Bootstrapping Fuzzers for Compilers of Low-Resource Language Dialects Using Language Models
作者: Sairam Vaidya, Marcel Böhme, Loris D'Antoni
分类: cs.SE, cs.LG, cs.PL
发布日期: 2025-12-05
💡 一句话要点
Germinator利用语言模型为低资源语言编译器自动生成fuzzer,提升测试效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 编译器测试 模糊测试 语言模型 MLIR 领域特定语言 自动化测试 代码覆盖率
📋 核心要点
- 现有编译器测试方法在方言无关性和有效性之间难以兼顾,需要手动构建种子语料库或测试效果不佳。
- 论文提出Germinator,利用方言语法和预训练语言模型自动生成种子输入,引导覆盖引导的模糊测试。
- 实验表明,Germinator显著提升了代码覆盖率,并发现了大量未知错误,尤其是在低资源方言中。
📝 摘要(中文)
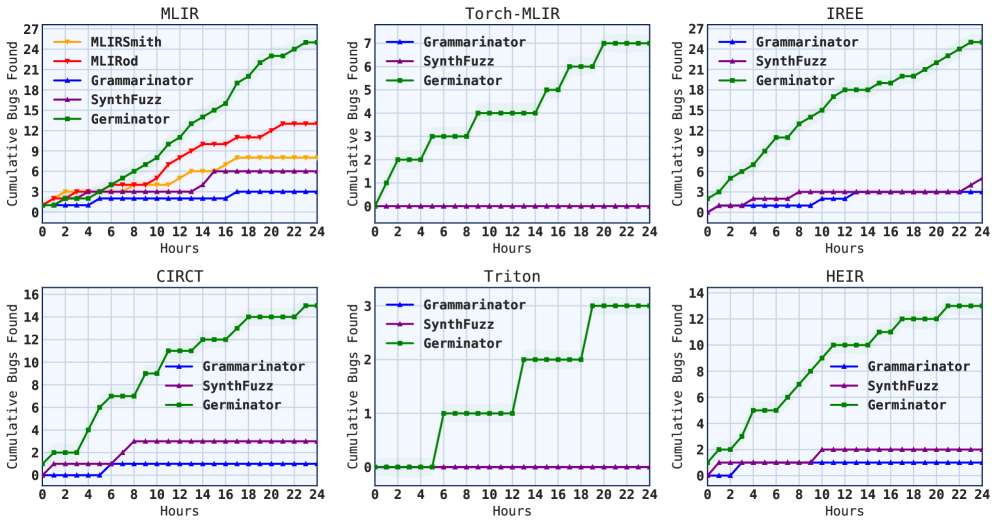
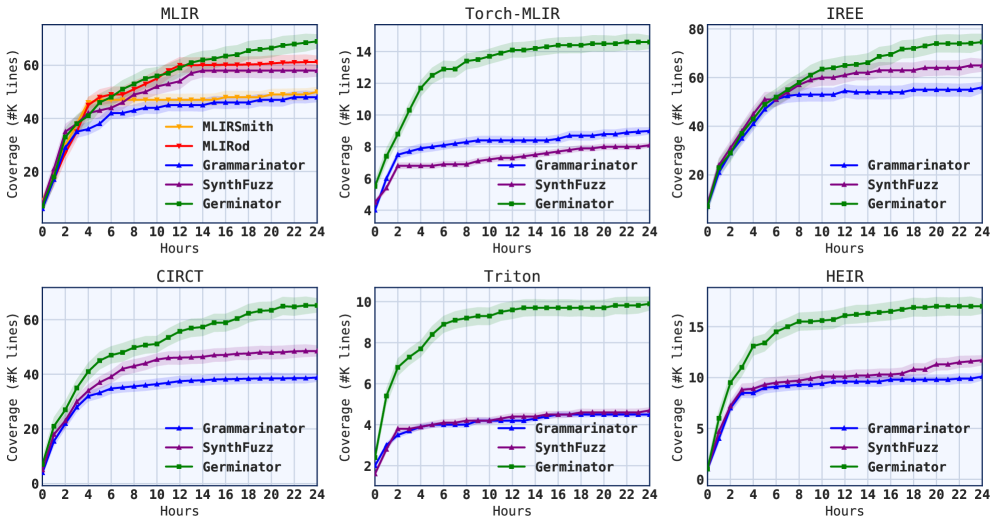
现代可扩展的编译器框架(如MLIR)能够快速创建特定领域的语言方言。然而,这种灵活性使得正确性难以保证,因为加速开发的可扩展性也使得维护测试基础设施变得复杂。可扩展语言需要自动测试生成,既要与方言无关(无需手动调整即可跨方言工作),又要对方言有效(针对方言特定功能以发现错误)。现有方法通常牺牲其中一个目标,要么需要为每个方言手动构建种子语料库,要么无法有效。我们提出了一种与方言无关且对方言有效的基于语法的覆盖引导模糊测试方法,用于可扩展编译器,该方法结合了现有工作的两个关键见解:(i)方言的语法(已经编码了结构和类型约束)通常可以从方言规范中自动提取;(ii)这些语法可以与预训练的大型语言模型结合使用,以自动生成来自完整方言空间的代表性和多样化的种子输入,而无需任何手动输入或训练数据。然后,这些种子可用于引导覆盖引导的fuzzer。我们将此方法构建到工具Germinator中。在对跨越91个方言的六个MLIR项目进行评估时,Germinator生成的种子比基于语法的基线提高了10-120%的行覆盖率。我们与基于语法的基线进行比较,因为它们是唯一一类可以统一应用于MLIR异构方言生态系统的现有自动种子生成器。Germinator发现了88个以前未知的错误(40个已确认),其中包括23个在没有先前自动测试生成器的方言中,证明了对低资源方言进行有效且可控的大规模测试。
🔬 方法详解
问题定义:现有编译器测试方法,特别是针对MLIR等可扩展编译器框架下的领域特定语言(DSL)方言,面临着测试用例生成效率和有效性的挑战。手动构建测试用例成本高昂,且难以覆盖所有可能的代码路径。现有的自动测试生成方法要么需要为每个方言手动构建种子语料库,要么无法有效地针对方言的特定功能进行测试,导致测试效果不佳。
核心思路:论文的核心思路是结合方言的语法结构和预训练语言模型的能力,自动生成高质量的种子输入,从而引导覆盖引导的模糊测试。通过自动提取方言的语法规范,并利用语言模型生成符合语法规则且具有多样性的输入,可以有效地探索代码空间,发现潜在的错误。
技术框架:Germinator的整体框架包含以下几个主要阶段:1) 语法提取:自动从方言规范中提取语法规则。2) 种子生成:利用预训练的语言模型,根据提取的语法规则生成初始的种子输入。3) 模糊测试:使用生成的种子输入引导覆盖引导的模糊测试,不断变异和优化输入,以最大化代码覆盖率并发现错误。4) 错误报告:对发现的错误进行分类和报告。
关键创新:论文的关键创新在于将预训练语言模型引入到编译器模糊测试中,利用语言模型生成高质量的种子输入。与传统的基于语法的模糊测试方法相比,Germinator能够生成更具代表性和多样性的输入,从而更有效地探索代码空间。此外,Germinator的方法是与方言无关的,可以应用于不同的MLIR方言,无需手动调整。
关键设计:Germinator的关键设计包括:1) 语法提取策略:如何有效地从方言规范中提取语法规则。2) 语言模型选择和微调:选择合适的预训练语言模型,并根据方言的特点进行微调,以提高生成输入的质量。3) 模糊测试策略:选择合适的模糊测试算法,并根据代码覆盖率和错误发现率进行优化。4) 种子选择策略:如何选择最具代表性的种子输入,以引导模糊测试。
🖼️ 关键图片
📊 实验亮点
Germinator在六个MLIR项目(91个方言)上的评估显示,其生成的种子输入比基于语法的基线方法提高了10-120%的行覆盖率。此外,Germinator发现了88个以前未知的错误(40个已确认),其中包括23个在没有先前自动测试生成器的方言中,证明了其在低资源方言测试方面的有效性。
🎯 应用场景
该研究成果可广泛应用于编译器测试、软件安全和程序分析等领域。通过自动生成高质量的测试用例,可以有效地提高编译器的可靠性和安全性,减少软件漏洞。此外,该方法还可以应用于其他可扩展的软件系统,例如数据库系统和操作系统。
📄 摘要(原文)
Modern extensible compiler frameworks-such as MLIR-enable rapid creation of domain-specific language dialects. This flexibility, however, makes correctness harder to ensure as the same extensibility that accelerates development also complicates maintaining the testing infrastructure. Extensible languages require automated test generation that is both dialect-agnostic (works across dialects without manual adaptation) and dialect-effective (targets dialect-specific features to find bugs). Existing approaches typically sacrifice one of these goals by either requiring manually constructed seed corpora for each dialect, or by failing to be effective. We present a dialect-agnostic and dialect-effective grammar-based and coverage-guided fuzzing approach for extensible compilers that combines two key insights from existing work: (i) the grammars of dialects, which already encode the structural and type constraints, can often be extracted automatically from the dialect specification; and (ii) these grammars can be used in combination with pre-trained large language models to automatically generate representative and diverse seed inputs from the full dialect space without requiring any manual input or training data. These seeds can then be used to bootstrap coverage-guided fuzzers. We built this approach into a tool, Germinator. When evaluated on six MLIR projects spanning 91 dialects, Germinator generated seeds improve line coverage by 10-120% over grammar-based baselines. We compare against grammar-based baselines because they are the only class of existing automatic seed generators that can be applied uniformly across MLIR's heterogeneous dialect ecosystem. Germinator discovers 88 previously unknown bugs (40 confirmed), including 23 in dialects with no prior automated test generators, demonstrating effective and controllable testing of low-resource dialects at scale.