A-3PO: Accelerating Asynchronous LLM Training with Staleness-aware Proximal Policy Approximation
作者: Xiaocan Li, Shiliang Wu, Zheng Shen
分类: cs.LG, cs.AI, cs.DC
发布日期: 2025-12-06 (更新: 2026-01-09)
🔗 代码/项目: GITHUB
💡 一句话要点
A-3PO:通过近似近端策略加速异步LLM训练,提升训练效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 异步训练 近端策略优化 策略近似
📋 核心要点
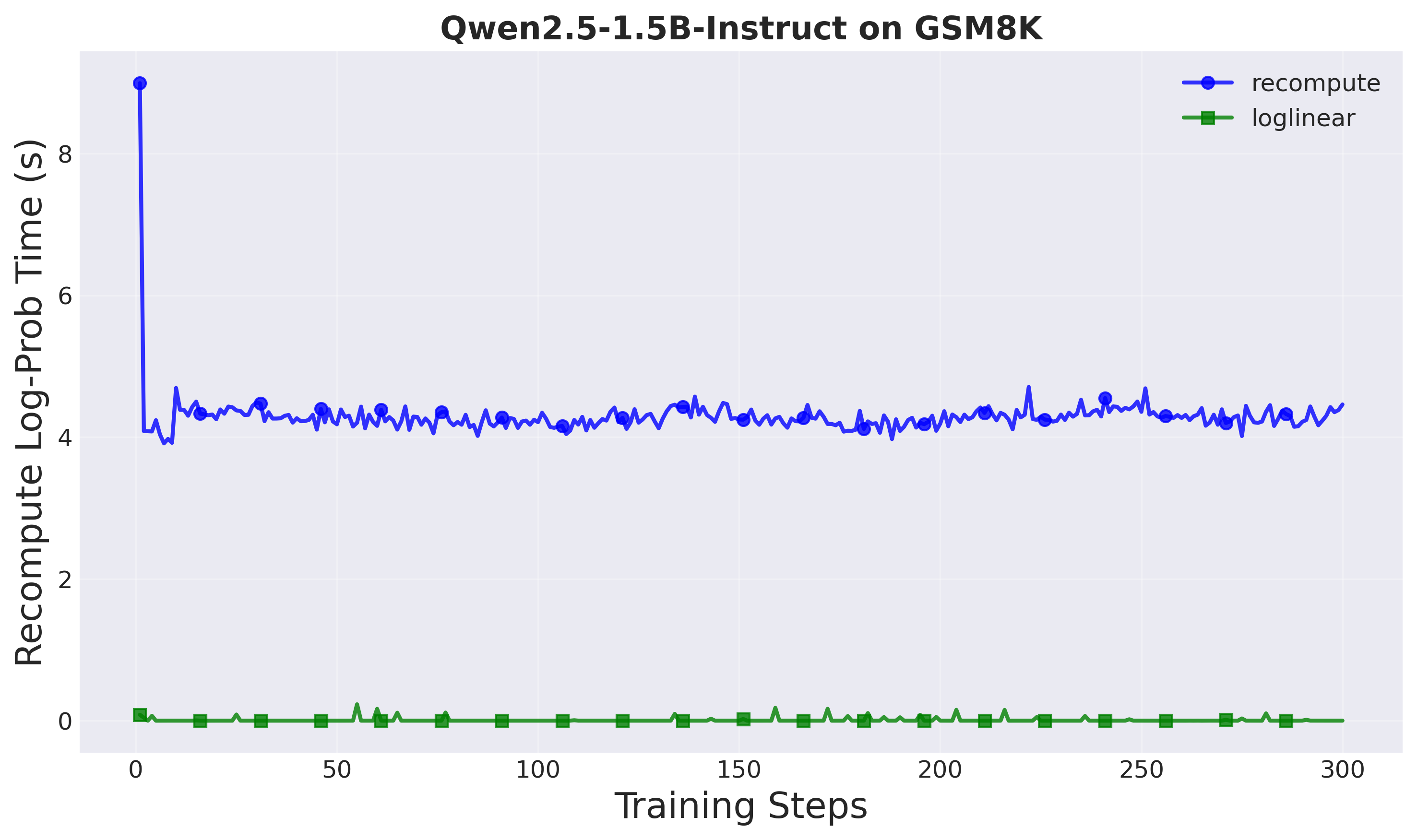
- 异步强化学习中,现有解耦PPO算法虽能处理数据陈旧性,但近端策略计算引入了额外的大模型正向传播开销。
- A-3PO通过简单插值近似近端策略,无需额外计算,降低了计算负担,加速了训练过程。
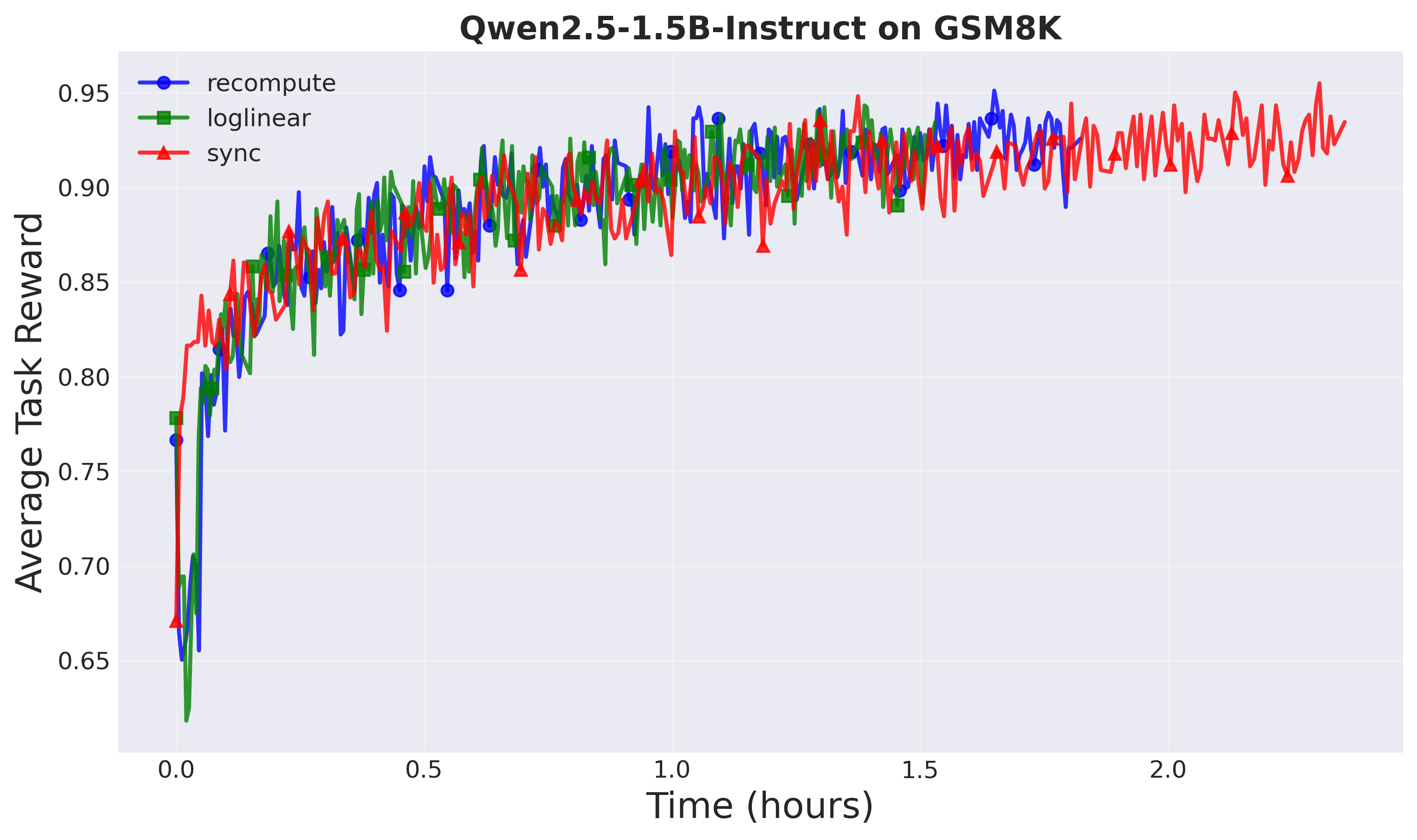
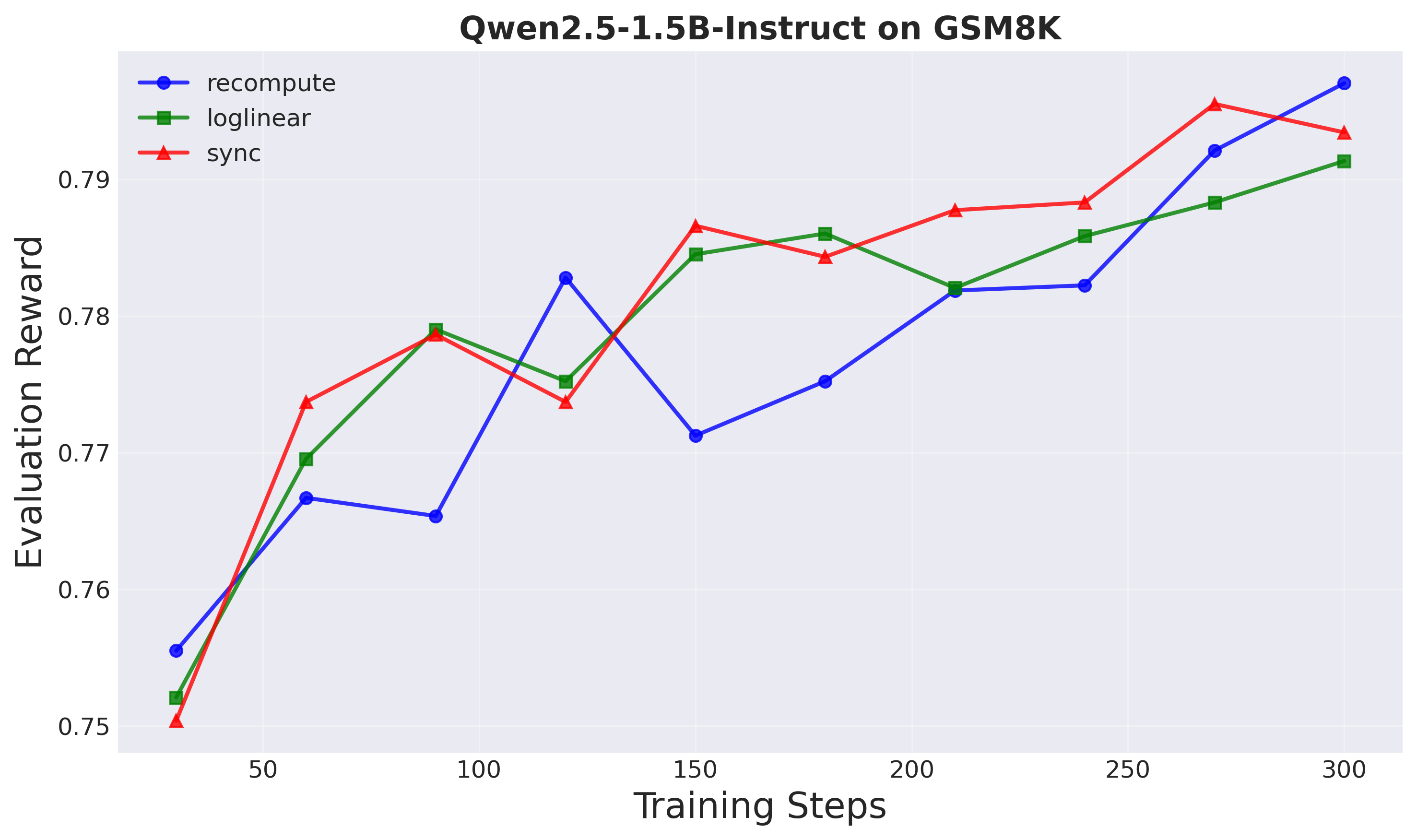
- 实验表明,A-3PO在保持性能的同时,实现了1.8倍的训练加速,验证了其有效性。
📝 摘要(中文)
解耦PPO算法在异步强化学习环境中处理高数据陈旧性方面表现出色。解耦PPO中使用的解耦损失通过引入近端策略来解耦离策略校正(重要性权重)和策略更新约束(信任区域),从而提高了耦合损失风格算法(例如,标准PPO、GRPO)的学习稳定性。然而,近端策略需要在每个训练步骤中对模型进行额外的正向传播,这给大型语言模型的训练带来了计算开销。我们观察到,由于近端策略仅作为行为策略和目标策略之间的信任区域锚点,我们可以通过简单的插值来近似它,而无需显式计算。我们将这种方法称为A-3PO(近似近端策略优化)。A-3PO消除了这种开销,在保持相当性能的同时,将训练速度提高了1.8倍。
🔬 方法详解
问题定义:论文旨在解决异步强化学习训练大型语言模型时,因使用解耦PPO算法而引入的额外计算开销问题。具体来说,解耦PPO算法中的近端策略需要额外的模型正向传播,这在大模型训练中成为一个显著的瓶颈。现有方法的痛点在于计算效率低下,限制了训练速度。
核心思路:论文的核心思路是通过近似近端策略来消除额外的计算开销。作者观察到近端策略的主要作用是作为行为策略和目标策略之间的信任区域锚点,因此可以通过简单的插值方法来近似,而无需进行完整的模型正向传播。这种近似方法在保证策略更新稳定性的同时,显著降低了计算复杂度。
技术框架:A-3PO算法沿用了PPO的整体框架,包括策略网络和价值网络。主要流程如下:1)使用行为策略生成数据;2)计算重要性权重;3)使用插值方法近似近端策略;4)利用近似的近端策略更新策略网络和价值网络。关键在于第三步,即近端策略的近似过程。
关键创新:A-3PO最关键的创新在于提出了近似近端策略的思想,避免了对近端策略的显式计算。与传统的PPO算法相比,A-3PO不再需要对近端策略进行完整的模型正向传播,而是通过插值等简单方法进行近似。这种方法在计算效率上具有显著优势,尤其是在训练大型语言模型时。
关键设计:A-3PO的关键设计在于如何进行近端策略的近似。论文中提到可以使用简单的插值方法,例如线性插值,在行为策略和目标策略之间进行插值,得到近似的近端策略。具体的插值系数可以根据实际情况进行调整。此外,A-3PO的损失函数与PPO类似,包括策略损失、价值损失和熵正则化项。策略损失使用近似的近端策略来约束策略更新,保证策略更新的稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,A-3PO算法在保持与传统PPO算法相当的性能水平下,实现了1.8倍的训练加速。这意味着在相同的训练时间内,A-3PO可以训练出更好的模型,或者在更短的时间内达到相同的性能水平。这一结果充分证明了A-3PO算法的有效性和优越性。
🎯 应用场景
A-3PO算法可广泛应用于需要使用强化学习训练大型语言模型的场景,例如对话系统、文本生成、智能客服等。通过加速训练过程,A-3PO可以降低训练成本,缩短开发周期,并促进更复杂、更智能的语言模型的开发。该方法具有很高的实际应用价值和潜力。
📄 摘要(原文)
Decoupled PPO has been a successful reinforcement learning (RL) algorithm to deal with the high data staleness under the asynchronous RL setting. Decoupled loss used in decoupled PPO improves coupled-loss style of algorithms' (e.g., standard PPO, GRPO) learning stability by introducing a proximal policy to decouple the off-policy correction (importance weight) from the policy update constraint (trust region). However, the proximal policy requires an extra forward pass through the model at each training step, creating a computational overhead for large language models training. We observe that since the proximal policy only serves as a trust region anchor between the behavior and target policies, we can approximate it through simple interpolation without explicit computation. We call this approach A-3PO (APproximated Proximal Policy Optimization). A-3PO eliminates this overhead, accelerating training by 1.8x speedup while maintaining comparable performance. Code \& off-the-shelf example are available at: https://github.com/inclusionAI/AReaL/blob/main/docs/algorithms/prox_approx.md