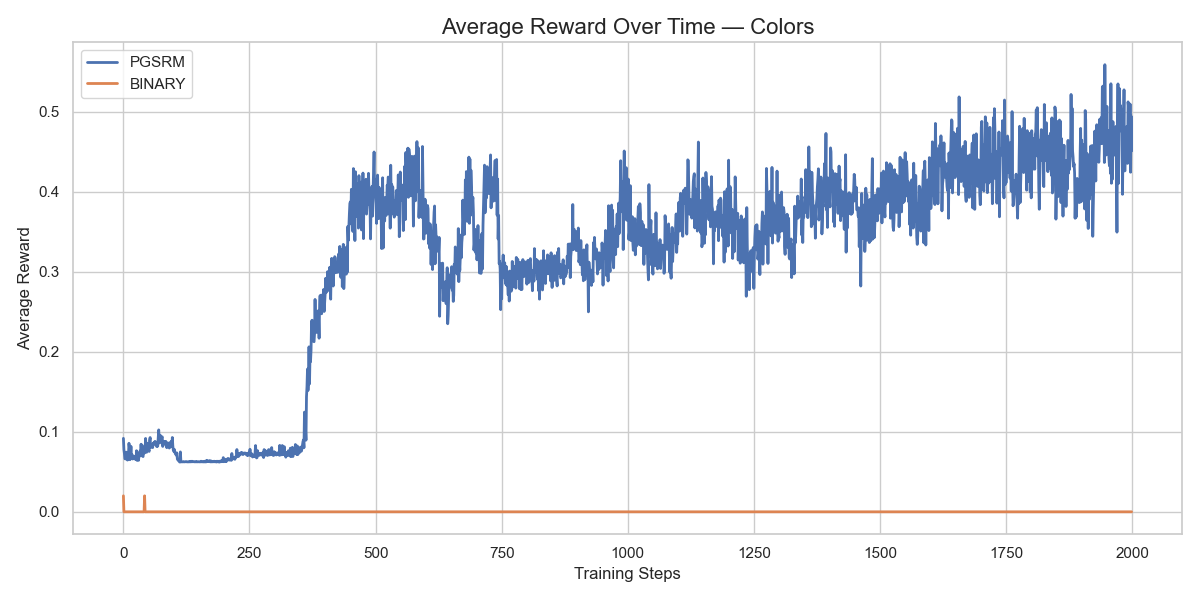
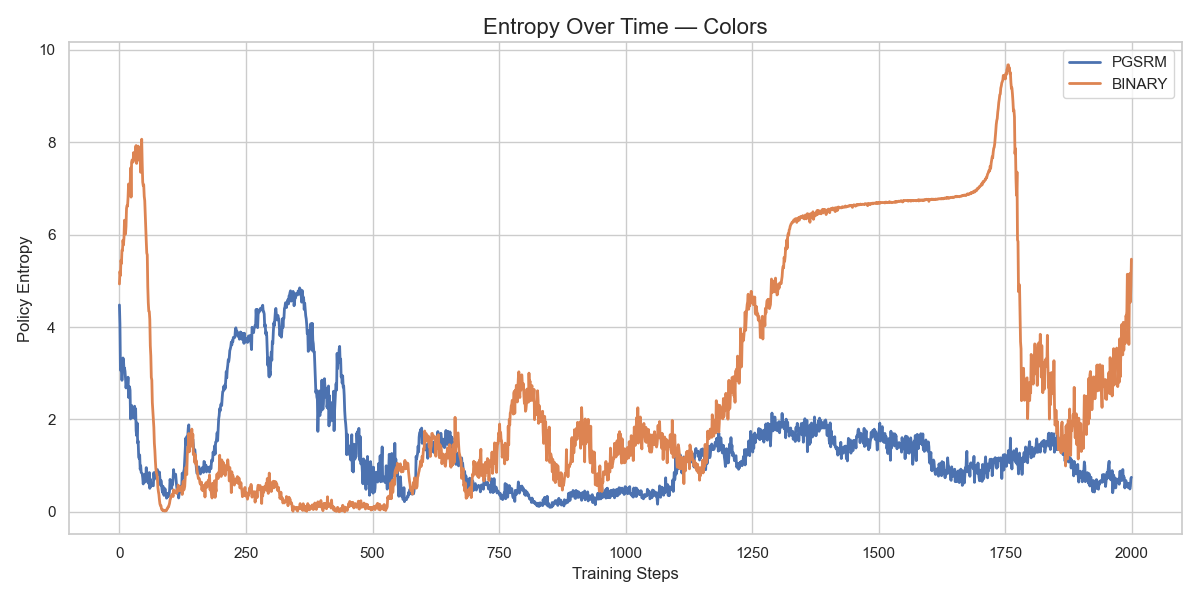
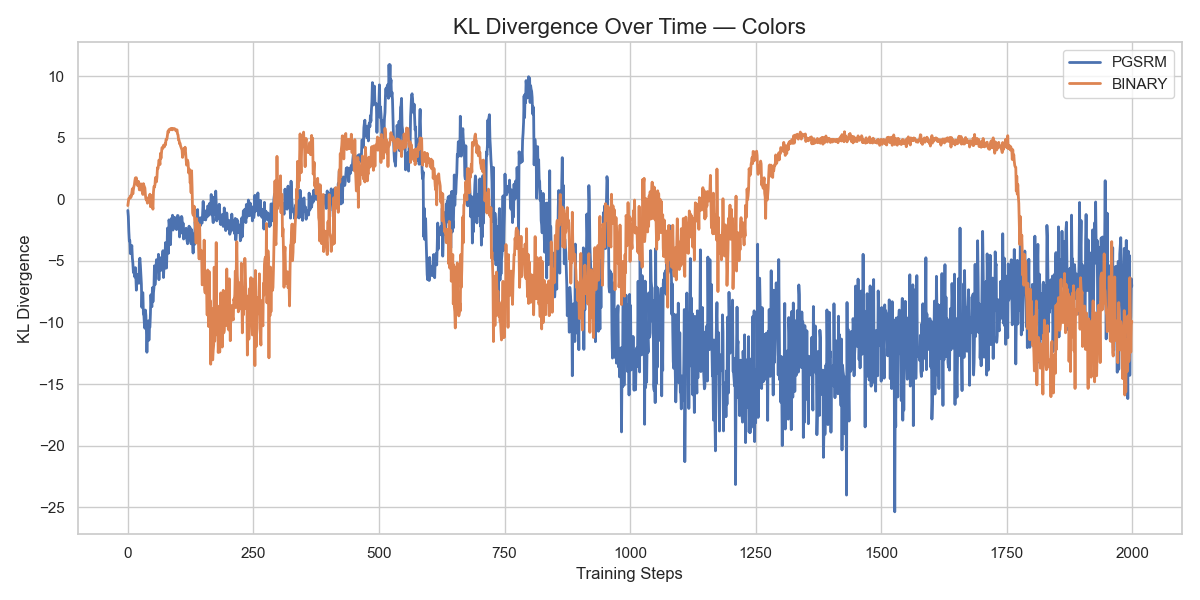
- 实验表明,PGSRM在多个语言任务上实现了更平滑的奖励改进和更稳定的PPO训练动态。
📝 摘要(中文)
本文介绍了一种轻量级的奖励框架Parent-Guided Semantic Reward Model (PGSRM),用于Transformer语言模型的强化学习。PGSRM使用简单的信号取代了二元正确性信号、人类偏好数据和训练后的奖励模型:父模型的参考输出嵌入与子模型为相同输入生成的输出之间的余弦相似度。这产生了一个密集的、语义上有意义的奖励,无需人工标注或额外的模型训练。我们将PGSRM应用于五个语言任务,发现它比二元奖励基线产生更平滑的奖励改进和更稳定的PPO动态,这表明基于嵌入的语义奖励是较小Transformer模型中父引导对齐的RLHF风格奖励建模的实用替代方案。
🔬 方法详解
问题定义:现有的Transformer语言模型强化学习方法,如基于人类反馈的强化学习(RLHF),通常需要大量的人工标注数据来训练奖励模型,或者依赖于稀疏的二元奖励信号。这些方法成本高昂,且奖励信号不足以有效引导模型的训练。
核心思路:PGSRM的核心思路是利用一个预训练的“父模型”的输出作为语义参考。通过计算子模型(即正在训练的模型)的输出与父模型输出的嵌入向量之间的余弦相似度,来生成一个密集的、语义上有意义的奖励信号。这种方法避免了人工标注和额外的奖励模型训练。
技术框架:PGSRM的整体框架非常简洁。首先,有一个预训练的父模型。在强化学习训练过程中,对于给定的输入,父模型生成一个参考输出,子模型也生成一个输出。然后,将这两个输出分别嵌入到向量空间中,计算它们的余弦相似度。这个余弦相似度就是PGSRM提供的奖励信号,用于指导子模型的训练。PGSRM使用PPO算法进行强化学习训练。
关键创新:PGSRM的关键创新在于使用父模型的输出嵌入作为奖励信号,从而避免了人工标注和额外的奖励模型训练。这种方法不仅降低了成本,还提供了更密集的、语义上有意义的奖励信号,有助于更有效地引导模型的训练。与传统的二元奖励相比,语义相似度能够更细粒度地反映模型输出的质量。
关键设计:PGSRM的关键设计在于选择合适的嵌入模型和相似度度量。论文中使用预训练的Transformer语言模型来生成嵌入向量,并使用余弦相似度作为相似度度量。没有涉及特定的损失函数或复杂的网络结构,重点在于奖励信号的设计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PGSRM在五个不同的语言任务上都优于二元奖励基线。PGSRM能够产生更平滑的奖励改进和更稳定的PPO训练动态。具体性能提升数据未知,但论文强调了PGSRM在训练稳定性和奖励信号质量方面的优势。
🎯 应用场景
PGSRM可应用于各种需要对Transformer语言模型进行微调或对齐的任务,例如文本生成、对话系统、代码生成等。它降低了强化学习训练的成本,并提高了训练的稳定性,使得在资源有限的情况下也能有效地提升模型性能。该方法尤其适用于需要快速迭代和实验的场景。
📄 摘要(原文)
We introduce the Parent-Guided Semantic Reward Model (PGSRM), a lightweight reward framework for reinforcement learning (RL) of transformer language models. PGSRM replaces binary correctness signals, human preference data, and trained reward models with a simple signal: cosine similarity between a parent model's reference output embedding and a child model's generated output for the same input. This yields a dense, semantically meaningful reward with no human annotation or additional model training. We apply PGSRM on five language tasks and find that it produces smoother reward improvement and more stable PPO dynamics than a binary reward baseline, suggesting that embedding-based semantic rewards are a practical alternative to RLHF-style reward modeling for parent-guided alignment in smaller transformer models.