Quantifying Memory Use in Reinforcement Learning with Temporal Range
作者: Rodney Lafuente-Mercado, Daniela Rus, T. Konstantin Rusch
分类: cs.LG, cs.AI
发布日期: 2025-12-05
💡 一句话要点
提出Temporal Range指标,量化强化学习策略对历史观测的记忆依赖。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 记忆依赖 时间范围 自动微分 策略评估
📋 核心要点
- 现有强化学习方法缺乏有效手段来量化策略对历史信息的依赖程度,难以评估策略的记忆使用效率。
- 提出Temporal Range指标,通过计算输出对输入的敏感度来衡量策略在时间维度上的依赖关系,从而量化记忆使用。
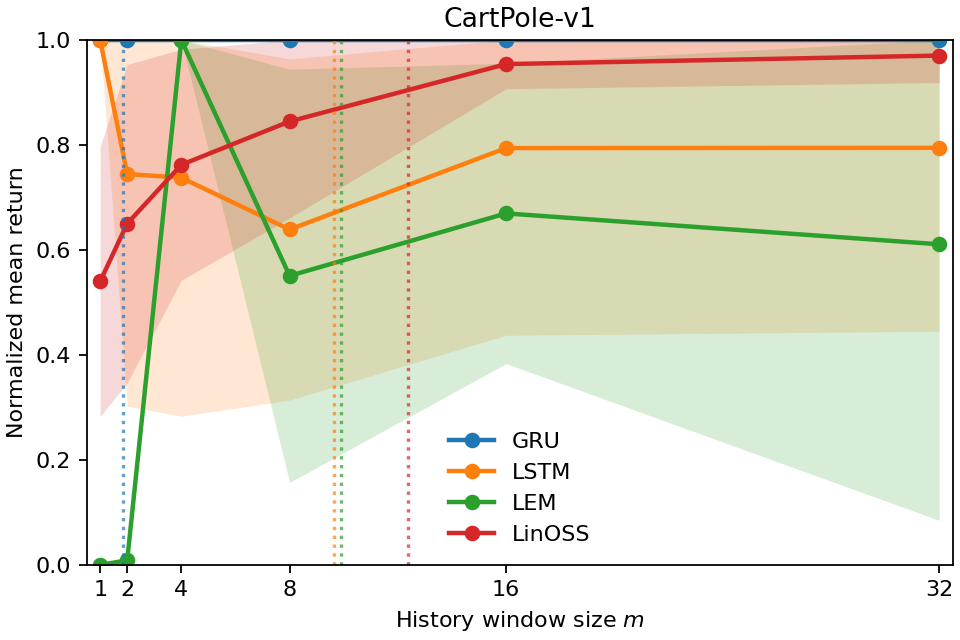
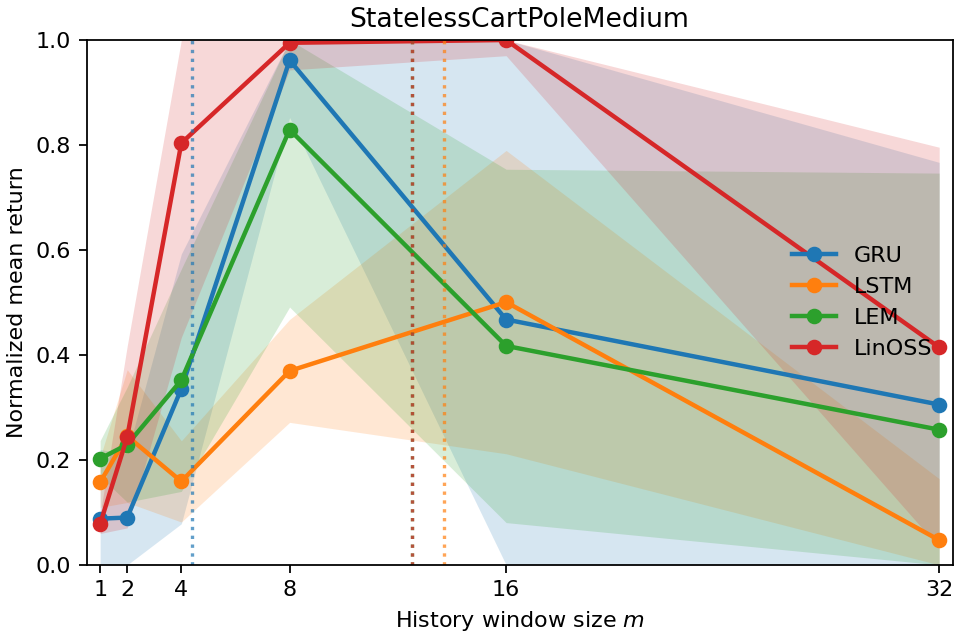
- 实验表明Temporal Range与任务的真实滞后相关,并能反映策略所需的最小历史窗口,可用于比较不同策略和环境。
📝 摘要(中文)
本文提出了一种模型无关的指标——Temporal Range,用于量化已训练的强化学习策略实际使用了多少历史观测信息。Temporal Range将时间窗口内多个向量输出对输入序列的一阶敏感度视为时间影响剖面,并通过幅度加权平均滞后对其进行概括。该指标通过反向模式自动微分计算得到,利用雅可比矩阵块 ∂y_s/∂x_t,在最终时间步 s∈{t+1,…,T} 上取平均。在线性环境中,Temporal Range具有良好的特性,满足一组自然公理。在诊断和控制任务(POPGym;闪烁/遮挡;Copy-k)以及不同架构(MLP、RNN、SSM)上,Temporal Range在完全可观测控制中保持较小,在Copy-k任务中随真实滞后而缩放,并与近乎最优回报所需的最小历史窗口对齐。此外,本文还报告了在Copy-k任务上训练的紧凑型长程表达记忆(LEM)策略的Temporal Range,将其作为任务级记忆的代理读数。该公理化处理借鉴了范围度量的最新研究,并将其专门应用于时间滞后,并扩展到强化学习环境中的向量值输出。Temporal Range为比较智能体和环境以及选择最短的充分上下文提供了一种实用的、基于序列的记忆依赖读数。
🔬 方法详解
问题定义:强化学习策略在决策过程中,对历史观测的依赖程度难以量化。现有方法缺乏一种通用的、模型无关的指标来评估策略的记忆使用效率,这限制了我们对策略行为的理解和优化。特别是在部分可观测环境中,策略需要利用历史信息来推断当前状态,但如何确定策略实际使用了多少历史信息仍然是一个挑战。
核心思路:本文的核心思路是将策略的输出对输入的敏感度作为衡量记忆使用的指标。具体来说,如果策略的输出对过去某个时间点的输入非常敏感,则说明策略依赖于该时间点的信息。通过计算这种敏感度在时间维度上的分布,可以得到一个时间影响剖面,从而量化策略的记忆使用。这种方法是模型无关的,可以应用于各种不同的策略架构。
技术框架:Temporal Range的计算流程如下:1. 给定一个强化学习策略和一个输入序列。2. 计算策略在每个时间步的输出。3. 使用反向模式自动微分计算输出对输入的雅可比矩阵块 ∂y_s/∂x_t,其中 s∈{t+1,…,T}。4. 对雅可比矩阵块在最终时间步上取平均。5. 将平均后的雅可比矩阵块视为时间影响剖面。6. 通过幅度加权平均滞后对时间影响剖面进行概括,得到Temporal Range。
关键创新:Temporal Range的关键创新在于它提供了一种模型无关的、基于敏感度的记忆使用量化方法。与现有方法相比,Temporal Range不需要对策略的内部状态进行分析,而是直接从输入输出关系入手,从而具有更强的通用性。此外,Temporal Range还具有良好的理论性质,满足一组自然公理,这使得它成为一种可靠的记忆使用指标。
关键设计:Temporal Range的关键设计包括:1. 使用反向模式自动微分计算雅可比矩阵块,这使得计算效率更高。2. 对雅可比矩阵块在最终时间步上取平均,这可以减少噪声的影响。3. 使用幅度加权平均滞后对时间影响剖面进行概括,这可以更好地反映策略的记忆使用情况。此外,论文还对Temporal Range进行了公理化分析,证明了它满足一组自然公理。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Temporal Range在完全可观测控制任务中保持较小,在Copy-k任务中随真实滞后而缩放,并与近乎最优回报所需的最小历史窗口对齐。此外,对长程表达记忆(LEM)策略的Temporal Range分析表明,该指标可以作为任务级记忆的代理读数。这些结果验证了Temporal Range作为记忆使用指标的有效性。
🎯 应用场景
Temporal Range可用于比较不同强化学习智能体和环境的记忆依赖性,帮助选择最短的充分上下文,提升强化学习算法的效率和可解释性。该指标还可应用于策略蒸馏,将复杂策略的记忆使用模式迁移到更简单的策略中。此外,Temporal Range还可用于诊断强化学习策略的故障,例如,如果策略的Temporal Range与任务的真实滞后不匹配,则可能表明策略存在问题。
📄 摘要(原文)
How much does a trained RL policy actually use its past observations? We propose \emph{Temporal Range}, a model-agnostic metric that treats first-order sensitivities of multiple vector outputs across a temporal window to the input sequence as a temporal influence profile and summarizes it by the magnitude-weighted average lag. Temporal Range is computed via reverse-mode automatic differentiation from the Jacobian blocks $\partial y_s/\partial x_t\in\mathbb{R}^{c\times d}$ averaged over final timesteps $s\in{t+1,\dots,T}$ and is well-characterized in the linear setting by a small set of natural axioms. Across diagnostic and control tasks (POPGym; flicker/occlusion; Copy-$k$) and architectures (MLPs, RNNs, SSMs), Temporal Range (i) remains small in fully observed control, (ii) scales with the task's ground-truth lag in Copy-$k$, and (iii) aligns with the minimum history window required for near-optimal return as confirmed by window ablations. We also report Temporal Range for a compact Long Expressive Memory (LEM) policy trained on the task, using it as a proxy readout of task-level memory. Our axiomatic treatment draws on recent work on range measures, specialized here to temporal lag and extended to vector-valued outputs in the RL setting. Temporal Range thus offers a practical per-sequence readout of memory dependence for comparing agents and environments and for selecting the shortest sufficient context.