Learning Without Time-Based Embodiment Resets in Soft-Actor Critic
作者: Homayoon Farrahi, A. Rupam Mahmood
分类: cs.LG
发布日期: 2025-12-06
备注: In Proceedings of the 4th Conference on Lifelong Learning Agents (CoLLAs)
💡 一句话要点
提出持续性SAC算法,解决强化学习中依赖重置和终止的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 软演员-评论家算法 持续学习 无重置学习 策略熵 机器人控制 状态空间探索
📋 核心要点
- 传统强化学习依赖环境重置和episode终止,这限制了其在真实长期任务中的应用。
- 论文提出持续性SAC算法,通过修改奖励函数,使智能体能够在无终止环境中学习。
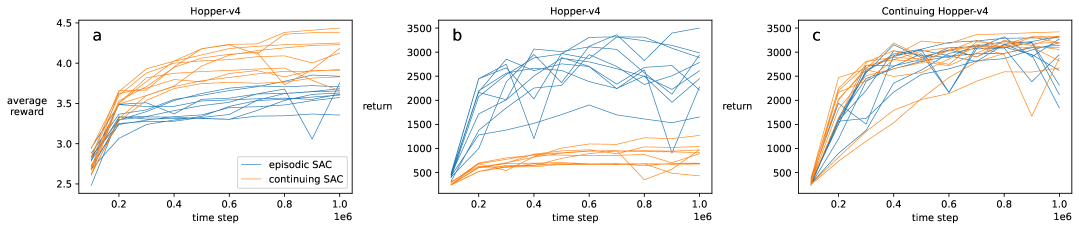
- 实验表明,在无重置情况下,增加策略熵可以有效提升性能,弥补探索不足。
📝 摘要(中文)
本文探讨了在使用软演员-评论家(SAC)算法时,不依赖episode终止和机器人重置进行学习的挑战。为了在没有终止的情况下学习,作者提出了一种持续性SAC算法,并通过对现有任务的奖励函数进行简单修改,证明了持续性SAC可以达到甚至超过episodic SAC的性能,同时降低了性能对折扣率γ值的敏感性。在修改后的Gym Reacher任务中,研究了持续性SAC在没有重置的情况下学习失败的可能原因。结果表明,重置有助于SAC算法探索状态空间,而移除重置可能导致状态空间探索不足,从而导致学习失败或显著减慢。最后,在其他模拟任务和真实机器人视觉任务中,作者表明,当性能趋势变差或保持静态时,增加策略的熵是恢复因未使用重置而损失的性能的有效干预措施。
🔬 方法详解
问题定义:现有的强化学习方法通常依赖于将环境交互分解为独立的episode,并频繁地重置环境。虽然这些技巧可以加速学习,但它们会导致任务设置不自然,并阻碍在真实世界中的长期性能。论文要解决的问题是如何在没有episode终止和机器人重置的情况下,使用SAC算法进行学习。现有方法的痛点在于,依赖重置会限制智能体在真实、连续环境中的应用能力。
核心思路:论文的核心思路是修改SAC算法,使其能够在连续的环境中进行学习,而不需要episode终止。通过调整奖励函数,并引入持续性的学习机制,使智能体能够更好地探索状态空间,并学习到长期策略。此外,论文还提出了一种增加策略熵的策略,以解决在没有重置的情况下,探索不足的问题。
技术框架:论文提出的持续性SAC算法,在SAC算法的基础上进行了修改。整体框架仍然是actor-critic结构,actor负责生成策略,critic负责评估策略的价值。主要的修改在于:1) 奖励函数的修改,使其适应连续环境;2) 引入持续性的学习机制,避免episode终止;3) 增加策略熵的策略,以促进探索。
关键创新:论文最重要的技术创新点在于提出了持续性SAC算法,并证明了其在没有episode终止和机器人重置的情况下,仍然能够有效地进行学习。此外,论文还提出了增加策略熵的策略,以解决在没有重置的情况下,探索不足的问题。
关键设计:论文的关键设计包括:1) 奖励函数的修改,例如使用稀疏奖励或形状奖励,以引导智能体进行学习;2) 折扣率γ的选择,论文发现持续性SAC对γ值的敏感性较低;3) 策略熵的调整,论文提出了一种自适应的策略熵调整方法,当性能下降或停滞时,增加策略熵,以促进探索。
🖼️ 关键图片


📊 实验亮点
实验结果表明,持续性SAC算法在多个模拟任务中表现良好,甚至优于传统的episodic SAC算法。在Gym Reacher任务中,通过增加策略熵,成功解决了因缺乏重置导致的探索不足问题。此外,在真实机器人视觉任务中,也验证了该方法的有效性,表明其具有较强的泛化能力。
🎯 应用场景
该研究成果可应用于机器人长期自主导航、连续制造过程控制、以及其他需要在真实、连续环境中进行决策的任务。通过消除对环境重置的依赖,可以使强化学习算法更具实用性,并能够更好地适应真实世界的复杂性和不确定性。未来,该方法有望推动机器人和人工智能在更广泛领域的应用。
📄 摘要(原文)
When creating new reinforcement learning tasks, practitioners often accelerate the learning process by incorporating into the task several accessory components, such as breaking the environment interaction into independent episodes and frequently resetting the environment. Although they can enable the learning of complex intelligent behaviors, such task accessories can result in unnatural task setups and hinder long-term performance in the real world. In this work, we explore the challenges of learning without episode terminations and robot embodiment resets using the Soft Actor-Critic (SAC) algorithm. To learn without terminations, we present a continuing version of the SAC algorithm and show that, with simple modifications to the reward functions of existing tasks, continuing SAC can perform as well as or better than episodic SAC while reducing the sensitivity of performance to the value of the discount rate $γ$. On a modified Gym Reacher task, we investigate possible explanations for the failure of continuing SAC when learning without embodiment resets. Our results suggest that embodiment resets help with exploration of the state space in the SAC algorithm, and removing embodiment resets can lead to poor exploration of the state space and failure of or significantly slower learning. Finally, on additional simulated tasks and a real-robot vision task, we show that increasing the entropy of the policy when performance trends worse or remains static is an effective intervention for recovering the performance lost due to not using embodiment resets.