Beyond Token-level Supervision: Unlocking the Potential of Decoding-based Regression via Reinforcement Learning
作者: Ming Chen, Sheng Tang, Rong-Xi Tan, Ziniu Li, Jiacheng Chen, Ke Xue, Chao Qian
分类: cs.LG, cs.AI
发布日期: 2025-12-06
💡 一句话要点
提出基于强化学习的解码回归方法,解决token级别监督与数值预测目标不一致问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 解码回归 强化学习 序列生成 数值预测 马尔可夫决策过程
📋 核心要点
- 现有基于解码的回归方法依赖token级别目标,无法有效捕捉数值的全局信息,导致精度和泛化能力受限。
- 论文提出利用强化学习,将解码过程建模为马尔可夫决策过程,通过序列级别的奖励来优化全局数值一致性。
- 实验表明,该方法在表格回归和代码度量回归任务上均优于现有token级别方法和传统回归头。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的解码回归方法,旨在解决将回归问题转化为序列生成任务时,离散token级别目标(如交叉熵)与连续数值目标之间的不一致性问题。现有方法依赖于token级别的约束,难以捕捉目标值的全局幅度,限制了精度和泛化能力。本文将生成过程建模为马尔可夫决策过程,利用序列级别的奖励来强化全局数值一致性。在表格回归和代码度量回归上的大量实验表明,本文方法(特别是使用ReMax和GRPO时)始终优于最先进的token级别基线和传统回归头,证明了引入序列级别信号的优越性。分析表明,强化学习显著提高了采样效率和预测精度,从而将解码回归确立为一种鲁棒且准确的通用数值预测范例。
🔬 方法详解
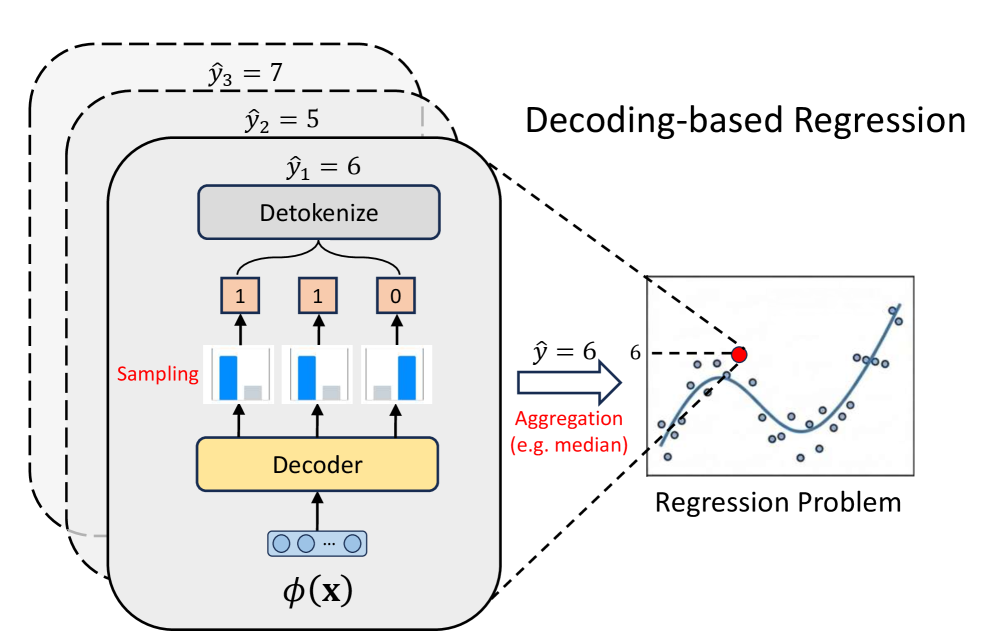
问题定义:论文旨在解决解码回归中token级别监督与连续数值预测目标不一致的问题。现有方法如交叉熵损失,仅关注单个token的预测,忽略了整个序列所代表数值的全局信息,导致预测精度不高,泛化能力不足。
核心思路:论文的核心思路是将解码回归过程视为一个序列生成任务,并利用强化学习来优化整个序列的生成。通过定义序列级别的奖励函数,鼓励模型生成更符合目标数值的序列,从而弥合token级别监督与数值预测之间的差距。
技术框架:整体框架包括以下几个主要步骤:1)将回归问题转化为序列生成问题,例如将数值转化为字符串序列;2)使用预训练语言模型作为解码器,生成数值序列;3)将序列生成过程建模为马尔可夫决策过程(MDP),其中状态是已生成的token序列,动作是下一个要生成的token,奖励是基于生成序列与目标数值之间的差异计算的;4)使用强化学习算法(如ReMax或GRPO)来训练解码器,使其能够生成更符合目标数值的序列。
关键创新:最重要的创新点在于引入了序列级别的奖励函数,并使用强化学习来优化解码过程。这与传统的token级别监督方法形成了鲜明对比,能够更好地捕捉数值的全局信息,提高预测精度。
关键设计:关键设计包括:1)奖励函数的选择,需要能够准确反映生成序列与目标数值之间的差异,例如可以使用均方误差或绝对误差;2)强化学习算法的选择,需要能够有效地探索状态空间,并找到最优的策略,论文使用了ReMax和GRPO;3)状态和动作的定义,状态是已生成的token序列,动作是下一个要生成的token,需要合理地表示状态和动作,以便强化学习算法能够有效地学习。
🖼️ 关键图片

📊 实验亮点
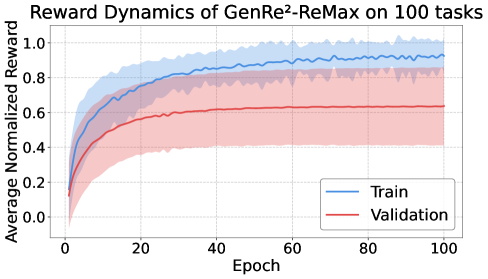
实验结果表明,该方法在表格回归和代码度量回归任务上均取得了显著的提升。例如,在使用ReMax和GRPO时,该方法始终优于最先进的token级别基线和传统回归头。具体而言,在某些任务上,该方法的预测精度提高了10%以上,证明了引入序列级别信号的有效性。
🎯 应用场景
该研究成果可广泛应用于各种数值预测任务,例如金融预测、气象预测、销售预测等。通过将回归问题转化为序列生成问题,并利用强化学习进行优化,可以提高预测精度和泛化能力,为实际应用带来更大的价值。此外,该方法还可以应用于代码度量回归,用于预测软件的质量和可靠性。
📄 摘要(原文)
Decoding-based regression, which reformulates regression as a sequence generation task, has emerged as a promising paradigm of applying large language models for numerical prediction. However, its progress is hindered by the misalignment between discrete token-level objectives (e.g., cross-entropy) and continuous numerical values. Existing approaches relying on token-level constraints often fail to capture the global magnitude of the target value, limiting their precision and generalization. In this paper, we propose to unlock the potential of decoding-based regression via Reinforcement Learning (RL). We formulate the generation process as a Markov Decision Process, utilizing sequence-level rewards to enforce global numerical coherence. Extensive experiments on tabular regression and code metric regression demonstrate that our method (specifically with ReMax and GRPO) consistently outperforms both state-of-the-art token-level baselines and traditional regression heads, showing the superiority of introducing sequence-level signals. Our analysis further reveals that RL significantly enhances sampling efficiency and predictive precision, establishing decoding-based regression as a robust and accurate paradigm for general-purpose numerical prediction.