GradientSpace: Unsupervised Data Clustering for Improved Instruction Tuning
作者: Shrihari Sridharan, Deepak Ravikumar, Anand Raghunathan, Kaushik Roy
分类: cs.LG, cs.AI
发布日期: 2025-12-07
💡 一句话要点
GradientSpace:用于改进指令调优的无监督数据聚类方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 数据聚类 梯度空间 在线SVD LoRA 专家系统 梯度干涉
📋 核心要点
- 现有指令调优方法难以处理数据异构性,梯度干涉导致性能下降,基于语义相似性的聚类无法捕捉数据对模型参数的影响。
- GradientSpace通过在全维梯度空间中聚类样本,避免了降维带来的精度损失,并利用在线SVD算法降低了计算和存储成本。
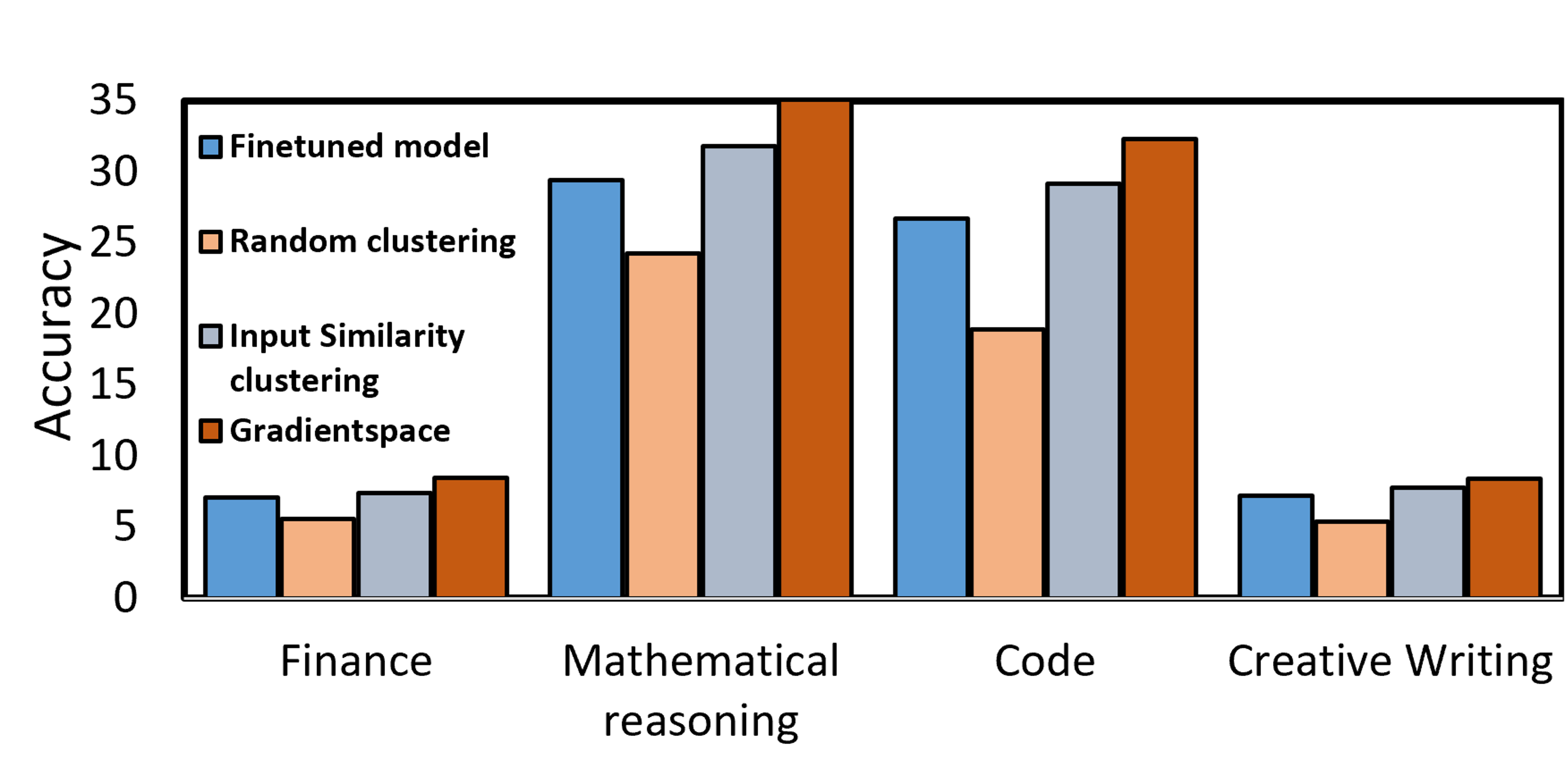
- 实验结果表明,GradientSpace在多个任务上优于现有聚类方法和微调技术,实现了专家专业化和准确性提升,并降低了推理延迟。
📝 摘要(中文)
指令调优是使大型语言模型(LLM)适应广泛下游应用的关键步骤之一。然而,由于真实世界的数据集很少是同质的,它们通常包含各种不同的信息,导致梯度干涉,即冲突的梯度将模型拉向相反的方向,从而降低性能,因此这个过程非常困难。一种常见的缓解策略是基于语义或嵌入相似性对数据进行分组。然而,这无法捕捉数据在学习过程中如何影响模型参数。虽然最近的工作试图直接对梯度进行聚类,但它们随机地将梯度投影到较低的维度以管理内存,这导致了精度损失。此外,这些方法依赖于专家集成,这需要多次推理传递和昂贵的推理期间的即时梯度计算。为了解决这些限制,我们提出了GradientSpace,一个直接在全维梯度空间中对样本进行聚类的框架。我们引入了一种基于在线SVD的算法,该算法作用于LoRA梯度,以识别潜在技能,而无需存储所有样本梯度的不可行成本。每个集群用于训练一个专门的LoRA专家,以及一个轻量级路由器,该路由器被训练为在推理期间选择最佳专家。我们表明,路由到单个合适的专家优于先前工作中使用的专家集成,同时显著降低了推理延迟。我们在数学推理、代码生成、金融和创意写作任务上的实验表明,GradientSpace相对于最先进的聚类方法和微调技术,能够实现一致的专家专业化和持续的准确性提升。
🔬 方法详解
问题定义:指令调优中,异构数据导致梯度干涉,降低模型性能。现有基于语义相似性的聚类方法无法有效捕捉数据对模型参数的影响。直接对梯度聚类的方法,如随机降维,会损失精度,且依赖专家集成,增加推理成本。
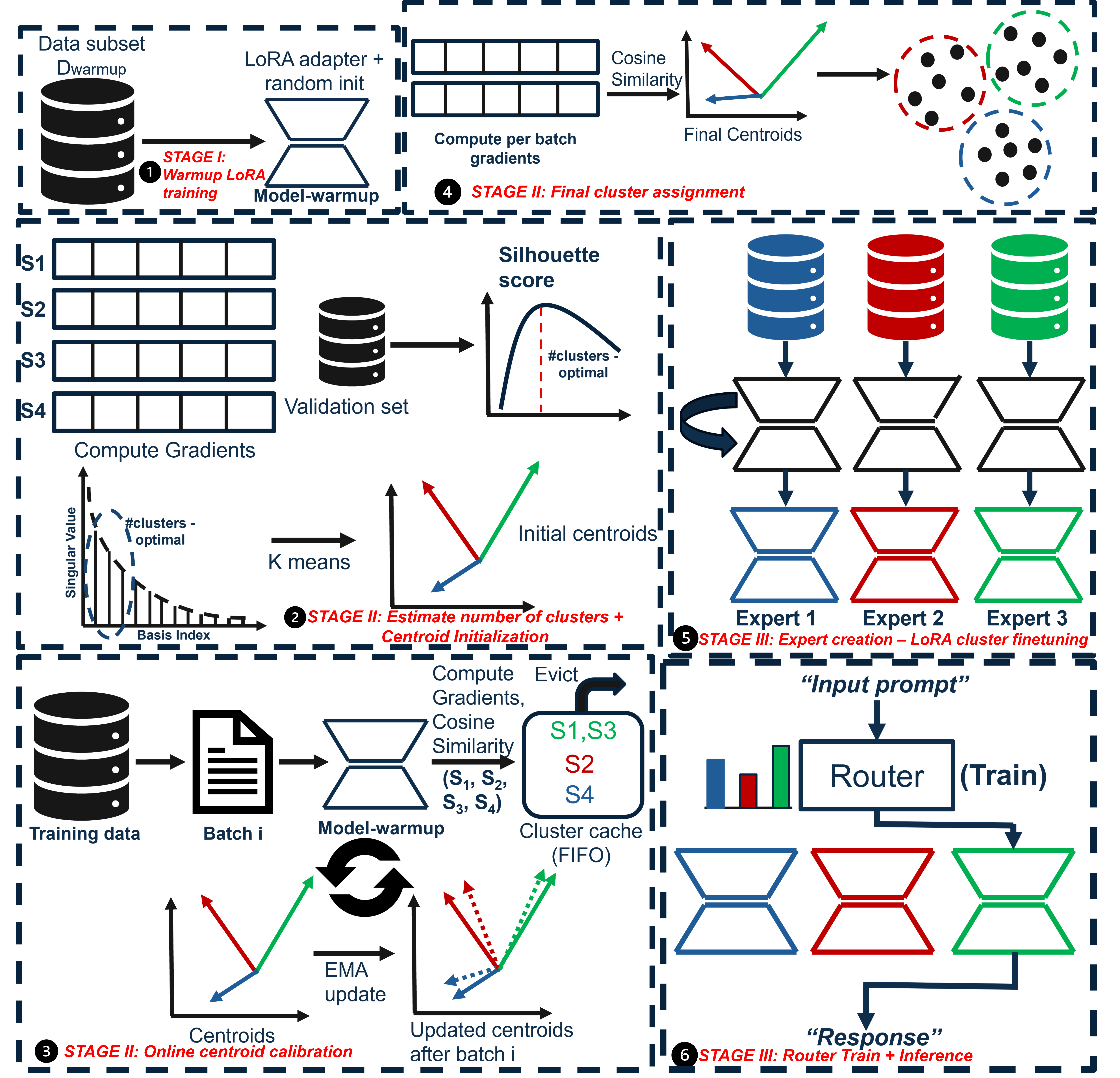
核心思路:GradientSpace的核心思路是在全维梯度空间中直接对样本进行聚类,避免降维带来的精度损失。通过在线SVD算法,降低存储和计算梯度信息的成本,从而实现高效的梯度空间聚类。每个簇训练一个LoRA专家,并训练一个轻量级路由器在推理时选择最佳专家。
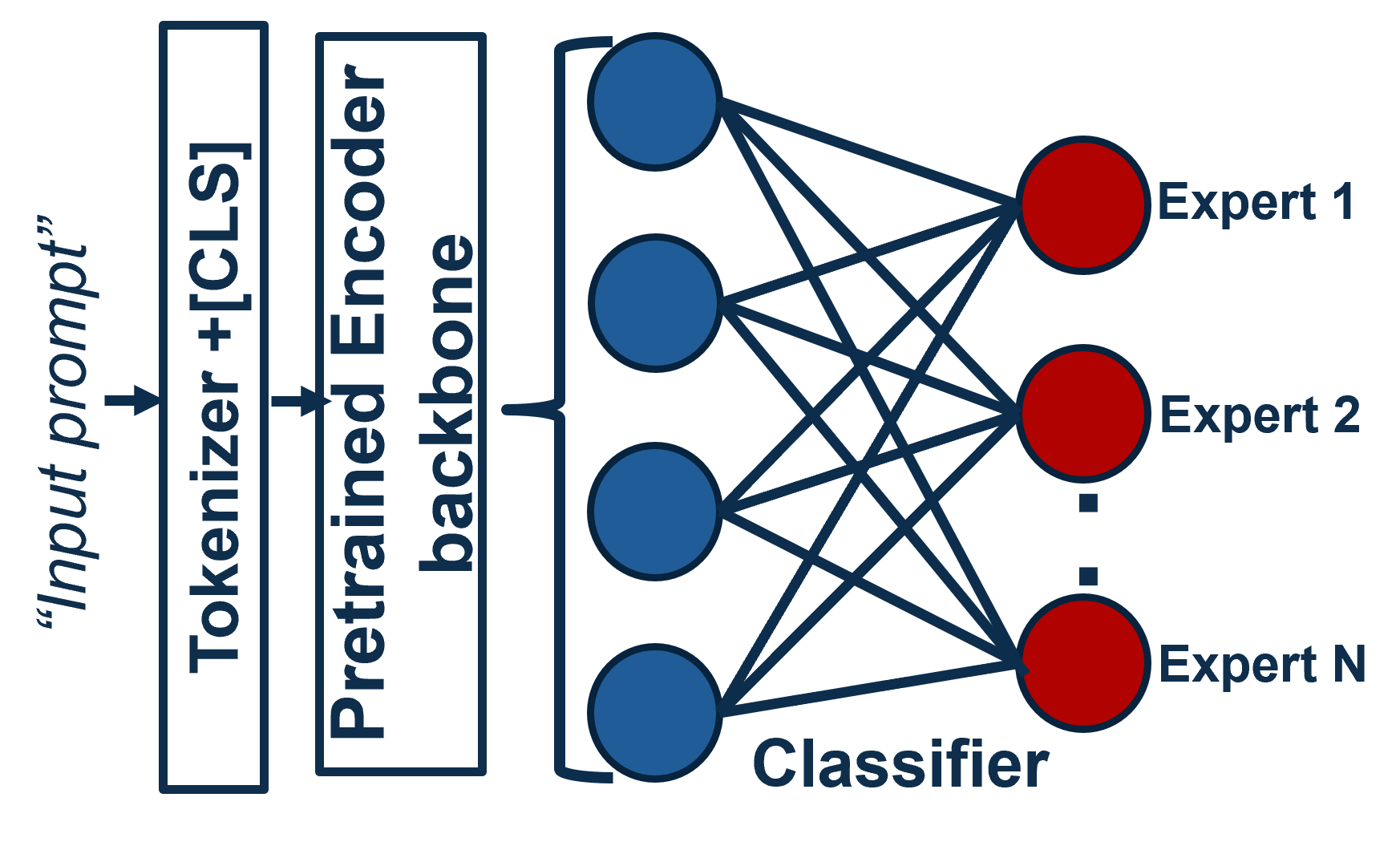
技术框架:GradientSpace框架包含以下几个主要模块:1) LoRA梯度计算:使用LoRA(Low-Rank Adaptation)方法计算每个样本的梯度。2) 在线SVD聚类:使用在线SVD算法在全维梯度空间中对样本进行聚类。3) 专家训练:为每个簇训练一个LoRA专家。4) 路由器训练:训练一个轻量级路由器,用于在推理时选择最佳专家。
关键创新:GradientSpace的关键创新在于:1) 在全维梯度空间中进行聚类,避免了降维带来的精度损失。2) 采用在线SVD算法,降低了梯度存储和计算成本,使其能够处理大规模数据集。3) 使用轻量级路由器选择单个专家,而非专家集成,显著降低了推理延迟。
关键设计:在线SVD算法是GradientSpace的关键设计。具体来说,该算法维护一个梯度协方差矩阵的低秩近似,并使用该近似来更新聚类中心。路由器是一个小型神经网络,输入是输入样本,输出是每个专家的选择概率。损失函数包括聚类损失和专家选择损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GradientSpace在数学推理、代码生成、金融和创意写作等任务上,均优于现有的聚类方法和微调技术。例如,在数学推理任务上,GradientSpace相对于基线方法取得了显著的准确性提升。此外,GradientSpace通过路由到单个专家,显著降低了推理延迟,优于依赖专家集成的方法。
🎯 应用场景
GradientSpace可应用于各种需要指令调优的场景,例如自然语言处理、代码生成、金融分析和创意写作等。通过对数据进行聚类并训练专门的专家,可以提高模型在特定任务上的性能,并降低推理成本。该方法尤其适用于处理包含大量异构数据的情况,例如多领域对话系统和通用人工智能模型。
📄 摘要(原文)
Instruction tuning is one of the key steps required for adapting large language models (LLMs) to a broad spectrum of downstream applications. However, this procedure is difficult because real-world datasets are rarely homogeneous; they consist of a mixture of diverse information, causing gradient interference, where conflicting gradients pull the model in opposing directions, degrading performance. A common strategy to mitigate this issue is to group data based on semantic or embedding similarity. However, this fails to capture how data influences model parameters during learning. While recent works have attempted to cluster gradients directly, they randomly project gradients into lower dimensions to manage memory, which leads to accuracy loss. Moreover, these methods rely on expert ensembles which necessitates multiple inference passes and expensive on-the-fly gradient computations during inference. To address these limitations, we propose GradientSpace, a framework that clusters samples directly in full-dimensional gradient space. We introduce an online SVD-based algorithm that operates on LoRA gradients to identify latent skills without the infeasible cost of storing all sample gradients. Each cluster is used to train a specialized LoRA expert along with a lightweight router trained to select the best expert during inference. We show that routing to a single, appropriate expert outperforms expert ensembles used in prior work, while significantly reducing inference latency. Our experiments across mathematical reasoning, code generation, finance, and creative writing tasks demonstrate that GradientSpace leads to coherent expert specialization and consistent accuracy gains over state-of-the-art clustering methods and finetuning techniques.