DDFI: Diverse and Distribution-aware Missing Feature Imputation via Two-step Reconstruction
作者: Yifan Song, Fenglin Yu, Yihong Luo, Xingjian Tao, Siya Qiu, Kai Han, Jing Tang
分类: cs.LG, cs.SI
发布日期: 2025-12-06 (更新: 2025-12-11)
💡 一句话要点
提出DDFI,通过双步重构实现多样性和分布感知的缺失特征填充,提升图神经网络性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图神经网络 特征填充 缺失数据 掩码自动编码器 特征传播 协同标签链接 归纳学习 图数据挖掘
📋 核心要点
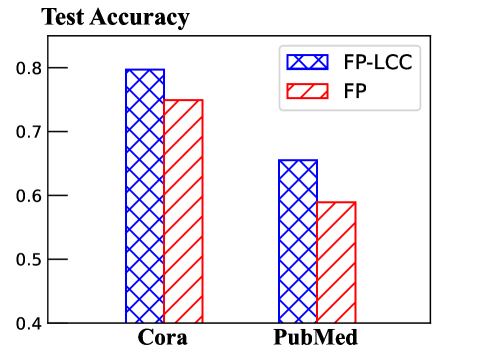
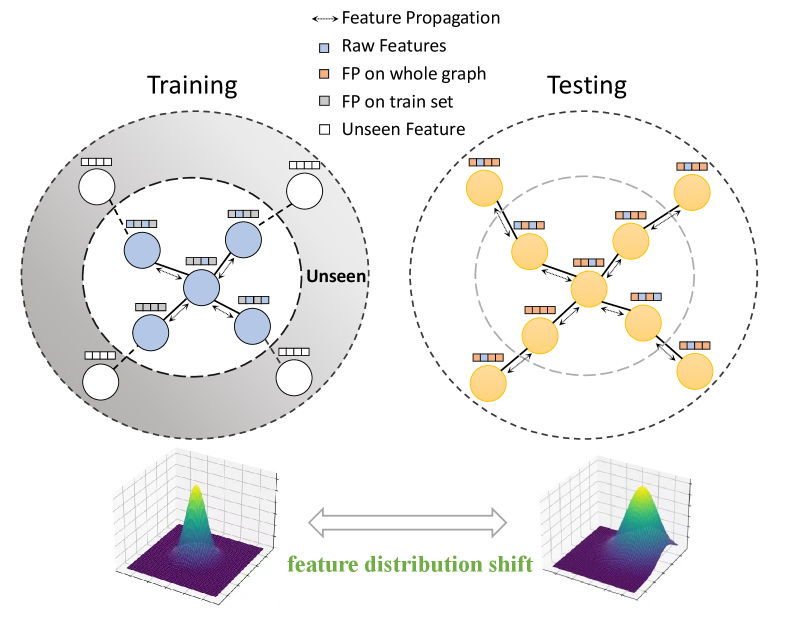
- 现有特征传播方法在处理非完全连接图时存在困难,且易导致过度平滑,限制了GNN的性能。
- DDFI结合特征传播与图掩码自动编码器,通过协同标签链接增强连接性,并采用两步重构减少分布偏移。
- 实验结果表明,DDFI在多个数据集上,包括新收集的Sailing数据集,均优于现有最先进的特征填充方法。
📝 摘要(中文)
现实场景中节点特征不完整是普遍存在的,例如,网络用户的属性可能部分是私有的,这会导致图神经网络(GNN)的性能显著下降。特征传播(FP)是一种众所周知的方法,在图上填充缺失节点特征方面表现良好,但它仍然存在以下三个问题:1)难以处理非完全连接的图;2)填充的特征面临过度平滑问题;3)FP是为转导任务量身定制的,忽略了归纳任务中的特征分布偏移。为了应对这些挑战,我们提出了一种多样性和分布感知的缺失特征填充方法DDFI,该方法以一种非平凡的方式将特征传播与基于图的掩码自动编码器(MAE)相结合。它首先设计了一种简单而有效的算法,即协同标签链接(CLL),随机连接训练集中具有相同标签的节点,以增强在具有大量连接组件的图上的性能。然后,我们在推理阶段开发了一种新颖的两步表示生成过程。具体来说,DDFI没有直接使用FP填充的特征作为推理期间的输入,而是通过整个MAE进一步重建特征,以减少归纳任务中的特征分布偏移并增强节点特征的多样性。同时,由于现有的图特征填充方法仅通过手动掩盖特征来模拟缺失场景进行评估,因此我们收集了一个名为Sailing的新数据集,该数据集包含自然缺失的特征,以帮助更好地评估有效性。在六个公共数据集和Sailing上进行的大量实验表明,DDFI在转导和归纳设置下均优于最先进的方法。
🔬 方法详解
问题定义:论文旨在解决图神经网络中普遍存在的节点特征缺失问题,尤其是在图结构不完整或存在分布偏移的情况下,现有特征传播方法难以有效填充缺失特征,导致GNN性能下降。现有方法主要痛点在于无法有效处理非完全连接图,容易产生过平滑问题,且忽略了归纳学习中的特征分布偏移。
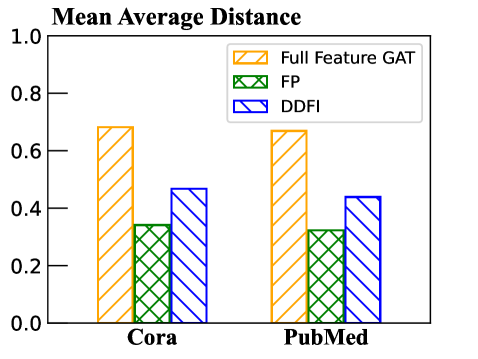
核心思路:DDFI的核心思路是结合特征传播的局部信息聚合能力和掩码自动编码器的全局特征重构能力,通过协同标签链接增强图的连接性,并利用两步重构过程来减少特征分布偏移,从而实现更有效和鲁棒的缺失特征填充。这样设计的目的是为了克服传统特征传播方法的局限性,同时提高模型在归纳学习场景下的泛化能力。
技术框架:DDFI的整体框架包含三个主要部分:1) 协同标签链接(CLL):在训练阶段,随机连接具有相同标签的节点,以增强图的连接性。2) 特征传播:利用图结构进行初步的特征填充。3) 基于图的掩码自动编码器(MAE):通过掩码部分节点特征并进行重构,学习节点特征的潜在表示。在推理阶段,DDFI采用两步表示生成过程:首先使用特征传播进行初步填充,然后通过整个MAE进行特征重构,以减少分布偏移并增强特征多样性。
关键创新:DDFI的关键创新在于:1) 协同标签链接(CLL)算法,有效增强了非完全连接图的连接性。2) 两步表示生成过程,通过MAE的重构减少了特征分布偏移,提高了模型在归纳学习中的泛化能力。3) 结合特征传播和掩码自动编码器,充分利用了局部和全局信息,实现了更鲁棒的特征填充。与现有方法的本质区别在于,DDFI不仅关注特征的填充,更关注填充后特征的分布和多样性。
关键设计:协同标签链接(CLL)算法的关键参数是连接概率,需要根据图的连接情况进行调整。掩码自动编码器(MAE)的网络结构可以根据具体任务进行选择,损失函数通常采用均方误差或交叉熵损失。特征传播的权重可以采用固定的权重或学习的权重。在两步重构过程中,需要仔细调整特征传播和MAE的权重,以平衡局部信息和全局信息的贡献。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DDFI在六个公共数据集和新收集的Sailing数据集上均优于最先进的方法。例如,在某些数据集上,DDFI的性能提升超过5%。此外,DDFI在归纳学习设置下表现出更强的泛化能力,证明了其在处理特征分布偏移方面的有效性。
🎯 应用场景
DDFI可应用于各种存在节点特征缺失的图数据场景,例如社交网络用户属性推断、知识图谱补全、生物信息学基因功能预测等。该方法能够提升图神经网络在不完整数据上的性能,具有重要的实际应用价值,并为未来图数据分析和挖掘提供更可靠的基础。
📄 摘要(原文)
Incomplete node features are ubiquitous in real-world scenarios, e.g., the attributes of web users may be partly private, which causes the performance of Graph Neural Networks (GNNs) to decline significantly. Feature propagation (FP) is a well-known method that performs well for imputation of missing node features on graphs, but it still has the following three issues: 1) it struggles with graphs that are not fully connected, 2) imputed features face the over-smoothing problem, and 3) FP is tailored for transductive tasks, overlooking the feature distribution shift in inductive tasks. To address these challenges, we introduce DDFI, a Diverse and Distribution-aware Missing Feature Imputation method that combines feature propagation with a graph-based Masked AutoEncoder (MAE) in a nontrivial manner. It first designs a simple yet effective algorithm, namely Co-Label Linking (CLL), that randomly connects nodes in the training set with the same label to enhance the performance on graphs with numerous connected components. Then we develop a novel two-step representation generation process at the inference stage. Specifically, instead of directly using FP-imputed features as input during inference, DDFI further reconstructs the features through the whole MAE to reduce feature distribution shift in the inductive tasks and enhance the diversity of node features. Meanwhile, since existing feature imputation methods for graphs only evaluate by simulating the missing scenes with manually masking the features, we collect a new dataset called Sailing from the records of voyages that contains naturally missing features to help better evaluate the effectiveness. Extensive experiments conducted on six public datasets and Sailing show that DDFI outperforms the state-of-the-art methods under both transductive and inductive settings.