Utility Boundary of Dataset Distillation: Scaling and Configuration-Coverage Laws
作者: Zhengquan Luo, Zhiqiang Xu
分类: cs.LG
发布日期: 2025-12-05 (更新: 2025-12-10)
💡 一句话要点
提出配置-动态-误差分析框架,揭示数据集蒸馏的缩放律和配置覆盖律。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 泛化误差 缩放律 配置覆盖律 理论分析 机器学习 模型压缩 合成数据
📋 核心要点
- 现有数据集蒸馏方法依赖异构的替代目标和优化假设,缺乏统一的理论框架和泛化保证。
- 论文提出配置-动态-误差分析框架,从泛化误差角度统一分析数据集蒸馏方法,揭示其内在原理。
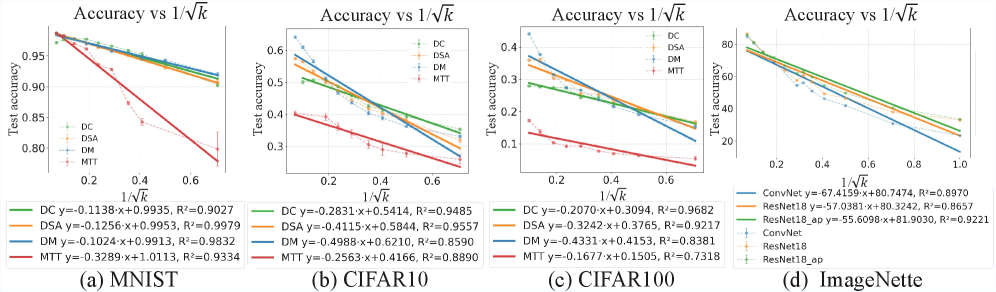
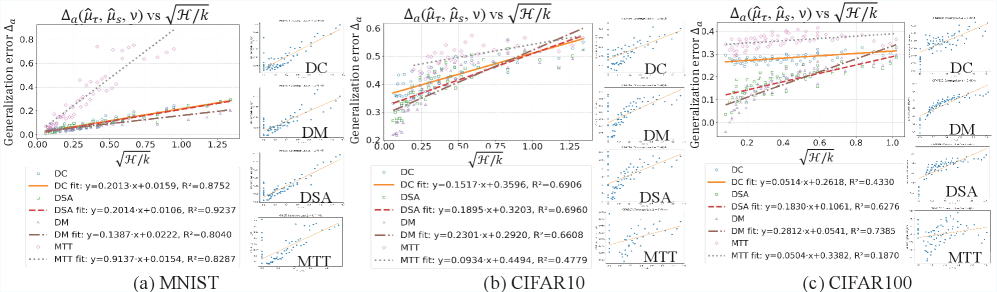
- 理论推导了缩放律和配置覆盖律,并通过实验验证了这些定律,为数据集蒸馏提供了理论指导。
📝 摘要(中文)
数据集蒸馏(DD)旨在构建紧凑的合成数据集,使模型在显著减少存储和计算的同时,达到与全数据训练相当的性能。尽管经验上取得了快速进展,但其理论基础仍然有限:现有方法(梯度、分布、轨迹匹配)建立在异构的替代目标和优化假设之上,这使得分析它们的共同原理或提供一般保证变得困难。此外,当训练配置(如优化器、架构或增强)发生变化时,蒸馏数据在何种条件下能够保持全数据集的有效性仍不清楚。为了回答这些问题,我们提出了一个统一的理论框架,称为配置-动态-误差分析,它在共同的泛化误差视角下重新构建了主要的DD方法,并提供了两个主要结果:(i)一个缩放律,提供了一个单配置上限,描述了误差如何随着蒸馏样本大小的增加而减少,并解释了常见的性能饱和效应;(ii)一个覆盖律,表明所需的蒸馏样本大小与配置多样性呈线性关系,并具有可证明匹配的上下界。此外,我们的统一分析表明,各种匹配方法是可以互换的替代方法,减少了相同的泛化误差,阐明了为什么它们都可以实现数据集蒸馏,并为替代选择如何影响样本效率和鲁棒性提供了指导。跨多种方法和配置的实验经验性地证实了导出的定律,从而为DD奠定了理论基础,并实现了理论驱动的紧凑、配置鲁棒的数据集蒸馏设计。
🔬 方法详解
问题定义:数据集蒸馏旨在用远小于原始数据集的合成数据集训练模型,使其性能接近在原始数据集上训练的模型。现有方法如梯度匹配、分布匹配等,缺乏统一的理论框架,难以分析其内在联系和泛化能力,并且在训练配置变化时,蒸馏数据集的有效性难以保证。
核心思路:论文的核心思路是将不同的数据集蒸馏方法统一到泛化误差最小化的框架下进行分析。通过分析训练配置、模型动态和泛化误差之间的关系,推导出数据集蒸馏的缩放律和配置覆盖律。这种统一的视角有助于理解不同蒸馏方法的本质,并指导更有效的蒸馏算法设计。
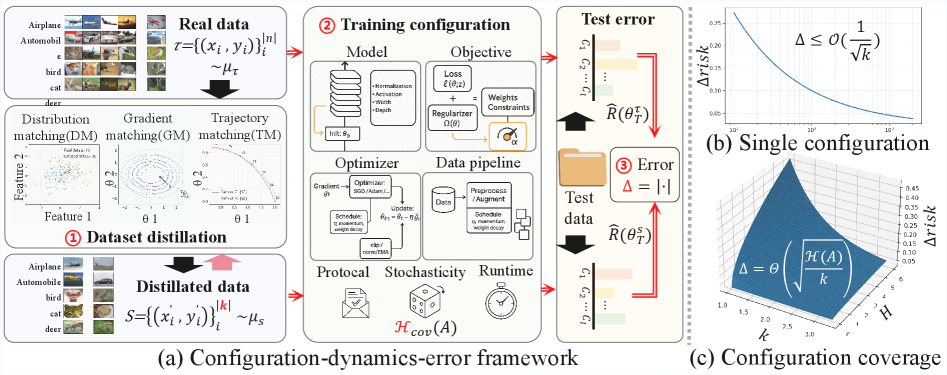
技术框架:论文提出的配置-动态-误差分析框架包含以下几个关键部分: 1. 配置空间:定义训练配置,包括优化器、网络结构、数据增强等。 2. 模型动态:描述模型在给定配置下的训练过程,例如参数更新轨迹。 3. 泛化误差:衡量模型在测试集上的性能。 该框架通过分析配置空间、模型动态和泛化误差之间的关系,推导出数据集蒸馏的理论性质。
关键创新:论文的关键创新在于提出了一个统一的理论框架,将不同的数据集蒸馏方法纳入其中,并揭示了数据集蒸馏的缩放律和配置覆盖律。缩放律描述了蒸馏数据集大小与模型性能之间的关系,配置覆盖律描述了蒸馏数据集大小与训练配置多样性之间的关系。这些定律为数据集蒸馏的理论研究提供了重要的指导。与现有方法相比,该框架不仅提供了更强的理论保证,而且能够指导更有效的蒸馏算法设计。
关键设计:论文的关键设计包括: 1. 泛化误差分解:将泛化误差分解为配置误差和动态误差,分别衡量配置选择和模型训练的影响。 2. 缩放律推导:基于泛化误差分解,推导出蒸馏数据集大小与模型性能之间的缩放关系。 3. 配置覆盖律推导:分析训练配置多样性对蒸馏数据集大小的影响,推导出配置覆盖律。 论文还分析了不同匹配方法(如梯度匹配、分布匹配)之间的关系,证明它们是可互换的替代方法,都旨在减少相同的泛化误差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的缩放律和配置覆盖律能够准确预测数据集蒸馏的性能。具体来说,实验验证了蒸馏数据集大小与模型性能之间的缩放关系,以及蒸馏数据集大小与训练配置多样性之间的线性关系。这些实验结果为数据集蒸馏的理论研究提供了有力的支持。
🎯 应用场景
该研究成果可应用于资源受限的场景,例如移动设备或边缘计算,通过数据集蒸馏减少存储和计算开销。此外,该理论框架有助于设计更鲁棒的数据集蒸馏算法,使其在不同的训练配置下都能保持良好的性能。未来,该研究可以扩展到更复杂的数据集和模型,并应用于迁移学习和联邦学习等领域。
📄 摘要(原文)
Dataset distillation (DD) aims to construct compact synthetic datasets that allow models to achieve comparable performance to full-data training while substantially reducing storage and computation. Despite rapid empirical progress, its theoretical foundations remain limited: existing methods (gradient, distribution, trajectory matching) are built on heterogeneous surrogate objectives and optimization assumptions, which makes it difficult to analyze their common principles or provide general guarantees. Moreover, it is still unclear under what conditions distilled data can retain the effectiveness of full datasets when the training configuration, such as optimizer, architecture, or augmentation, changes. To answer these questions, we propose a unified theoretical framework, termed configuration--dynamics--error analysis, which reformulates major DD approaches under a common generalization-error perspective and provides two main results: (i) a scaling law that provides a single-configuration upper bound, characterizing how the error decreases as the distilled sample size increases and explaining the commonly observed performance saturation effect; and (ii) a coverage law showing that the required distilled sample size scales linearly with configuration diversity, with provably matching upper and lower bounds. In addition, our unified analysis reveals that various matching methods are interchangeable surrogates, reducing the same generalization error, clarifying why they can all achieve dataset distillation and providing guidance on how surrogate choices affect sample efficiency and robustness. Experiments across diverse methods and configurations empirically confirm the derived laws, advancing a theoretical foundation for DD and enabling theory-driven design of compact, configuration-robust dataset distillation.