Know your Trajectory -- Trustworthy Reinforcement Learning deployment through Importance-Based Trajectory Analysis
作者: Clifford F, Devika Jay, Abhishek Sarkar, Satheesh K Perepu, Santhosh G S, Kaushik Dey, Balaraman Ravindran
分类: cs.LG
发布日期: 2025-12-07
备注: Accepted at 4th Deployable AI Workshop at AAAI 2026
💡 一句话要点
提出基于重要性的轨迹分析方法,提升强化学习部署的可信度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 可解释性 轨迹分析 状态重要性 反事实解释
📋 核心要点
- 现有可解释强化学习方法侧重于单步决策,缺乏对智能体长期行为的解释能力。
- 论文提出基于重要性的轨迹分析框架,通过状态重要性度量对轨迹进行排序,从而识别最优轨迹。
- 实验表明,该方法能有效识别最优行为,并生成反事实解释,提升强化学习部署的可信度。
📝 摘要(中文)
随着强化学习(RL)智能体越来越多地部署在现实世界的应用中,确保其行为的透明性和可信度至关重要。可信度的关键组成部分是可解释性,然而,可解释强化学习(XRL)中的大部分工作都集中在局部的、单步的决策上。本文提出了一种新的框架,通过定义和聚合一种新的状态重要性度量来对整个轨迹进行排序,从而解决了解释智能体长期行为的关键需求。该度量结合了经典的Q值差异和一个“激进项”,该激进项捕捉了智能体达到其目标的倾向,从而提供了对状态重要性的更细致的度量。我们证明了我们的方法成功地从智能体经验的异构集合中识别出最佳轨迹。此外,通过从这些轨迹中的关键状态生成反事实展开,我们表明智能体选择的路径比其他路径更稳健地优越,从而提供了强大的“为什么是这个,而不是那个?”的解释。我们在标准的OpenAI Gym环境中的实验验证了我们提出的重要性度量在识别最佳行为方面比经典方法更有效,为可信的自主系统提供了重要一步。
🔬 方法详解
问题定义:现有可解释强化学习方法主要关注单步决策的解释,忽略了对智能体长期行为(即轨迹)的理解。在实际应用中,用户更关心智能体为什么选择这条轨迹,而不是其他轨迹。因此,需要一种方法来评估轨迹的重要性,并解释智能体选择特定轨迹的原因。现有方法难以有效区分不同轨迹的优劣,也无法提供“为什么选择这条轨迹”的解释。
核心思路:论文的核心思路是通过定义一种新的状态重要性度量,并将其聚合到轨迹层面,从而对轨迹进行排序。该度量不仅考虑了经典的Q值差异,还引入了一个“激进项”,用于捕捉智能体达到目标的倾向。通过这种方式,可以更准确地评估状态和轨迹的重要性,并识别出最优轨迹。此外,通过生成反事实轨迹,可以解释智能体选择特定轨迹的原因,即“为什么是这个,而不是那个”。
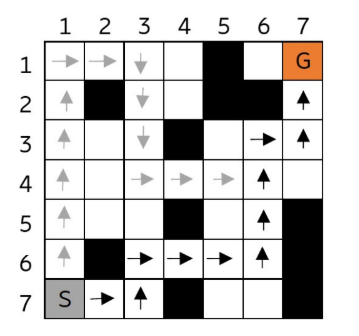
技术框架:该框架主要包含以下几个阶段:1) 智能体与环境交互,收集轨迹数据;2) 计算每个状态的重要性度量,该度量结合了Q值差异和“激进项”;3) 将状态重要性度量聚合到轨迹层面,得到轨迹的重要性得分;4) 根据轨迹的重要性得分对轨迹进行排序,识别最优轨迹;5) 从最优轨迹中的关键状态生成反事实轨迹,用于解释智能体的行为。
关键创新:论文最重要的技术创新点在于提出了新的状态重要性度量,该度量结合了Q值差异和“激进项”。传统的Q值差异只考虑了当前状态下不同动作的价值差异,而忽略了智能体达到目标的倾向。“激进项”的引入弥补了这一不足,使得状态重要性度量更加全面和准确。此外,通过生成反事实轨迹,可以提供更直观和可信的解释。
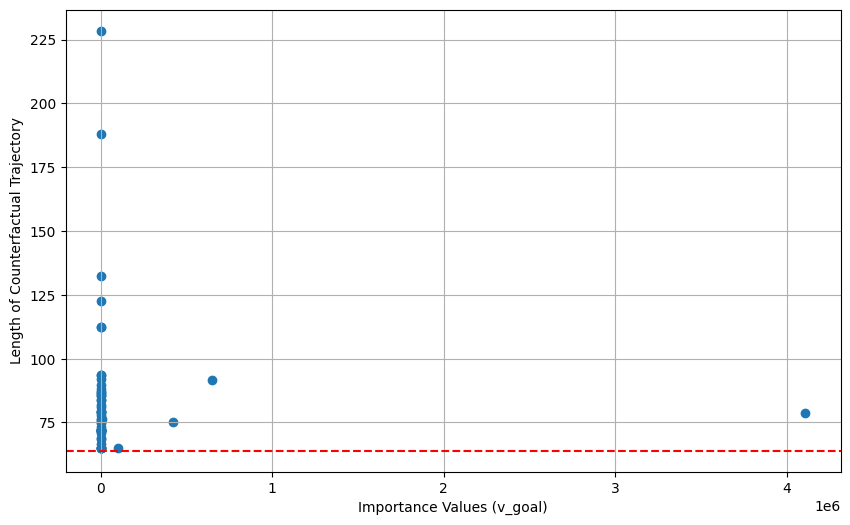
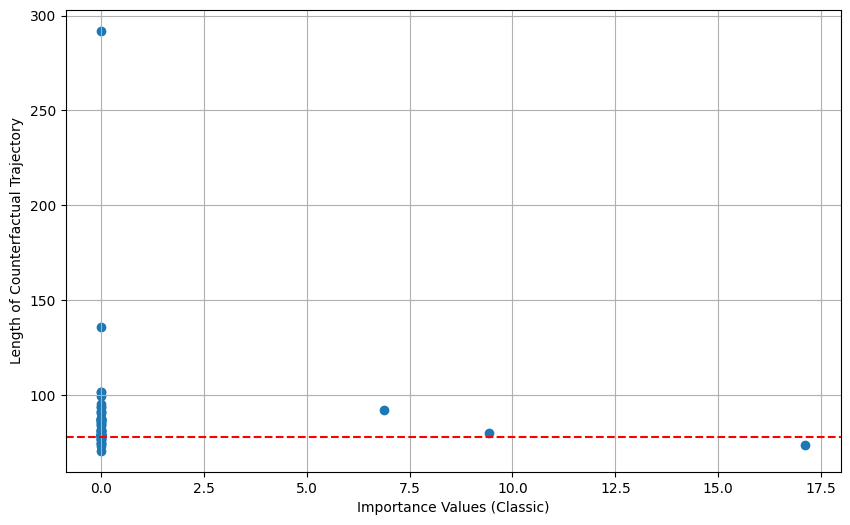
关键设计:状态重要性度量公式为:Importance(s) = Q_diff(s) + RadicalTerm(s)。其中,Q_diff(s)表示状态s下最优动作和次优动作的Q值差异;RadicalTerm(s)表示智能体从状态s到达目标的倾向,具体计算方式未知(论文中未明确说明)。轨迹的重要性得分通过对轨迹中所有状态的重要性度量进行聚合得到,聚合方式未知(论文中未明确说明)。反事实轨迹的生成方式也未知(论文中未明确说明)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法提出的状态重要性度量比经典的Q值差异更有效地识别最优行为。在OpenAI Gym的多个环境中,该方法能够成功地从异构的轨迹集合中识别出最优轨迹,并生成有意义的反事实解释。具体的性能数据和提升幅度未知(论文摘要中未提供具体数值)。
🎯 应用场景
该研究成果可应用于各种需要可信强化学习的场景,例如自动驾驶、机器人控制、医疗诊断等。通过解释智能体的行为,可以提高用户对智能体的信任度,从而促进强化学习技术的广泛应用。此外,该方法还可以用于调试和优化强化学习模型,提高模型的性能和鲁棒性。
📄 摘要(原文)
As Reinforcement Learning (RL) agents are increasingly deployed in real-world applications, ensuring their behavior is transparent and trustworthy is paramount. A key component of trust is explainability, yet much of the work in Explainable RL (XRL) focuses on local, single-step decisions. This paper addresses the critical need for explaining an agent's long-term behavior through trajectory-level analysis. We introduce a novel framework that ranks entire trajectories by defining and aggregating a new state-importance metric. This metric combines the classic Q-value difference with a "radical term" that captures the agent's affinity to reach its goal, providing a more nuanced measure of state criticality. We demonstrate that our method successfully identifies optimal trajectories from a heterogeneous collection of agent experiences. Furthermore, by generating counterfactual rollouts from critical states within these trajectories, we show that the agent's chosen path is robustly superior to alternatives, thereby providing a powerful "Why this, and not that?" explanation. Our experiments in standard OpenAI Gym environments validate that our proposed importance metric is more effective at identifying optimal behaviors compared to classic approaches, offering a significant step towards trustworthy autonomous systems.