Scaling and Transferability of Annealing Strategies in Large Language Model Training
作者: Siqi Wang, Zhengyu Chen, Teng Xiao, Zheqi Lv, Jinluan Yang, Xunliang Cai, Jingang Wang, Xiaomeng Li
分类: cs.LG, cs.AI
发布日期: 2025-12-05
备注: Accepted to AAAI 2026 (camera-ready version)
💡 一句话要点
提出一种可迁移的学习率退火策略优化框架,提升大语言模型训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 学习率调度 退火策略 迁移学习 超参数优化
📋 核心要点
- 现有大语言模型训练中,学习率退火策略的优化依赖大量实验,缺乏高效的迁移性方法。
- 论文提出一种改进的预测框架,通过结合训练步数、最大学习率和退火行为,优化学习率调度。
- 实验表明,最优退火比率具有一致性,可在不同模型配置间迁移,小模型可作为大模型的训练代理。
📝 摘要(中文)
学习率调度对于训练大型语言模型至关重要,但理解不同模型配置下的最优退火策略仍然具有挑战性。本文研究了大语言模型训练中退火动态的可迁移性,并改进了一个广义预测框架,用于优化Warmup-Steady-Decay (WSD)调度器下的退火策略。改进后的框架结合了训练步数、最大学习率和退火行为,从而能够更有效地优化学习率计划。我们的工作为选择最优退火策略提供了实用的指导,无需详尽的超参数搜索,证明了较小的模型可以作为优化较大模型训练动态的可靠代理。我们通过使用密集模型和混合专家(MoE)模型的大量实验验证了我们的发现,表明最优退火比率遵循一致的模式,并且可以在不同的训练配置之间迁移。
🔬 方法详解
问题定义:论文旨在解决大型语言模型训练中学习率退火策略难以优化和迁移的问题。现有方法通常需要对每个模型配置进行大量的超参数搜索,成本高昂且效率低下。缺乏一种通用的方法来预测和迁移不同模型配置下的最优退火策略,阻碍了大模型的快速训练和部署。
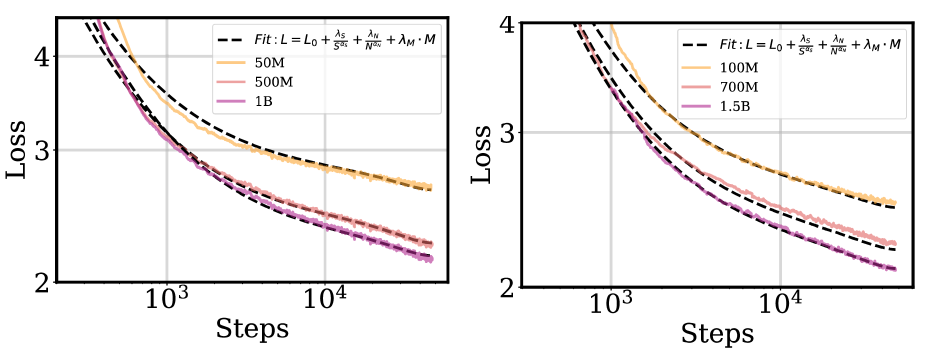
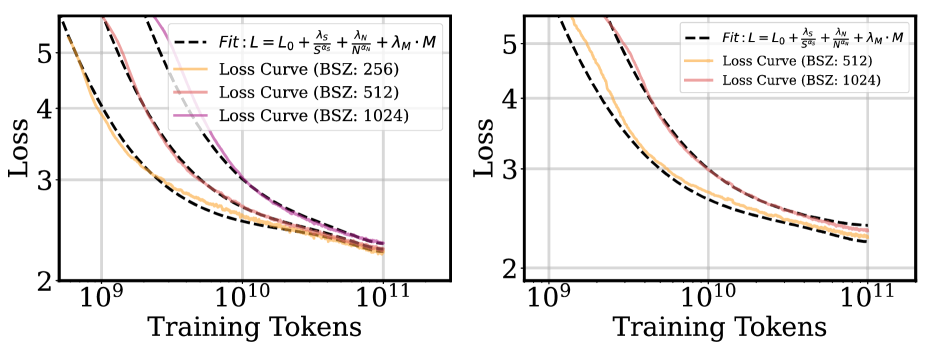
核心思路:论文的核心思路是发现并利用学习率退火动态在不同模型配置之间的可迁移性。通过分析Warmup-Steady-Decay (WSD)调度器下的退火行为,建立一个广义的预测框架,该框架能够根据训练步数、最大学习率等参数预测最优的退火策略。核心假设是最优退火比率在不同模型配置下遵循一致的模式。
技术框架:论文提出的框架主要包含以下几个阶段:1) 数据收集:通过对不同模型配置进行训练,收集学习率退火过程中的相关数据,包括训练步数、学习率变化等。2) 特征提取:从收集到的数据中提取关键特征,如最大学习率、退火起始点、退火结束点等。3) 模型训练:使用提取的特征训练一个预测模型,该模型能够预测给定模型配置下的最优退火策略。4) 策略迁移:将训练好的预测模型应用于新的模型配置,预测其最优退火策略。
关键创新:论文的关键创新在于发现了学习率退火动态的可迁移性,并提出了一个能够有效利用这种可迁移性的广义预测框架。与现有方法相比,该框架能够显著减少超参数搜索的成本,提高大模型的训练效率。此外,论文还证明了小模型可以作为优化大模型训练动态的可靠代理,进一步降低了实验成本。
关键设计:论文的关键设计包括:1) 使用Warmup-Steady-Decay (WSD)调度器作为基础学习率调度策略。2) 改进了预测框架,使其能够结合训练步数、最大学习率和退火行为。3) 通过大量实验验证了最优退火比率在不同模型配置下的稳定性和可迁移性。4) 探索了小模型作为大模型训练代理的可行性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,论文提出的方法能够有效地预测和迁移学习率退火策略,显著减少了超参数搜索的成本。通过在Dense和MoE模型上的验证,证明了最优退火比率遵循一致的模式,并且可以在不同的训练配置之间迁移。小模型可以作为大模型的训练代理,进一步降低了实验成本。
🎯 应用场景
该研究成果可广泛应用于大语言模型的预训练和微调阶段,加速模型开发流程,降低训练成本。通过迁移学习率退火策略,可以快速适配不同规模、不同架构的模型,提升模型性能。此外,该方法还可应用于其他深度学习模型的训练优化,具有一定的通用性。
📄 摘要(原文)
Learning rate scheduling is crucial for training large language models, yet understanding the optimal annealing strategies across different model configurations remains challenging. In this work, we investigate the transferability of annealing dynamics in large language model training and refine a generalized predictive framework for optimizing annealing strategies under the Warmup-Steady-Decay (WSD) scheduler. Our improved framework incorporates training steps, maximum learning rate, and annealing behavior, enabling more efficient optimization of learning rate schedules. Our work provides a practical guidance for selecting optimal annealing strategies without exhaustive hyperparameter searches, demonstrating that smaller models can serve as reliable proxies for optimizing the training dynamics of larger models. We validate our findings on extensive experiments using both Dense and Mixture-of-Experts (MoE) models, demonstrating that optimal annealing ratios follow consistent patterns and can be transferred across different training configurations.