Impugan: Learning Conditional Generative Models for Robust Data Imputation
作者: Zalish Mahmud, Anantaa Kotal, Aritran Piplai
分类: cs.LG, cs.AI
发布日期: 2025-12-05
💡 一句话要点
Impugan:一种用于鲁棒数据插补的条件生成对抗网络模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据插补 生成对抗网络 条件GAN 异构数据集成 缺失值处理
📋 核心要点
- 现实世界数据常因各种原因不完整,传统插补方法依赖强假设,难以处理复杂异构数据。
- Impugan利用条件生成对抗网络,通过对抗训练学习缺失变量与观测变量间的非线性关系。
- 实验表明,Impugan在数据插补和异构数据集成任务上,显著优于现有方法,降低了EMD和MI偏差。
📝 摘要(中文)
现实应用中数据不完整的情况普遍存在。传感器故障、记录不一致以及从不同来源收集的数据集在规模、采样率和质量上常常存在差异。这些差异导致缺失值,使得组合数据和构建可靠模型变得困难。诸如回归模型、期望最大化和多重插补等标准插补方法依赖于关于线性和独立性的强假设。这些假设很少适用于复杂或异构数据,可能导致有偏差或过度平滑的估计。我们提出了Impugan,一种用于插补缺失值和整合异构数据集的条件生成对抗网络(cGAN)。该模型在完整样本上进行训练,以学习缺失变量如何依赖于观察到的变量。在推理过程中,生成器从可用特征重建缺失条目,判别器通过区分真实数据和插补数据来强制执行真实性。这种对抗过程允许Impugan捕获传统方法无法表示的非线性和多模态关系。在基准数据集和多源集成任务上的实验表明,与领先的基线相比,Impugan实现了高达82%的Earth Mover距离(EMD)降低和70%的互信息偏差(MI)降低。这些结果表明,对抗训练的生成模型为插补和合并不完整、异构数据提供了一种可扩展且有原则的方法。
🔬 方法详解
问题定义:论文旨在解决现实世界中普遍存在的不完整数据插补问题,尤其关注传统方法在处理复杂异构数据时,由于强线性假设和独立性假设而导致的偏差和过度平滑问题。现有方法难以捕捉数据间的非线性关系和多模态分布,限制了数据集成和模型构建的可靠性。
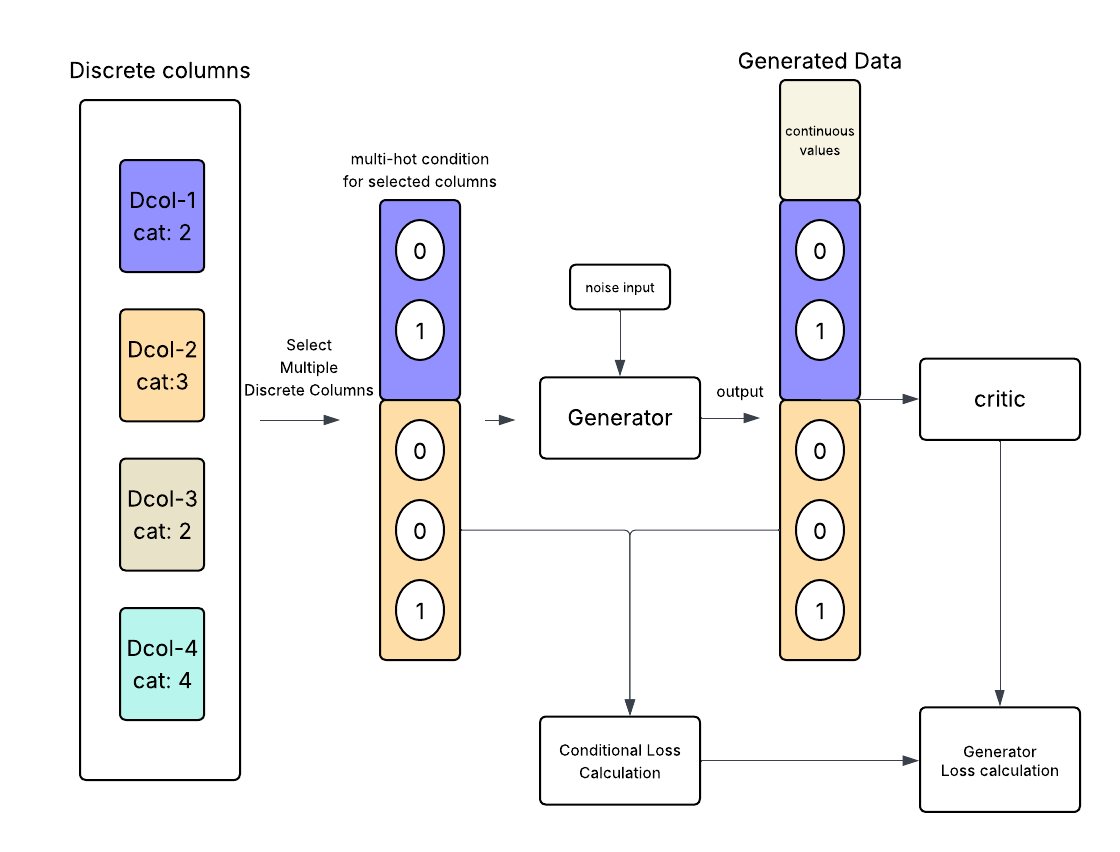
核心思路:论文的核心思路是利用条件生成对抗网络(cGAN)学习缺失变量与观测变量之间的复杂依赖关系。生成器负责根据观测数据重建缺失值,判别器则负责区分生成的数据和真实数据,从而迫使生成器生成更真实、更符合数据分布的插补值。这种对抗训练的方式能够捕捉非线性和多模态关系,避免了传统方法的强假设。
技术框架:Impugan的整体框架是一个标准的cGAN结构,包含一个生成器G和一个判别器D。生成器G以观测到的数据为条件输入,生成缺失值的插补结果。判别器D接收真实数据或包含插补值的数据,判断其真伪。G和D通过对抗训练不断优化,最终使得G能够生成逼真的插补数据。训练完成后,仅使用生成器G进行缺失值插补。
关键创新:Impugan的关键创新在于将cGAN应用于数据插补任务,并利用对抗训练学习数据间的复杂依赖关系。与传统方法相比,Impugan无需对数据分布进行强假设,能够更好地处理复杂异构数据。此外,对抗训练机制能够生成更真实、更符合数据分布的插补值,从而提高数据插补的质量。
关键设计:生成器和判别器的具体网络结构未知,论文中可能未详细描述。损失函数采用标准的GAN损失函数,即生成器试图欺骗判别器,判别器试图区分真假数据。具体的参数设置和训练策略未知,需要在论文原文或代码中查找。
🖼️ 关键图片
📊 实验亮点
Impugan在基准数据集和多源集成任务上取得了显著的性能提升。与领先的基线方法相比,Impugan实现了高达82%的Earth Mover距离(EMD)降低和70%的互信息偏差(MI)降低。这些结果表明,Impugan能够更准确地捕捉数据间的复杂关系,生成更真实的插补值,从而显著提高数据插补的质量。
🎯 应用场景
Impugan可应用于各种数据集成和数据清洗场景,例如传感器数据融合、医疗记录补全、金融数据整合等。通过更准确地插补缺失值,Impugan能够提高数据质量,提升下游任务的性能,例如预测模型的准确性和数据分析的可靠性。该研究对于解决现实世界中普遍存在的数据不完整问题具有重要意义。
📄 摘要(原文)
Incomplete data are common in real-world applications. Sensors fail, records are inconsistent, and datasets collected from different sources often differ in scale, sampling rate, and quality. These differences create missing values that make it difficult to combine data and build reliable models. Standard imputation methods such as regression models, expectation-maximization, and multiple imputation rely on strong assumptions about linearity and independence. These assumptions rarely hold for complex or heterogeneous data, which can lead to biased or over-smoothed estimates. We propose Impugan, a conditional Generative Adversarial Network (cGAN) for imputing missing values and integrating heterogeneous datasets. The model is trained on complete samples to learn how missing variables depend on observed ones. During inference, the generator reconstructs missing entries from available features, and the discriminator enforces realism by distinguishing true from imputed data. This adversarial process allows Impugan to capture nonlinear and multimodal relationships that conventional methods cannot represent. In experiments on benchmark datasets and a multi-source integration task, Impugan achieves up to 82\% lower Earth Mover's Distance (EMD) and 70\% lower mutual-information deviation (MI) compared to leading baselines. These results show that adversarially trained generative models provide a scalable and principled approach for imputing and merging incomplete, heterogeneous data. Our model is available at: github.com/zalishmahmud/impuganBigData2025