Mitigating Catastrophic Forgetting in Mathematical Reasoning Finetuning through Mixed Training
作者: John Graham Reynolds
分类: cs.LG, cs.CL
发布日期: 2025-12-05
备注: 11 pages, 2 figures. Code available at https://github.com/johngrahamreynolds/mathematical_catastrophe_mitigation. Models available at https://huggingface.co/collections/MarioBarbeque/catastrophic-forgetting-in-mathematical-reasoning
💡 一句话要点
提出混合训练策略,缓解数学推理微调中的灾难性遗忘问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灾难性遗忘 混合训练 语言模型微调 数学推理 自然语言推理
📋 核心要点
- 在数学推理等特定任务上微调大型语言模型时,会发生灾难性遗忘,导致模型失去原有的通用能力。
- 论文提出一种混合训练策略,通过交错训练数学和自然语言推理(NLI)数据,以缓解灾难性遗忘。
- 实验表明,混合训练在保持数学推理性能的同时,显著提升了NLI的准确率,有效解决了灾难性遗忘问题。
📝 摘要(中文)
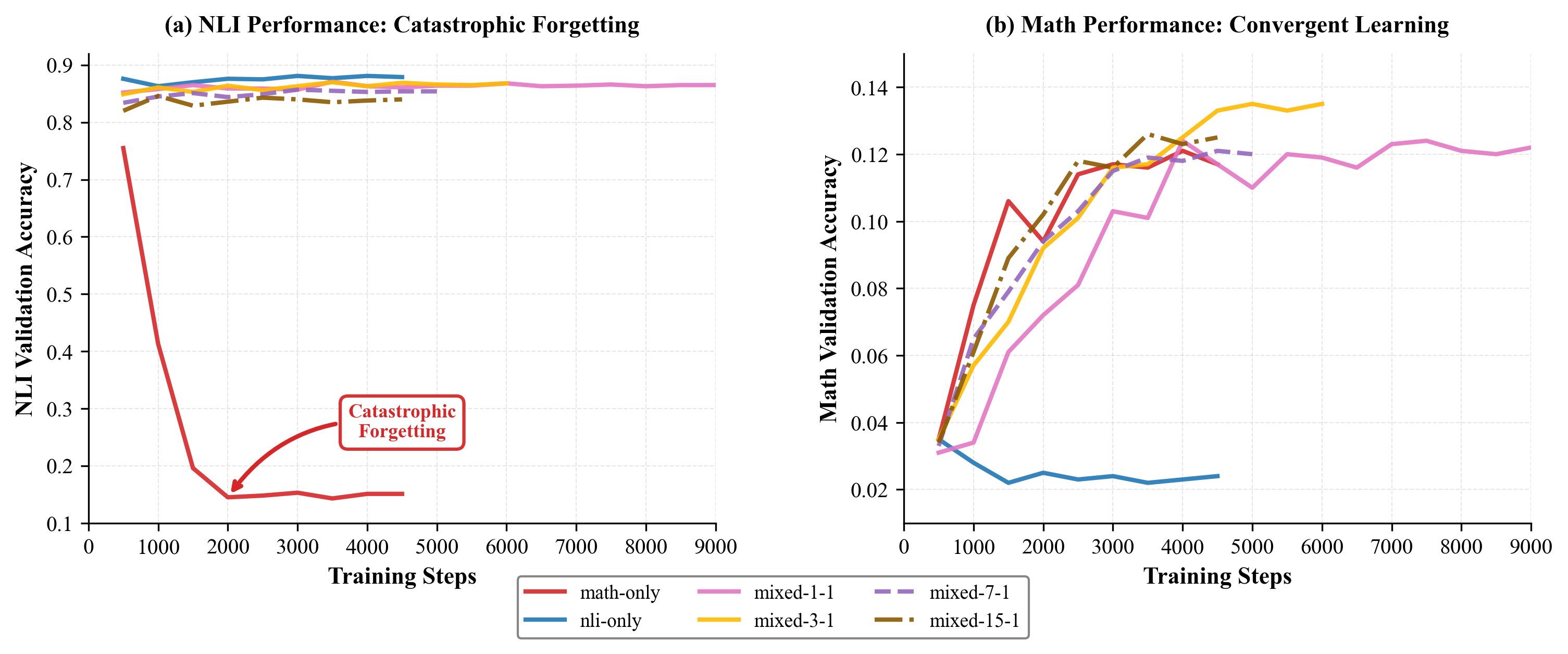
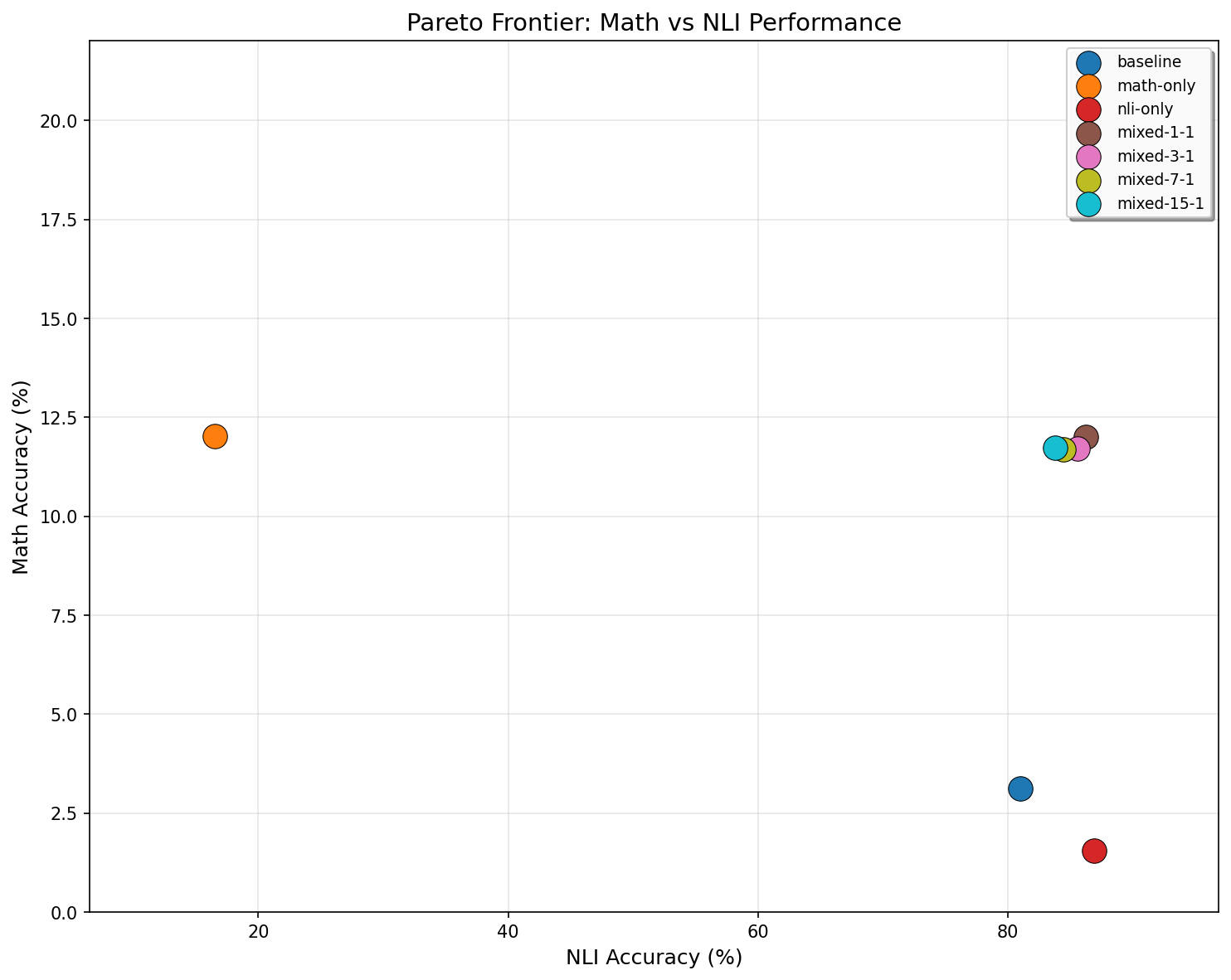
本文研究了在微调大型语言模型以执行数学推理等专门任务时出现的灾难性遗忘现象,即模型会丢失先前学习的能力。具体而言,作者在DeepMind Mathematics数据集上微调了Flan-T5-Base(2.5亿参数),并使用MultiNLI数据集来衡量遗忘程度。仅使用数学数据进行训练将数学准确率从3.1%提高到12.0%,但导致NLI准确率从81.0%下降到16.5%,在最初的1000个训练步骤中下降了64.5个百分点。为此,作者提出了一种混合训练策略,在训练过程中交错使用数学和NLI示例。实验结果表明,混合训练完全消除了灾难性遗忘,同时保持了相当的数学性能:平衡的1:1比例实现了12.0%的数学准确率(与仅数学训练相当),同时保持了86.2%的NLI准确率。作者系统地探索了从1:1到15:1的混合比例,发现即使是最小的NLI暴露(6.2%)也能提供有效的正则化。这些发现表明,专业化不需要以牺牲通用能力为代价,并且混合训练可能为扩展到更大的模型带来额外的好处,而不仅仅是防止遗忘。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在特定任务(如数学推理)上微调时出现的灾难性遗忘问题。现有方法,即仅使用目标任务数据进行微调,会导致模型在目标任务上性能提升的同时,显著降低在先前学习的通用任务上的性能。这种遗忘限制了模型在实际应用中的泛化能力。
核心思路:论文的核心思路是通过混合训练,即在微调过程中同时使用目标任务数据(数学推理)和通用任务数据(自然语言推理),来防止模型过度拟合目标任务,从而保留其原有的通用能力。这种方法类似于正则化,通过引入通用任务的数据,约束模型参数的学习方向。
技术框架:整体框架包括以下步骤:1. 选择预训练语言模型(Flan-T5-Base)。2. 构建数学推理数据集(DeepMind Mathematics)和自然语言推理数据集(MultiNLI)。3. 设计混合训练策略,即以不同的比例混合数学推理和自然语言推理数据。4. 使用混合数据集微调预训练模型。5. 在数学推理和自然语言推理数据集上评估模型性能。
关键创新:论文的关键创新在于提出了混合训练策略,并证明了即使少量通用任务数据也能有效缓解灾难性遗忘。与传统的仅使用目标任务数据进行微调的方法相比,混合训练能够更好地平衡模型在目标任务和通用任务上的性能。
关键设计:论文的关键设计包括:1. 混合比例的选择:作者系统地探索了从1:1到15:1的混合比例,以确定最佳的混合比例。2. 数据集的选择:选择DeepMind Mathematics作为数学推理数据集,MultiNLI作为自然语言推理数据集。3. 评估指标的选择:使用数学准确率和NLI准确率来评估模型在目标任务和通用任务上的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,混合训练策略能够有效缓解灾难性遗忘。在DeepMind Mathematics数据集上,仅使用数学数据进行微调,数学准确率提升至12.0%,但NLI准确率骤降至16.5%。而采用1:1的数学数据和NLI数据混合训练,数学准确率保持在12.0%的同时,NLI准确率恢复至86.2%,接近原始水平,证明了混合训练在防止灾难性遗忘方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型进行微调的场景,例如特定领域的文本生成、问答系统、代码生成等。通过混合训练,可以避免模型在特定领域表现优异的同时,丧失通用的语言理解和生成能力,从而提高模型的实用性和泛化性。该方法对于开发更可靠、更全面的AI系统具有重要意义。
📄 摘要(原文)
When finetuning large language models for specialized tasks such as mathematical reasoning, models exhibit catastrophic forgetting, losing previously learned capabilities. We investigate this by finetuning Flan-T5-Base (250M parameters) on the DeepMind Mathematics dataset and measuring forgetting on MultiNLI. Math-only training improves mathematical accuracy from 3.1\% to 12.0\% but causes NLI accuracy to collapse from 81.0\% to 16.5\%--a 64.5 percentage point drop occurring within the first 1,000 training steps. We propose mixed training strategies that interleave mathematical and NLI examples during training. Our results demonstrate that mixed training completely eliminates catastrophic forgetting while maintaining equivalent mathematical performance: the balanced 1:1 ratio achieves 12.0\% math accuracy (matching math-only) while preserving 86.2\% NLI accuracy. We systematically explore mixing ratios from 1:1 to 15:1, finding that even minimal NLI exposure (6.2\%) provides effective regularization. These findings demonstrate that specialization need not require forgetting general capabilities, with implications for scaling to larger models where mixed training may confer additional benefits beyond forgetting prevention.